|
|
|
| |
 |
|
Discrete Graph Hashing. Wei Liu, Cun Mu, Sanjiv Kumar and Shih-Fu Chang In Neural Information Processing Systems (NIPS) Montreal, Canada December, 2014 [pdf] [supplementary material] |
| |
Hashing has emerged as a popular technique for fast nearest neighbor search in gigantic databases. In particular, learning based hashing has received considerable attention due to its appealing storage and search efficiency. However, the performance of most unsupervised learning based hashing methods deteriorates rapidly as the hash code length increases. We argue that the degraded performance is due to inferior optimization procedures used to achieve discrete binary codes. This paper presents a graph-based unsupervised hashing model to preserve the neighborhood structure of massive data in a discrete code space. We cast the graph hashing problem into a discrete optimization framework which directly learns the binary codes. A tractable alternating maximization algorithm is then proposed to explicitly deal with the discrete constraints, yielding high-quality codes to well capture the local neighborhoods. Extensive experiments performed on four large datasets with up to one million samples show that our discret optimization based graph hashing method obtains superior search accuracy over state-of-the-art unsupervised hashing methods, especially for longer codes.
|
|
|
|
|
|
| |
 |
|
Why We Watch the News: A Dataset for Exploring Sentiment IN Broadcast Video News. Joseph G. Ellis, Brendan Jou, Shih-Fu Chang In ACM International Conference on Multimodal Interaction Istanbul, Turkey November, 2014 [pdf] [poster] [web] |
| |
We present a multimodal sentiment study performed on a novel collection of videos mined from broadcast and cable television news programs. To the best of our knowledge, this is the first dataset released for studying sentiment in the domain of broadcast video news. We describe our algorithm for the processing and creation of person-specific segments from news video, yielding 929 sentence-length videos, and are annotated via Amazon Mechanical Turk. The spoken transcript and the video content itself are each annotated for their expression of positive, negative or neutral sentiment.
Based on these gathered user annotations, we demonstrate for news video the importance of taking into account multimodal information for sentiment prediction, and in particular, challenging previous text-based approaches that rely solely on available transcripts. We show that as much as 21.54 of the sentiment annotations for transcripts differ from their respective sentiment annotations when the video clip itself is presented. We present audio and visual classification baselines over a three-way sentiment prediction of positive, negative and neutral, as well as person-dependent versus person-independent classification influence on performance. Finally, we release the News Rover Sentiment dataset to the greater research community.
|
|
|
|
|
|
| |
 |
|
Scalable Visual Instance Mining with Threads of Features. Wei Zhang, Hongzhi Li, Chong-Wah Ngo, Shih-Fu Chang In ACM Multimedia (ACM MM) Orlando, USA November, 2014 [pdf] |
| |
We address the problem of visual instance mining, which is to extract frequently appearing visual instances automatically from a multimedia collection. We propose a scalable mining method by exploiting Thread of Features (ToF). Specifically, ToF, a compact representation that links consistent features across images, is extracted to reduce noises, discover patterns, and speed up processing. Various instances, especially small ones, can be discovered by exploiting correlated ToFs. Our approach is significantly more effective than other methods in mining small instances. At the same time, it is also more efficient by requiring much fewer hash tables. We compared with several state-of-the-art methods on two fully annotated datasets: MQA and Oxford, showing large performance gain in mining (especially small) visual instances. We also run our method on another Flickr dataset with one million images for scalability test. Two applications, instance search and multimedia summarization, are developed from the novel perspective of instance mining, showing great potential of our method in multimedia analysis.
