
RESULTS & CONCLUSIONS
Results
The system demonstrates significant improvements in performance and efficiency when leveraging the FPGA and custom-designed NPU compared to standalone software or previous designs. The results are summarized below:
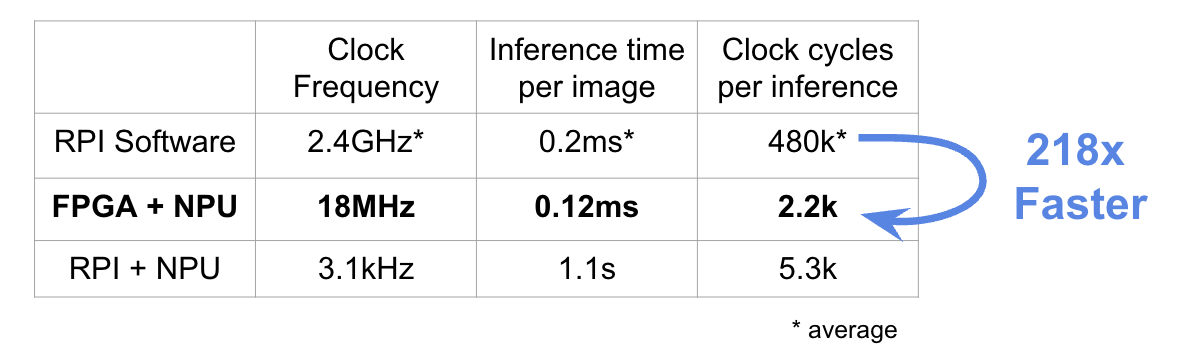
- Raspberry Pi Software: Running the CNN on the Raspberry Pi achieves an inference time of 0.2ms per image at a clock frequency of 2.4GHz. However, this approach requires a high number of clock cycles (480k per inference).
- FPGA + NPU: With a clock frequency of 18MHz, the FPGA and NPU achieve an inference time of 0.12ms per image, significantly reducing the required clock cycles to 2.2k per inference. This marks a dramatic improvement in hardware efficiency.
- Raspberry Pi + FPGA + NPU: Integrating the full system with the Raspberry Pi for preprocessing and FPGA-NPU for inference results in a complete workflow inference time of 1.1s per image.
Compared to the Raspberry Pi software implementation, the FPGA + NPU setup is 218x faster, demonstrating the significant impact of hardware acceleration in reducing computation time and resource usage.
Comparison with 2023
Compared to the previous year's design, the 2024 system introduces significant improvements in both processing speed and architectural efficiency. Key comparisons are summarized below:
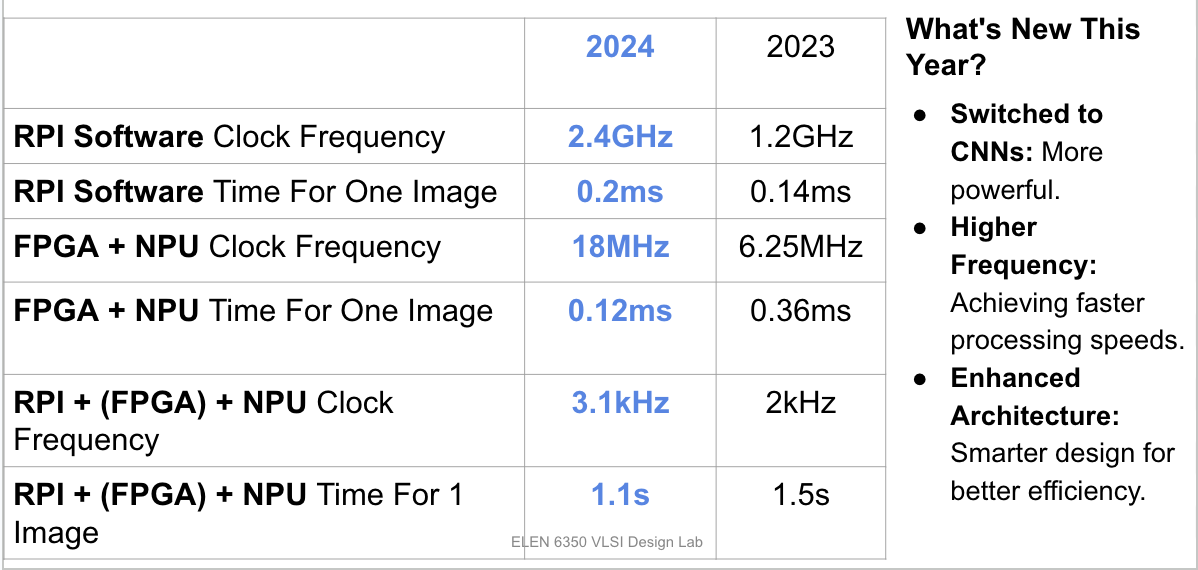
- Raspberry Pi Software: The 2024 system runs at a clock frequency of 2.4GHz, double that of the 2023 system (1.2GHz). The time to process one image increased slightly from 0.14ms in 2023 to 0.2ms this year due to additional preprocessing for compatibility with the hardware design.
- FPGA + NPU: The clock frequency increased significantly from 6.25MHz in 2023 to 18MHz in 2024, resulting in a much faster inference time. The time for one image dropped from 0.36ms to 0.12ms, demonstrating enhanced processing capabilities of the hardware accelerator.
- Raspberry Pi + FPGA + NPU: The complete system's clock frequency improved from 2kHz in 2023 to 3.1kHz in 2024, and the total inference time for one image decreased from 1.5s to 1.1s, achieving faster end-to-end performance.
These improvements reflect advancements in both hardware and system integration. By adopting CNNs, increasing operational frequency, and optimizing the architecture, the 2024 system sets a new benchmark in performance compared to last year's implementation.
Conclusions
This project showcases the power of custom hardware design in accelerating CNN inference for handwritten digit recognition. By transitioning to a CNN-based architecture, increasing operational frequency, and enhancing the system architecture, the current implementation surpasses previous designs in both speed and efficiency.
Key improvements this year include:
- Switched to CNNs: Transitioning to CNNs brought more robust and scalable processing capabilities.
- Higher Frequency: A significant boost in operational clock frequencies across both FPGA and Raspberry Pi components.
- Enhanced Architecture: Smarter design choices led to improved resource utilization and reduced inference time.
The combined improvements in architecture and hardware integration provide a strong foundation for further optimization and expansion, solidifying the project's potential for real-world AI applications.