Why We Watch the News: A Dataset for Exploring Sentiment in Broadcast Video News
ACM International Conference on Multimodal Interaction 2014
Joseph G. Ellis, Brendan Jou, and Shih Fu Chang
Digital Video and Multimedia Lab
Columbia University
Abstract
Based on these gathered user annotations, we demonstrate for news video the importance of taking into account multimodal information for sentiment prediction, and in particular, challenging previous text-based approaches that rely solely on available transcripts.
We show that as much as 21.54% of the sentiment annotation of users for transcripts differ from their respective sentiment annotations when the video clip itself is presented.
We present audio and visual classification baselines over a three-way sentiment prediction of positive, negative and neutral, as well as person-dependent versus person-independent classification influence on performance.
Finally, we release the dataset to the greater research community.
Motivation
Although text-based sentiment analysis has been studied in great detail recently, video based sentiment analysis is still somewhat in it's infancy.
Much of the opinion mining analysis is done in domains that have heavily polarized lexicons and obvious sentiment polarity.
For example, a very popular domain for sentiment analysis can be movie and product reviews, where the text available is heavily polarized and there is little room for ambiguity.
Statements like "I absolutely loved this movie" or the "the acting was terrible", have very clear and polarized sentiment that can be attributed to them.
However, in more complicated domains, such as news video transcripts or news articles, the sentiment attached to a statement can be much less obvious.
For example, take the statement that has been relevant in the news in the past year, ``Russian troops have entered into Crimea''.
