Hashing for Large-Scale Matching and Retrieval

Summary
We are developing new hashing methods to solve the problem of finding nearest neighbors in gigantic datasets. Such techniques are needed in many important applications, such as content-based retrieval and matching of images and videos, matching of visual features in high-dimensional spaces (e.g., SIFT), and other applications involving millions or billions of samples. In several solutions, we try to find the optimal projections for generating the binary hash bits. In others, we exploit the strategies like semi-supervised learning, graph-based manifold representation, query-dependent adaptation, or joint speed-accuracy optimization to significantly improve the hashing performance.
Recent Papers
- Jie Feng, Svebor Karaman, Shih-Fu Chang. Deep Image Set Hashing. In Applications of Computer Vision (WACV), 2017 IEEE Winter Conference on, 2017. [pdf]
- Jun Wang, Wei Liu, Sanjiv Kumar, Shih-Fu Chang. Learning to Hash for Indexing Big Data - A Survey. Proceedings of the IEEE, 104(1):34-57, 2016. [pdf]
- Felix Yu, Sanjiv Kumar, Yunchao Gong, Shih-Fu Chang. Circulant Binary Embedding. In International Conference on Machine Learning (ICML) (oral), June 2014. [pdf]
- Wei Liu, Cun Mu, Sanjiv Kumar, Shih-Fu Chang. Discrete Graph Hashing. In Advances in Neural Information Processing Systems (NIPS) (spotlight oral, 4.89% acceptance rate), 2014. [pdf]
- Wei Liu, Jun Wang, Rongrong Ji, Yu-Gang Jiang, Shih-Fu Chang. Supervised Hashing with Kernels. In IEEE International Conference on Computer Vision and Pattern Recognition (CVPR) (Oral session), 2012. [pdf]
- Jae-Pil Heo, YoungWoon Lee, Junfeng He, Shih-Fu Chang, Sung-eui Yoon. Spherical Hashing. In IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 2012. [pdf]
Semi-Supervised Hashing [1] - In this work, we develop a semi-supervised hashing method that minimizes empirical error on the labeled data while maximizing variance and independence of hash bits over the labeled and unlabeled data.
Sequential Projection Hashing [2] - In this paper, we develop a data-dependent projection learning method (similar to the concept of boosting) such that each hashing function is designed to correct the errors made by the previous one sequentially.
Optimized Kernel Hashing [3] - In this paper, we develop a new hashing algorithm to create efficient codes for large scale data of general formats with any kernel function, including kernels on vectors, graphs, sequences, sets
Query-Adaptive Hash-based Ranking [4] - One problem associated with hash-based ranking is the lacking of orders among images mapped to the same hash bin. In this paper, we develop an adaptive method that learns the optimal weights for each hash bit for a diverse set of predefined semantic concept classes. For a new query, adaptive weights are computed by evaluating the proximity between the query and the concept categories.
Hashing with Jointly Optimized Speed and Accuracy [5] - In this paper, we develop a new scalable hashing algorithm with joint optimization of search accuracy and search time simultaneously. Our method generates compact hash codes for data of general formats with any similarity function.
Hashing with Scalable Graphs [6] - Real-world datasets often reside on low-dimensional manifolds in high-dimensional spaces. In this paper, we use anchor graphs to represent the manifold structures in large-scale datasets. We develop graph-based hashing methods by computing the eigenvectors (and eigenfunctions) of graph Laplacian, without assuming restrictive probability distributions, and hierarchical hashing to address the rapid energy decay problem associated with typical spectral hashing approaches.
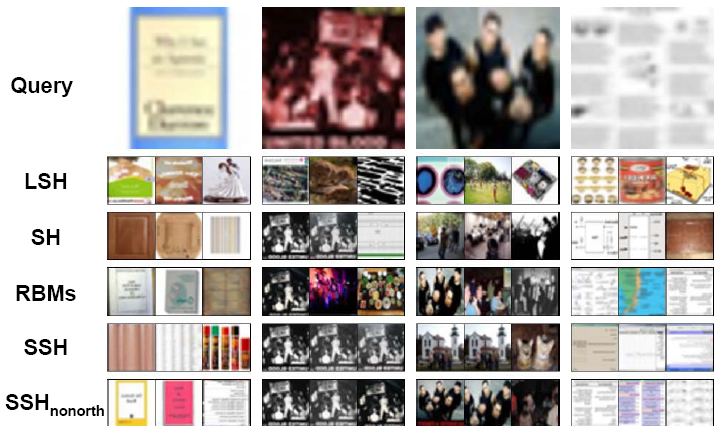
(Results of Semi-Supervised Hashing)

(Results of hashing with jointly optimized speed and accuracy)
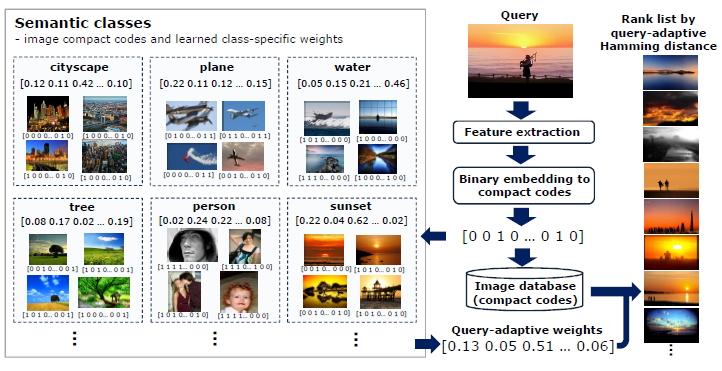
(Query-adaptive hash based image ranking)
People
Shih-Fu Chang, Junfeng He, Yu-Gang Jiang, Wei Liu, Jun WangPublications
- Jun Wang, Sanjiv Kumar, Shih-Fu Chang. Semi-Supervised Hashing for Scalable Image Retrieval. In IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, USA, June 2010. [pdf]
- Jun Wang, Sanjiv Kumar, Shih-Fu Chang. Sequential Projection Learning for Hashing with Compact Codes. In International Conference on Machine Learning (ICML), Haifa, Israel, June 2010. [pdf]
- Junfeng He, Wei Liu, Shih-Fu Chang. Scalable Similarity Search with Optimized Kernel Hashing. In ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), Washington, DC, USA, July 2010. [pdf]
- Yu-Gang Jiang, Jun Wang, Shih-Fu Chang. Lost in Binarization: Query-Adaptive Ranking for Similar Image Search with Compact Codes. In Proceedings of ACM International Conference on Multimedia Retrieval (ICMR), oral session, 2011. [pdf]
- Junfeng He, Regunathan Radhakrishnan, Shih-Fu Chang, Claus Bauer. Compact Hashing with Joint Optimization of Search Accuracy and Time. In IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), oral session, June 2011. [pdf]
- Wei Liu, Jun Wang, Sanjiv Kumar, Shih-Fu Chang. Hashing with Graphs. In International Conference on Machine Learning (ICML), Bellevue, WA, USA, 2011. [pdf] [code]