|
|
|
| |
 |
|
Large Scale Video Hashing via Structure Learning. Guangnan Ye, Dong Liu, Jun Wang, Shih-Fu Chang In In IEEE International Conference on Computer Vision Sydney, Australia December, 2013 [pdf] |
| |
In this paper, we developed a novel hashing method that aims at preserving both the visual content similairty and temporal information of videos. We formulate a regularized optimization objective that exploits visual descriptors common to a semantic class, and "push" successive video frames into the same hash bins. We show that the objective can be efficiently solved by an Accelerated Proximal Gradient (APG) method, and significant performance gains over the state of the art can be achieved.
|
|
|
|
|
|
| |
 |
|
News Rover: Exploring Topical Structures and Serendipity in Heterogeneous Multimedia News. Hongzhi Li*, Brendan Jou*, Joseph G. Ellis*, Daniel Morozoff*, and Shih-Fu Chang In ACM Multimedia Barcelona, Spain October, 2013 [pdf] [project] [demo video] |
| |
News stories are rarely understood in isolation. Every story is driven by key entities that give the story its context. Persons, places, times, and several surrounding topics can often succinctly represent a news event, but are only useful if they can be both identified and linked together. We introduce a novel architecture called News Rover for re-bundling broadcast video news, online articles, and Twitter content. The system utilizes these many multimodal sources to link and organize content by topics, events, persons and time. We present two intuitive interfaces for navigating content by topics and their related news events as well as serendipitously learning about a news topic. These two interfaces trade-off between user-controlled and serendipitous exploration of news while retaining the story context. The novelty of our work includes the linking of multi-source, multimodal news content to extracted entities and topical structures for contextual understanding, and visualized in intuitive active and passive interfaces.
|
|
|
|
|
|
| |
 |
|
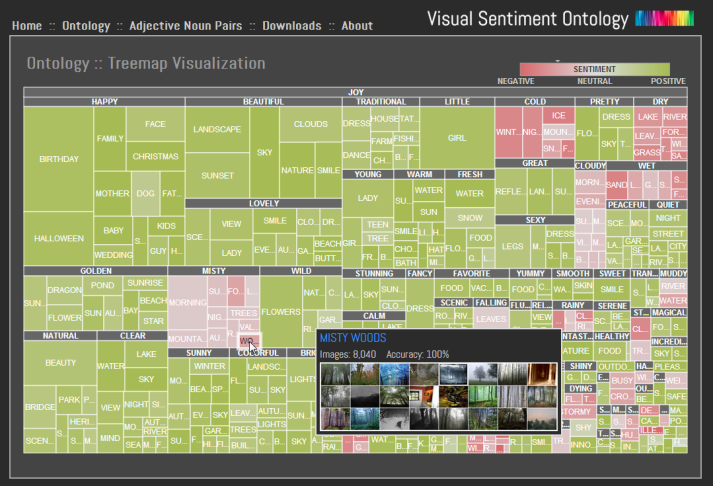
SentiBank: Large-Scale Ontology and Classifiers for Detecting Sentiment and Emotions in Visual Content. Damian Borth, Tao Chen, Rong-Rong Ji and Shih-Fu Chang In ACM Multimedia, Barcelona, Spain October, 2013 [project] [pdf] [video1] [video2] |
| |
We demonstrate a novel system which combines sound structures from psychology and the folksonomy extracted from social multimedia to develop a large visual sentiment ontology consisting of 1,200 concepts and their corresponding automatic classifiers called SentiBank. Each concept, defined as an Adjective Noun Pair (ANP), is made of an adjective strongly indicating emotions and a noun corresponding to objects or scenes that have a reasonable prospect of automatic detection. We demonstrate novel applications made possible by SentiBank including live sentiment prediction of phototweets and visualization of visual content in a rich semantic space organized by emotion categories. In addition, two novel browsers are developed, implementing ideas of the wheel of emotion and the tree map respectively.
