Homayoon Beigi, Professor of Professional Practice of Columbia’s Departments of Electrical Engineering and Mechanical Engineering, has introduced EfficientPunct, a lightweight yet powerful deep learning model that restores punctuation in automatic speech recognition (ASR) outputs — the kind of text generated when machines transcribe spoken language.
Published in the journal Electronics as part of a special issue on “Future Technologies for Data Management, Processing and Application,” Beigi’s work presents a new state of the art in the field. Compared to previous systems, EfficientPunct uses a fraction of the computing power — less than 10% of the parameters — while improving accuracy by 1.0 F1 score, a common benchmark for evaluating machine learning models.
Going Beyond TED Talks
Most punctuation models are trained on scripted, structured content like TED talks. But real-world conversations — full of stutters, pauses, and slang — don’t follow a script. To address this, Beigi and co-author Xing Yi Liu from the University of Waterloo created SponSpeech, a new open-source dataset made up of more than 600 hours of spontaneous, informal speech. Unlike existing datasets, SponSpeech features unscripted dialogue pulled from podcasts and other casual audio sources.
The dataset, which is free for researchers under a Creative Commons license, includes a unique “ambiguous punctuation” test set to evaluate how well models can handle tricky cases — such as whether the sentence “I have eight boys” should be interpreted as a count or a call to a group.
A Multimodal Advantage
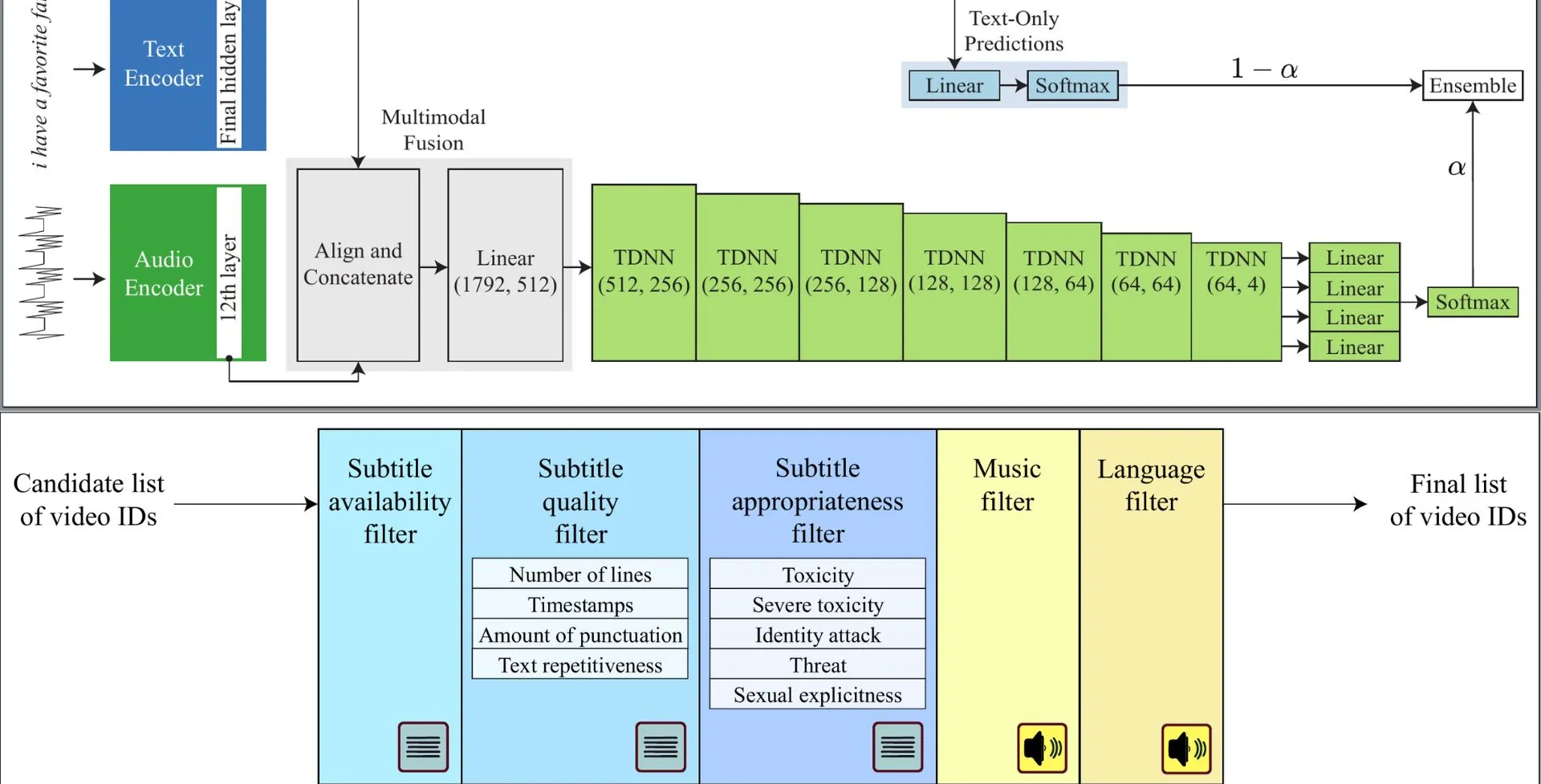
EfficientPunct doesn’t just rely on text. It also incorporates audio features — like pitch, pauses, and intonation — using a technique called forced alignment to match sound with corresponding words. This fusion of audio and text lets the model make better guesses about where punctuation belongs, especially in ambiguous situations like identifying questions or pauses for emphasis.
Rather than using heavy attention-based models common in today’s AI, EfficientPunct applies a simpler and faster time-delay neural network (TDNN), leading to significant gains in speed and efficiency. Beigi’s ensemble approach gives slightly more weight to language patterns learned from BERT, a widely used language model, while letting the TDNN refine the final punctuation decision using audio cues.
The result: a model that’s not only more accurate but also lean enough to run on limited hardware — making it ideal for real-time applications, even on mobile or edge devices.
Open Source for the Future
The research was invited and published open access by MDPI. The publisher also covered the publication fees.
Both the EfficientPunct code and SponSpeech dataset are publicly available, reflecting Beigi’s commitment to open science and real-world impact.