|
|
|
|
|
|
| |
 |
|
Predicting Viewer Perceived Emotions in Animated GIFs. Brendan Jou, Subhabrata Bhattacharya, Shih-Fu Chang In ACM Multimedia Orlando, FL USA November, 2014 [pdf] |
| |
Animated GIFs are everywhere on the Web. Our work focuses on the computational prediction of emotions perceived by viewers after they are show0n animated GIF images. We evaluate our results on a dataset of over 3,800 animated GIFs gathered from MIT's GIFGIF platform, each with scores for 17 discrete emotions aggregated from over 2.5M user annotations -- the first computational evaluation of its kind for content-based prediction on animated GIFs to our knowledge. In addition, we advocate a conceptual paradigm in emotion prediction that shows delineating distinct types of emotion is important and is useful to be concrete about the emotion target. One of our objectives is to systematically compare different types of content features for emotion prediction, including low-level, aesthetics, semantic and face features. We also formulate a multi-task regression problem to evaluate whether viewer perceived emotion prediction can benefit from jointly learning across emotion classes compared to disjoint, independent learning.
|
|
|
|
|
|
| |
 |
|
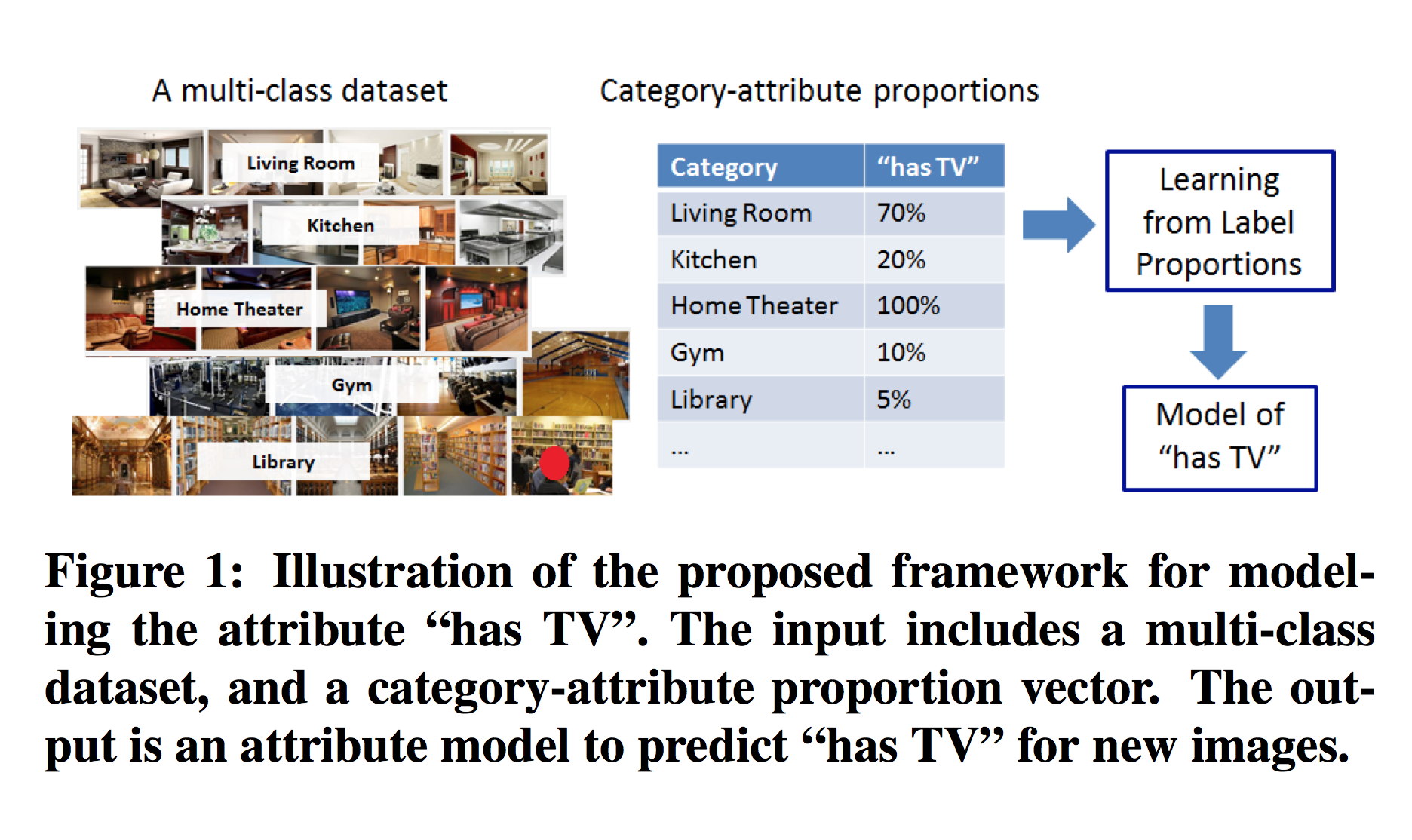
Modeling Attributes from Category-Attribute Proportions. Felix X. Yu, Liangliang Cao, Michele Merler, Noel Codella, Tao Chen, John R. Smith, Shih-Fu Chang In ACM Multimedia Orlando, USA November, 2014 [PDF] |
| |
Attribute-based representation has been widely used in visual recognition and retrieval due to its interpretability and cross-category generalization properties. However, classic attribute learning requires manually labeling attributes on the images, which is very expensive, and not scalable. In this paper, we propose to model attributes from category-attribute proportions. The proposed framework can model attributes without attribute labels on the images. Specifically, given a multi-class image datasets with N categories, we model an attribute, based on an N-dimensional category-attribute proportion vector, where each element of the vector characterizes the proportion of images in the corresponding category having the attribute. The attribute learning can be formulated as a learning from label proportion (LLP) problem. Our method is based on a newly proposed machine learning algorithm called $propto$SVM. Finding the category-attribute proportions is much easier than manually labeling images, but it is still not a trivial task. We further propose to estimate the proportions from multiple modalities such as human commonsense knowledge, NLP tools, and other domain knowledge. The value of the proposed approach is demonstrated by various applications including modeling animal attributes, visual sentiment attributes, and scene attributes.
|
|
|
|
|
|
| |
 |
|
