Grad students Hassan Akbari and Bahar Khalighinejad Were Featured in NVIDIA's Top 5 Stories of the Week
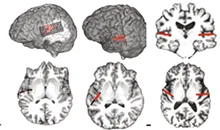
Researchers from Columbia University used deep learning to enhance speech neuroprothesis technologies, that can result in accurate and intelligible reconstructed speech from the human auditory cortex.
This research has the potential to one day help patients who have lost their ability to speak, communicate with their loved ones.
“Our approach takes a step toward the next generation of human-computer interaction systems and more natural communication channels for patients suffering from paralysis and locked-in syndromes,” the researchers stated in their paper.
The findings were published this week in Scientific Reports this week.
“Our voices help connect us to our friends, family and the world around us, which is why losing the power of one’s voice due to injury or disease is so devastating,” said Nima Mesgarani, the paper’s senior author and a principal investigator at Columbia University’s Mortimer B. Zuckerman Mind Brain Behavior Institute. “With today’s study, we have a potential way to restore [voice]. We’ve shown that, with the right technology, these people’s thoughts could be decoded and understood by any listener.”
Previous research has indicated that when people speak or imagine speaking, certain patterns, neural data, appear in their brain. Other patterns also emerge when we listen to or imagine someone speaking. Reconstructing speech from these neural responses, recorded from the human auditory cortex, could one day create a direct communication pathway to the brain.
This work was done In conjunction with a neurosurgeon from Northwell Health Physician Partners Neuroscience Institute. This collaboration allowed the collection of data from patients who were already undergoing brain surgery.
Using NVIDIA TITAN and NVIDIA Tesla GPUs, with the cuDNN-accelerated TensorFlow deep learning framework, the researchers were able to develop deep learning models that made possible the production of a computer-generated voice reciting a sequence of numbers with a 75% accuracy level.
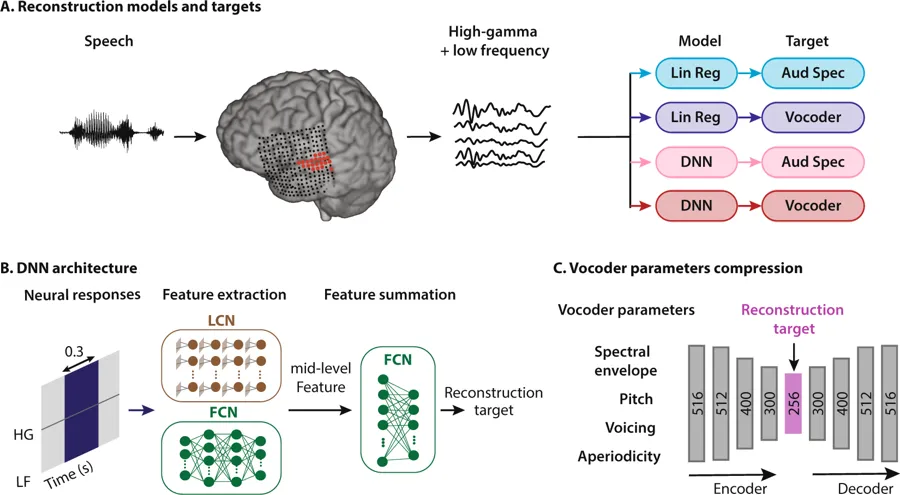
Schematic of the speech reconstruction method. (A) Subjects listened to natural speech sentences. The population of evoked neural activity in the auditory cortex of the listener was then used to reconstruct the speech stimulus. The responsive electrodes in an example subject are shown in red. High and low frequency bands were extracted from the neural data. Two types of regression models and two types of speech representations were used, resulting in four combinations: linear regression to auditory spectrogram (light blue), linear regression to vocoder (dark blue), DNN to auditory spectrogram, and DNN to vocoder (dark red). (B) The input to all models was a 300 ms sliding window containing both low frequency (LF) and the high-gamma envelope (HG). The DNN architecture consists of two modules: feature extraction and feature summation networks. Feature extraction for auditory spectrogram reconstruction was a fully connected neural network (FCN). For vocoder reconstruction, the feature extraction network consisted of an FCN concatenated with a locally connected network (LCN). The feature summation network is a two-layer fully connected neural network (FCN). (C) Vocoder parameters consist of spectral envelope, fundamental frequency (f0), voicing, and aperiodicity (total of 516 parameters). An autoencoder with a bottleneck layer was used to reduce the 516 vocoder parameters to 256. The bottleneck features were then used as the target of reconstruction algorithms. The vocoder parameters were calculated from the reconstructed bottleneck features using the decoder part of the autoencoder network. Source: Scientific Reports/Columbia University
Visit Nvidia Developer News Center to listen to an example of the computer generated sounds.
The paper is titled “Towards reconstructing intelligible speech from the human auditory cortex and the code for performing phoneme analysis, and reconstructing the auditory spectrogram are available on the researcher’s page.
Original article is here.
For additional information contact Eliese Lissner: [email protected]