This statement by itself is not polarizing as positive or negative and is in fact quite neutral.
However, if it was stated by a U.S. politician it would probably have very negative connotations and if stated by a Russian politician it could have a very positive sentiment associated with it.
Therefore, in more complicated domains such as news the text content is often not sufficient to determine the sentiment of a particular statement.
For some ambiguous statements it is important to take into account the way that words are spoken (audio) and the gestures and facial expressions (visual) that accompany the sentence to be able to more accurately determine the sentiment of the statement.
Contributions
News Rover Sentiment Dataset
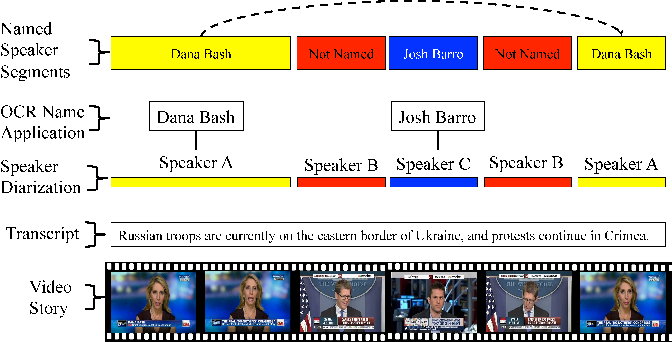
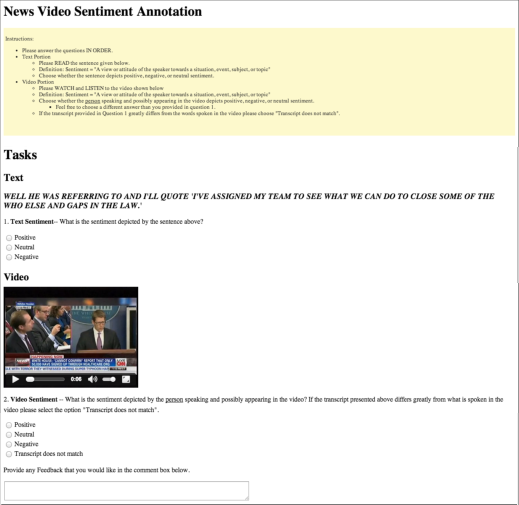
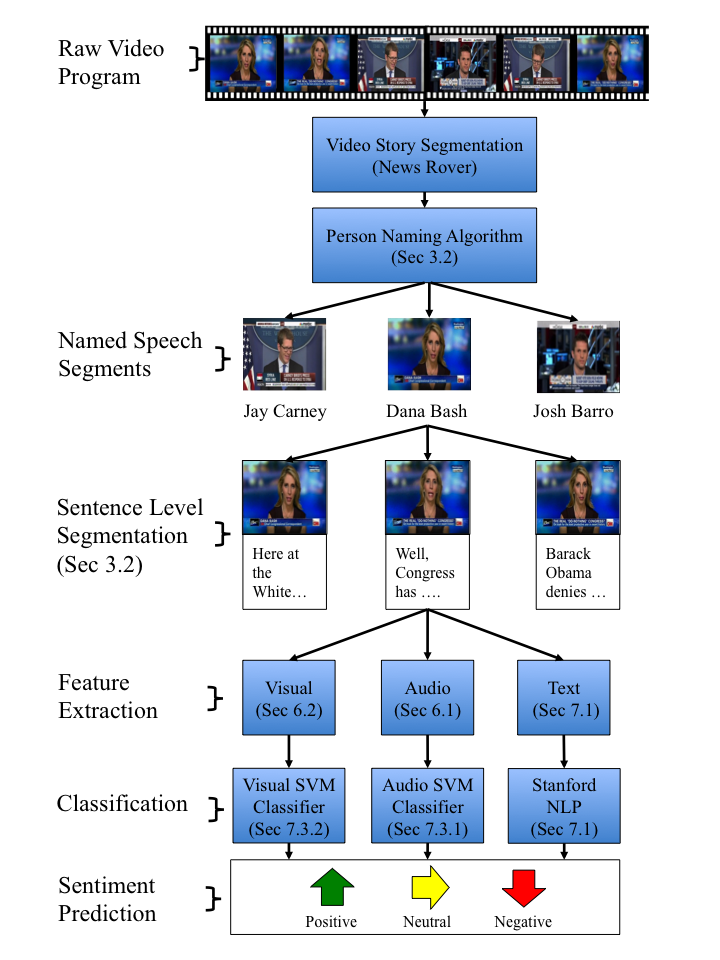
Experiments
and Results
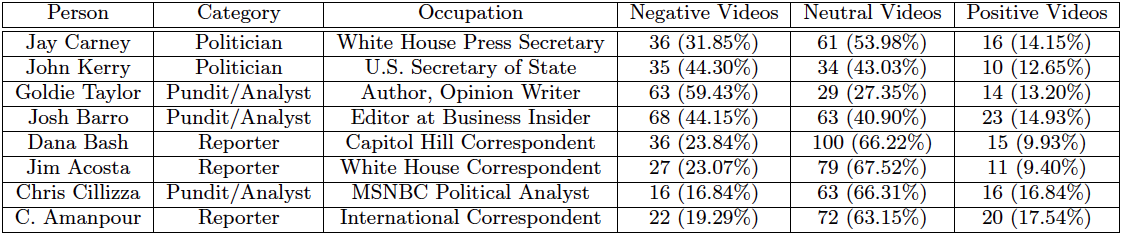
We conduct experiments on the News Rover Sentiment dataset presented above. We trained both global and person-specific sentiment models using linear SVMs and attempted to predict the sentiment within each video. We chose 4-fold cross-validation as our training metric, and presented in this section is the average accuracy across the 4-folds. For the original dataset that was created we tested all 929 videos with the extracted audio features, but we only were able to automatically detect 455 videos with speaking faces. Therefore, we only tested the visual features using these 455 videos. To provide a consistent dataset where audio and video can be tested and compared against each other we also went through each of the 929 videos, and found each of the "clean" videos in the dataset. The clean videos are those videos which have the correct name applied to the video, and the speaker can be seen visually speaking. The clean dataset is composed of 650 videos.