Object-Based Visual Sentiment Concept Analysis and Application. Tao Chen, Felix X. Yu, Jiawei Chen, Yin Cui, Yan-Ying Chen and Shih-Fu Chang In Proceedings of the 22nd ACM International Conference on Multimedia Orlando, FL, USA November, 2014 [pdf] |
| |
This paper studies the problem of modeling object-based visual concepts such as "crazy car" and "shy dog" with a goal to extract emotion related information from social multimedia content. We focus on detecting such adjective-noun pairs because of their strong co-occurrence relation with image tags about emotions. This problem is very challenging due to the highly subjective nature of the adjectives like "crazy" and "shy" and the ambiguity associated with the annotations. However, associating adjectives with concrete physical nouns makes the combined visual concepts more detectable and tractable. We propose a hierarchical system to handle the concept classification in an object specific manner and decompose the hard problem into object localization and sentiment related concept modeling. In order to resolve the ambiguity of concepts we propose a novel classification approach by modeling the concept similarity, leveraging on online commonsense knowledgebase. The proposed framework also allows us to interpret the classifiers by discovering discriminative features. The comparisons between our method and several baselines show great improvement in classification performance. We further demonstrate the power of the proposed system with a few novel applications such as sentiment-aware music slide shows of personal albums.
|
|
|
|
|
|
| |
 |
|
Real-time Pose Estimation of Deformable Objects Using a Volumetric Approach. Yinxiao Li*, Yan Wang*, Michael Case, Shih-Fu Chang, Peter K. Allen In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) Chicago, IL September, 2014 [pdf] [video] * indicates equal contribution. |
| |
Pose estimation of deformable objects is a fundamental and challenging problem in robotics. We present a novel solution to this problem by first reconstructing a 3D model of the object from a low-cost depth sensor such as Kinect, and then searching a database of simulated models in different poses to predict the pose. Given noisy depth images from 360-degree views of the target object acquired from the Kinect sensor, we reconstruct a smooth 3D model of the object using depth image segmentation and volumetric fusion. Then with an efficient feature extraction and matching scheme, we search the database, which contains a large number of deformable objects in different poses, to obtain the most similar model, whose pose is then adopted as the prediction. Extensive experiments demonstrate better accuracy and orders of magnitude speed- up compared to our previous work. An additional benefit of our method is that it produces a high-quality mesh model and camera pose, which is necessary for other tasks such as regrasping and object manipulation.
