
SOFTWARE IMPLEMENTATION
Convolutional Neural Networks (CNNs) typically consist of several key layers: convolutional layers, activation functions, pooling layers, and fully connected layers. These layers work together to extract features from input data and make accurate predictions.
Convolutional Layer
The convolutional layer is the core building block of a CNN. It applies a set of learnable filters to the input data to detect local patterns, such as edges, textures, or shapes. These filters slide over the input, producing feature maps that highlight specific characteristics of the data. By stacking multiple convolutional layers, the network learns increasingly complex patterns.
Activation Function
An activation function, such as ReLU (Rectified Linear Unit), introduces non-linearity into the network. Without this non-linearity, the network would behave like a linear model, unable to capture complex relationships in the data. ReLU is particularly effective for CNNs as it allows the network to focus on positive feature values while suppressing irrelevant or negative ones.
Pooling Layer
Pooling layers reduce the spatial dimensions of the feature maps, making the network more efficient and robust. Max pooling, used in our model, selects the maximum value from a group of neighboring pixels, preserving the most significant features while reducing computational overhead. Pooling also helps the network become more invariant to small shifts and distortions in the input data.
Fully Connected Layer
The fully connected layer combines the features extracted by the previous layers into a final representation for classification. It connects every neuron from the input to the output, allowing the network to map the extracted features to specific classes. In our case, the output layer consists of 10 neurons, corresponding to the 10 digit classes in the MNIST dataset.
Our CNN Structure
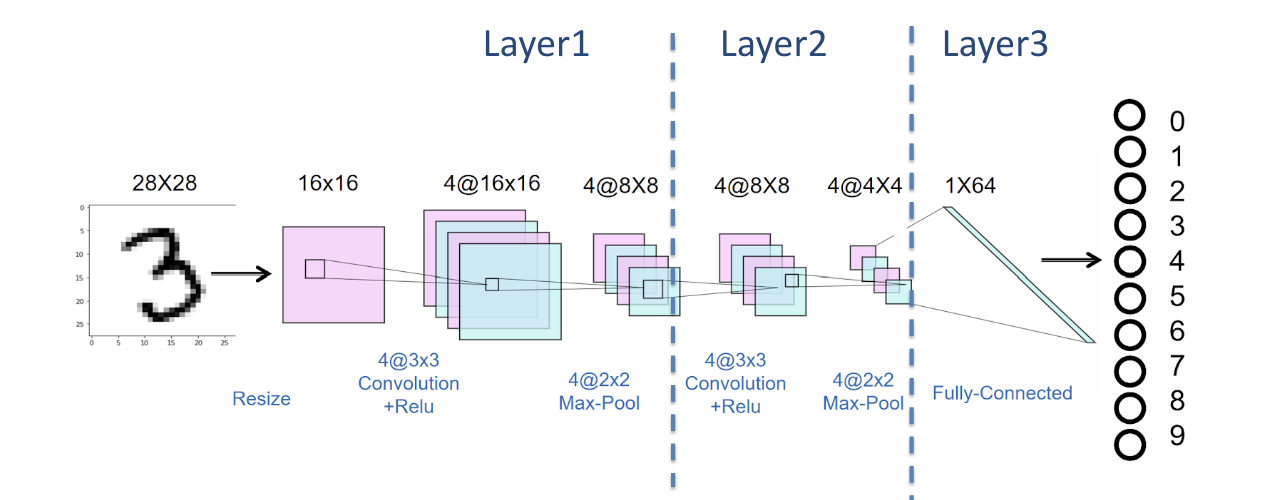
Our CNN is specifically designed for efficient and accurate classification of handwritten digits from the MNIST dataset.
The first layer of the CNN is a convolutional layer that takes in the grayscale input images with a single channel and applies four 3x3 filters. This layer captures basic spatial features such as edges and corners, which are essential for understanding the structure of the digits. The second convolutional layer builds on this foundation by applying eight 3x3 filters, allowing the network to learn more complex patterns and finer details in the images. Both convolutional layers include padding to maintain the spatial dimensions of the feature maps.
Each convolutional layer is followed by a ReLU (Rectified Linear Unit) activation function. ReLU introduces non-linearity into the model, enabling it to learn and model complex relationships in the data. The activated feature maps are then passed through a 2x2 max-pooling layer, which reduces their spatial dimensions by half. This pooling operation retains the most significant features while making the model more computationally efficient and robust to small variations in the input data.
After the feature extraction phase, the feature maps are flattened into a 1D vector, preparing them for the classification phase. The fully connected layer takes this flattened input and maps it to 10 output nodes, corresponding to the 10 digit classes (0–9). This layer integrates the features extracted by the convolutional and pooling layers, allowing the network to make accurate predictions based on the input images.
The simplicity and efficiency of this structure allow it to achieve an impressive 97% accuracy on the MNIST dataset. Its lightweight design, with only two convolutional layers, ensures fast inference while retaining the capacity to learn and classify effectively. This makes it an ideal choice for deployment in hardware accelerators or other resource-constrained environments.
Software code can be found at the following link: View Code