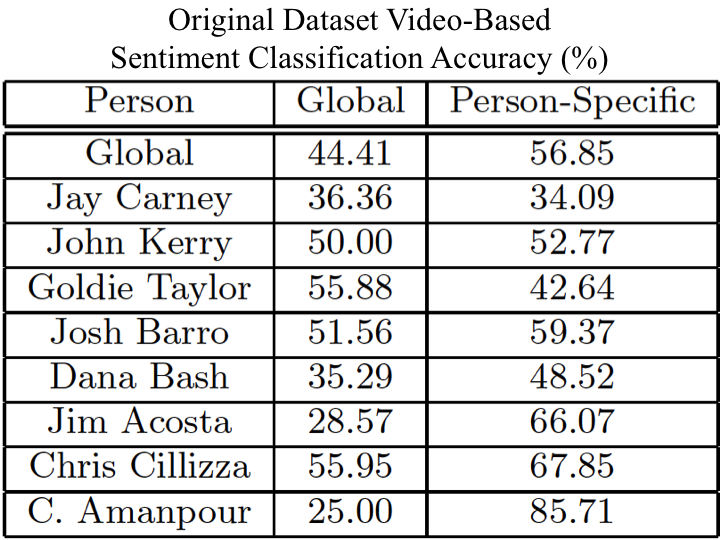
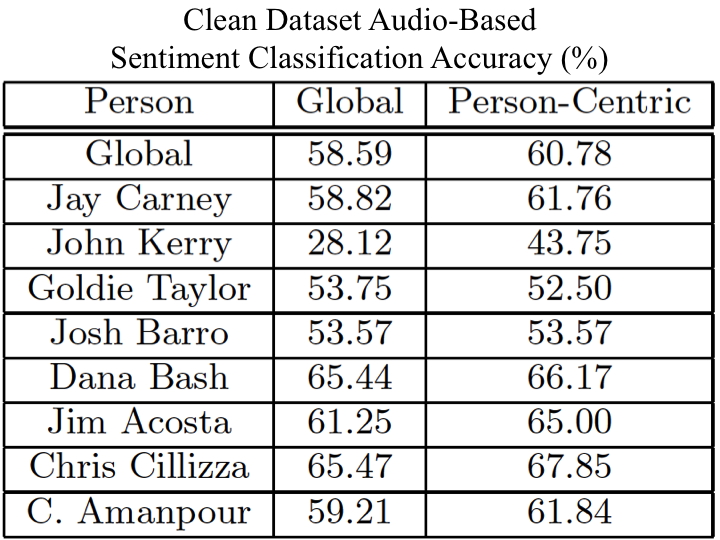
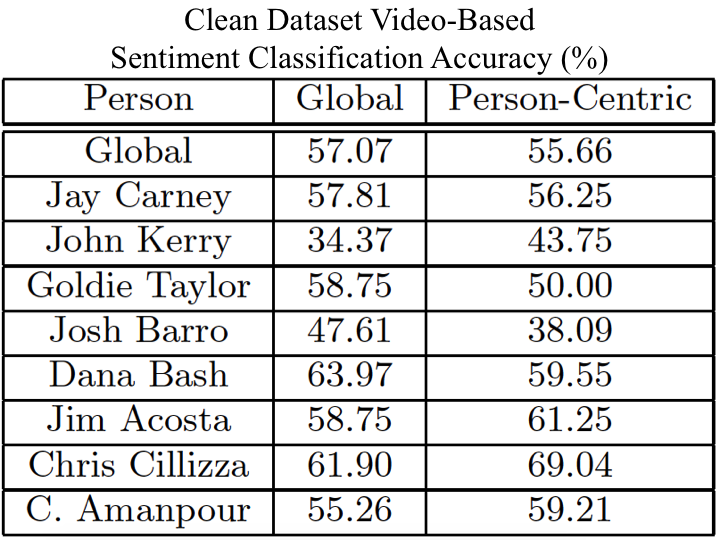
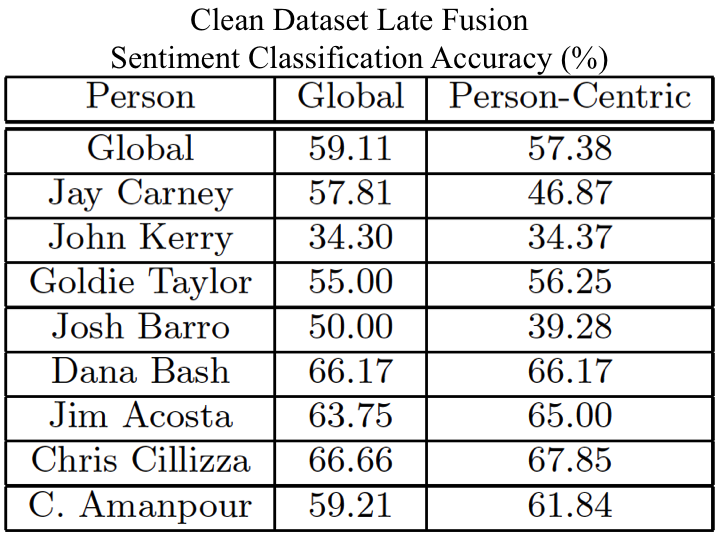
We provide the links to each of the News Rover datset videos, and the extracted features that we have extracted from each of the videos. We also provide the clean and original version of the dataset with aggregated annotations for each video. As well as the data we also provide code to replicate the performance and results that are seen above. For access to the dataset, please fill out the following information. You will receive an email with file link.
[Thanks to Yong Jae Lee for the webpage template]