|
|
|
|
|
|
| |
 |
|
From Low-Cost Depth Sensors to CAD: Cross-Domain 3D Shape Retrieval via Regression Tree Fields. Yan Wang, Jie Feng, Zhixiang Wu, Jun Wang, Shih-Fu Chang In European Conference on Computer Vision (ECCV) Zurich, Switzerland September, 2014 [pdf] [video] |
| |
The recent advances of low-cost and mobile depth sensors dramatically extend the potential of 3D shape retrieval and analysis. While the traditional research of 3D retrieval mainly focused on searching by a rough 2D sketch or with a high-quality CAD model, we tackle a novel and challenging problem of cross-domain 3D shape retrieval, in which users can use 3D scans from low-cost depth sensors like Kinect as queries to search CAD models in the database. To cope with the imperfection of user-captured models such as model noise and occlusion, we propose a cross-domain shape retrieval framework, which minimizes the potential function of a Conditional Random Field to efficiently generate the retrieval scores. In particular, the potential function consists of two critical components: one unary potential term provides robust cross-domain partial matching and the other pairwise potential term embeds spatial structures to alleviate the instability from model noise. Both potential components are efficiently estimated using random forests with 3D local features, forming a Regression Tree Field framework. We conduct extensive experiments on two recently released user-captured 3D shape datasets and compare with several state-of-the-art approaches on the cross-domain shape retrieval task. The experimental results demonstrate that our proposed method outperforms the competing methods with a significant performance gain.
|
|
|
|
|
|
| |
 |
|
Discriminative Indexing for Probabilistic Image Patch Priors. Yan Wang, Sunghyun Cho, Jue Wang, Shih-Fu Chang In European Conference on Computer Vision (ECCV) Zurich, Switzerland September, 2014 [pdf] |
| |
Newly emerged probabilistic image patch priors, such as Expected Patch Log-Likelihood (EPLL), have shown excellent performance on image restoration tasks, especially deconvolution, due to its rich expressiveness. However, its applicability is limited by the heavy computation involved in the associated optimization process. Inspired by the recent advances on using regression trees to index priors defined on a Conditional Random Field, we propose a novel discriminative indexing approach on patch-based priors to expedite the optimization process. Specifically, we propose an efficient tree indexing structure for EPLL, and overcome its training tractability challenges in high-dimensional spaces by utilizing special structures of the prior. Experimental results show that our approach accelerates state-of-the-art EPLL-based deconvolution methods by up to 40 times, with very little quality compromise.
|
|
|
|
|
|
| |
 |
|
Recognizing Complex Events in Videos by Learning Key Static-Dynamic Evidences. Kuan-Ting Lai, Dong Liu, Ming-Syan Chen and Shih-Fu Chang. In European Conference on Computer Vision. Zurich, Switzerland. September, 2014 [pdf] |
| |
Complex events in videos consist of various human interactions with different objects in diverse environments. As a consequence, the evidences needed to recognize events may occur in short time periods with variable lengths and may happen anywhere in a video. This fact prevents conventional machine learning algorithms from e�ffectively recognizing the events. We propose a novel method that can automatically identify the key evidences in videos for detecting complex events. Both static instances (objects) and dynamic instances (actions) are considered by sampling frames and temporal segments respectively. To compare the characteristic power of heterogeneous instances, we embed static and dynamic instances into a multiple instance learning framework via instance similarity measures, and cast the problem as an Evidence Selective Ranking (ESR) process. We impose L-1 norm to select key evidences while using the Infi�nite Push Loss Function to enforce positive videos to have higher detection scores than negative videos. Experiments on large-scale video datasets show that our method can improve the detection accuracy while providing the unique capability in discovering key evidences of each complex event.
|
|
|
|
|
|
| |
 |
|
Circulant Binary Embedding. Felix X. Yu, Sanjiv Kumar, Yunchao Gong, Shih-Fu Chang In International Conference on Machine Learning (ICML) 2014 Beijing, China June, 2014 [PDF] [Code] [Slides] |
| |
Binary embedding of high-dimensional data requires long codes to preserve the discriminative power of the input space. Traditional binary coding methods often suffer from very high computation and storage costs in such a scenario. To address this problem, we propose Circulant Binary Embedding (CBE) which generates binary codes by projecting the data with a circulant matrix. The circulant structure enables the use of Fast Fourier Transformation to speed up the computation. Compared to methods that use unstructured matrices, the proposed method improves the time complexity from $mathcal{O}(d^2)$ to $mathcal{O}(dlog{d})$, and the space complexity from $mathcal{O}(d^2)$ to $mathcal{O}(d)$ where $d$ is the input dimensionality. We also propose a novel time-frequency alternating optimization to learn data-dependent circulant projections, which alternatively minimizes the objective in original and Fourier domains. We show by extensive experiments that the proposed approach gives much better performance than the state-of-the-art approaches for fixed time, and provides much faster computation with no performance degradation for fixed number of bits.
|
|
|
|
|
|
| |
.jpg) |
|
Hash-SVM: Scalable Kernel Machines for Large-Scale Visual Classification. Yadong Mu, Gang Hua, Wei Fan, Shih-Fu Chang In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Columbus, Ohio June, 2014 [PDF] |
| |
This paper presents a novel algorithm which uses compact hash bits to greatly improve the efficiency of non-linear kernel SVM in very large scale visual classification problems. Our key idea is to represent each sample with compact hash bits, over which an inner product is defined to serve as the surrogate of the original nonlinear kernels. Then the problem of solving the nonlinear SVM can be transformed into solving a linear SVM over the hash bits. The proposed Hash-SVM enjoys dramatic storage cost reduction owing to the compact binary representation, as well as a (sub-)linear training complexity via linear SVM. As a critical component of Hash-SVM, we propose a novel hashing scheme for arbitrary non-linear kernels via random subspace projection in reproducing kernel Hilbert space. Our comprehensive analysis reveals a well behaved theoretic bound of the deviation between the proposed hashing-based kernel approximation and the original kernel function. We also derive requirements on the hash bits for achieving a satisfactory accuracy level. Several experiments on large-scale visual classification benchmarks are conducted, including one with over 1 million images. The results show that Hash-SVM greatly reduces the computational complexity (more than ten times faster in many cases) while keeping comparable accuracies.
|
|
|
|
|
|
| |
 |
|
Video Event Detection by Inferring Temporal Instance Labels. Kuan-Ting Lai, Felix X. Yu, Ming-Syan Chen, Shih-Fu Chan In IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR) Columbus, OH June, 2014 [pdf] |
| |
We address a well-known challenge related to video indexing - given annotations of complex events (such as wedding, rock climbing, etc) occurring in videos, how to identify precise video segments in the long programs that instantiate event evidences. Solutions of this problem will enable temporarily aligned video content summarization, search, and target ad placement. In this work, we propose a novel instance-based video event detection model based on a new learning algorithm called Proportional SVM. It considers each video as a bag of instances, which may be extracted from multiple temporal granularities (key frames and segments of varying lengths) and represented by various features (SIFT or motion boundary histogram). It uses a large-margin formulation which treats the instance labels as hidden latent variables, and simultaneously infers the instance labels as well as the instance-level classification model. Our method assumes positive videos have a large proportion of positive instances while negative videos have a small one. Extensive experiments on large-scale video event datasets demonstrate significant performance gains. Our method is also able to discover the optimal temporal granularity for detecting each complex event.
|
|
|
|
|
|
| |
 |
|
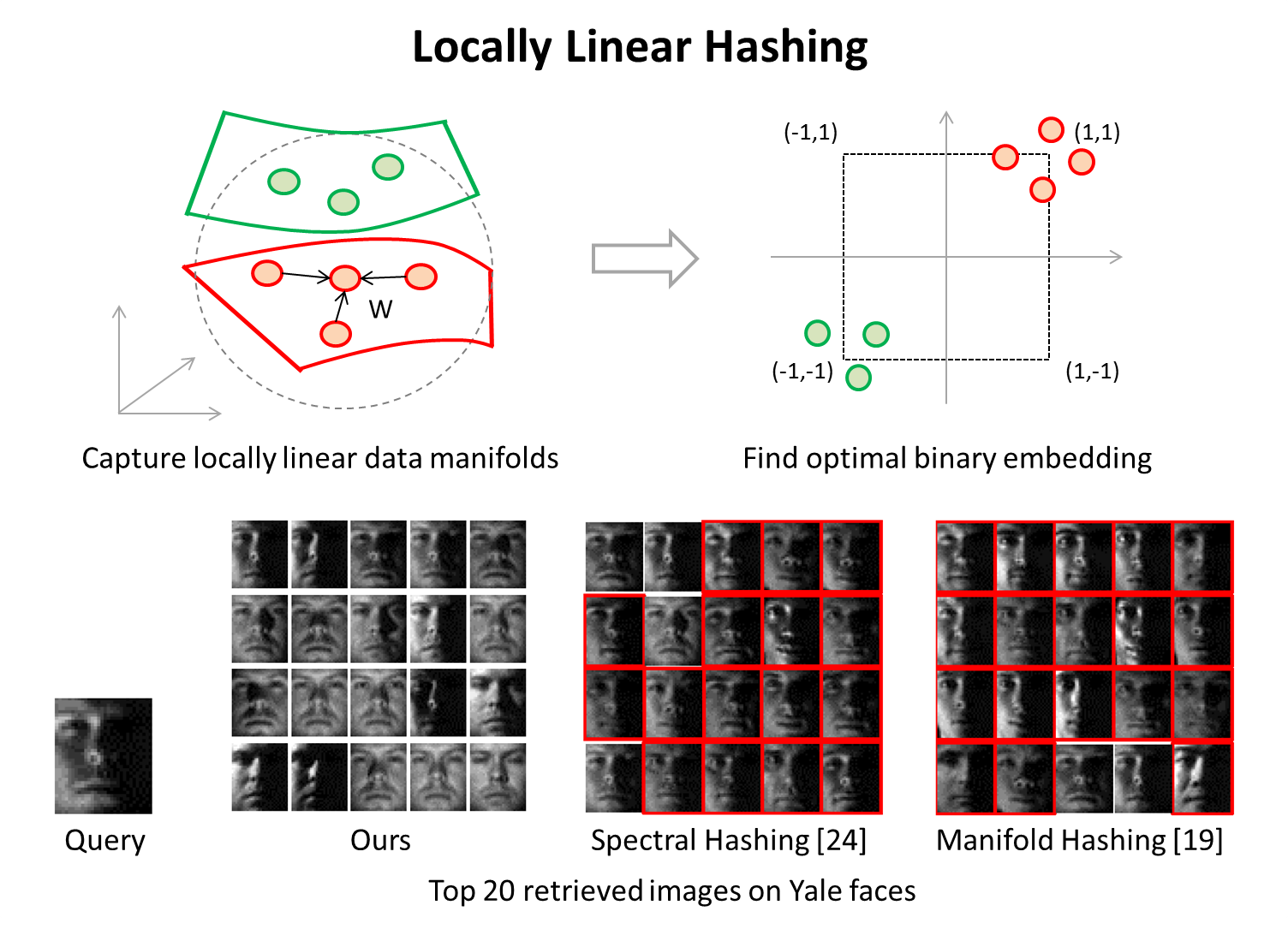
Locally Linear Hashing for Extracting Non-linear Manifolds. Go Irie, Zhenguo Li, Xiao-Ming Wu, Shih-Fu Chang In IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR) Columbus, OH June, 2014 [pdf] |
| |
In this paper, we propose a hashing method aiming at reconstructing the locally linear structures of data manifolds in the binary Hamming space, which can be captured by locality-sensitive sparse coding. We cast the problem as a joint minimization of reconstruction error and quantization loss and show that a local optimum can be obtained efficiently via alternating optimization. Our results improve previous state-of-the-art methods by typically 28-74% in semantic retrieval performance, and 627% on the Yale face data.
|
|
|
|
|
|
| |
.png) |
|
Minimally Needed Evidence for Complex Event Recognition in Unconstrained Videos. Subhabrata Bhattacharya, Felix X. Yu, Shih-Fu Chang In ACM International Conference on Multimedia Retrieval Glasgow, UK April, 2014 [Pdf] [slides] |
| |
This paper addresses the fundamental question -- How do humans recognize complex events in videos? Normally, humans view videos in a sequential manner. We hypothesize that humans can make high-level inference such as an event is present or not in a video, by looking at a very small number of frames not necessarily in a linear order. We attempt to verify this cognitive capability of humans and to discover the Minimally Needed Evidence (MNE) for each event. To this end, we introduce an online game based event quiz facilitating selection of minimal evidence required by humans to judge the presence or absence of a complex event in an open source video. Each video is divided into a set of temporally coherent microshots (1.5 secs in length) which are revealed only on player request. The player's task is to identify the positive and negative occurrences of the given target event with minimal number of requests to reveal evidence. Incentives are given to players for correct identification with the minimal number of requests.
Our extensive human study using the game quiz validates our hypothesis - 55% of videos need only one microshot for correct human judgment and events of varying complexity require different amounts of evidence for human judgment. In addition, the proposed notion of MNE enables us to select discriminative features, drastically improving speed and accuracy of a video retrieval system.
|
|
|
|
|
|
| |
 |
|
Predicting Viewer Affective Comments Based on Image Content in Social Media. Yan-Ying Chen, Tao Chen, Winston H. Hsu, Hong-Yuan Mark Liao, Shih-Fu Chang In ACM International Conference on Multimedia Retrieval Glasgow, United Kingdom April, 2014 [pdf] |
| |
Visual sentiment analysis is getting increasing attention because of the rapidly growing amount of images in online social interactions and emerging applications such as online propaganda and advertisement. This paper focuses on predicting what viewer affect concepts will be triggered when the image is perceived by the viewers. For example, given an image tagged with "yummy food," the viewers are likely to comment "delicious" and "hungry," which we refer to as viewer affect concepts (VAC) in this paper. We propose an automatic content based approach to predict VACs by first detecting sentiment related visual concepts expressed by the image publisher in the image content and then applying statistical correlations between such publisher affects and the VACs. We demonstrate the novel use of the proposed models in several real-world applications - recommending images to invoke certain target affects among viewers, increasing the accuracy of predicting VACs by 20.1%, and finally developing a comment robot tool that may suggest plausible, content-specific and desirable comments when a new image is shown.
|
|
|
|
|
|
| |
 |
|
Event-Driven Semantic Concept Discovery by Exploiting Weakly Tagged Internet Images. Jiawei Chen, Yin Cui, Guangnan Ye, Dong Liu, Shih-Fu Chang. In ACM International Conference on Multimedia Retrieval. Glasgow, UK. April, 2014 [pdf] |
| |
In this project, we aim to develop automatic methods to discover semantic concepts characterizing complex video events by (1) first extracting key terms in event definitions, (2) crawling web images with the extracted terms, and (3) discovering the frequent tags used to described the web images. The final discovered tags are used to construct the event specific concepts. The approach is fully automatic and scalable as it does not need human annotation and can readily utilize the large amount of Web images to train the concept detectors. We use the TRECVID Multimedia Event Detection (MED) 2013 as the video test set and crawl 400K Flickr images to automatically discover 2,000 visual concepts and train their classifiers. We show the large concept classifier pool can be used to achieve significant performance gains in supervised event detection, as well as zero-shot retrieval without needing any video training examples. It outperforms other concept pools like Classemes and ImageNet by a large margin (228%) in zero-shot event retrieval. Subjective evaluation by humans also confirms the discovered concepts are much more intuitive than other concept discovery methods.
|
|
|
|
|