|
|
|
|
|
|
| |
 |
|
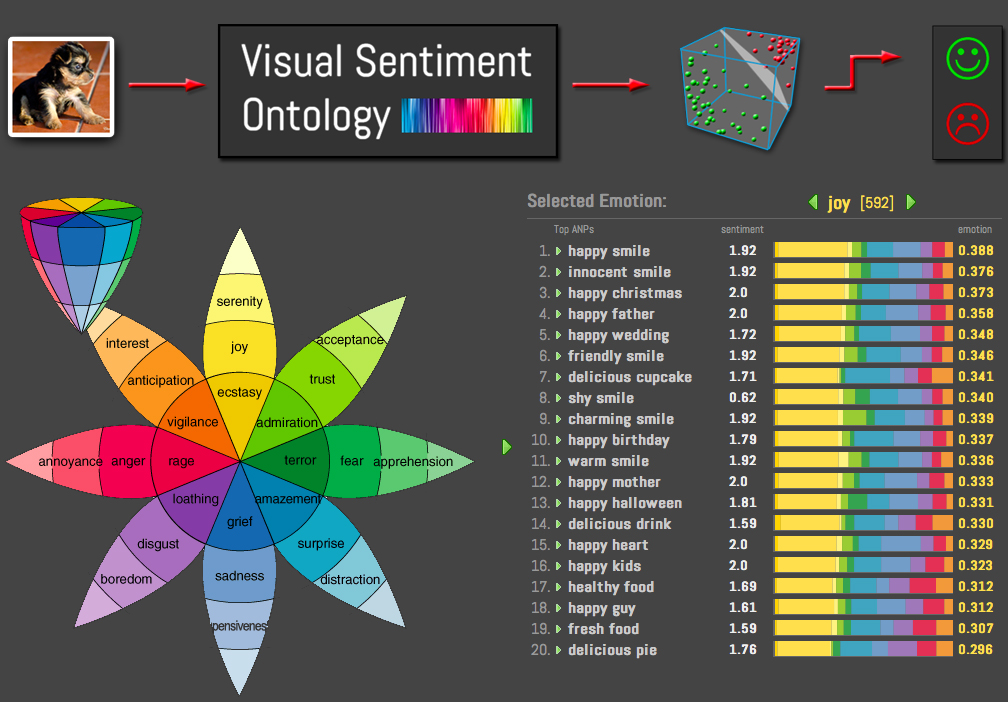
Large-scale Visual Sentiment Ontology and Detectors Using Adjective Noun Pairs. Damian Borth, Rongrong Ji, Tao Chen, Thomas Breuel and Shih-Fu Chang In ACM Multimedia, Brave New Idea Program. Barcelona, Spain October, 2013 [project] [pdf] [video1] [video2] |
| |
To address the challenge of sentiment analysis from visual content, we propose a novel approach based on understanding of the visual concepts that are strongly related to sentiments. Our key contribution is two-fold: first, we present a method built upon psychological theories and web mining to automatically construct a large-scale Visual Sentiment Ontology (VSO) consisting of more than 3,000 Adjective Noun Pairs (ANP). Second, we propose SentiBank, a novel visual concept detector library that can be used to detect the presence of 1,200 ANPs in an image. Experiments on detecting sentiment of image tweets demonstrate significant improvement in detection accuracy when comparing the proposed SentiBank based predictors with the text-based approaches. The effort also leads to a large publicly available resource consisting of a visual sentiment ontology, a large detector library, and the training/testing benchmark for visual sentiment analysis.
|
|
|
|
|
|
| |
 |
|
Structured Exploration of Who, What, When, and Where in Heterogeneous Multimedia News Sources. Brendan Jou* and Hongzhi Li* and Joseph G. Ellis* and Daniel Morozoff and Shih-Fu Chang In ACM Multimedia Barcelona, Spain October, 2013 [pdf] [project] [demo video] |
| |
We present a fully automatic system from raw data gathering to navigation over heterogeneous news sources, including over 18k hours of broadcast video news, 3.58M online articles, and 430M public Twitter messages. Our system addresses the challenge of extracting "who," "what," "when," and "where" from a truly multimodal perspective, leveraging audiovisual information in broadcast news and those embedded in articles, as well as textual cues in both closed captions and raw document content in articles and social media. Performed over time, we are able to extract and study the trend of topics in the news and detect interesting peaks in news coverage over the life of the topic. We visualize these peaks in trending news topics using automatically extracted keywords and iconic images, and introduce a novel multimodal algorithm for naming speakers in the news. We also present several intuitive navigation interfaces for interacting with these complex topic structures over different news sources.
|
|
|
|
|
|
| |
 |
|
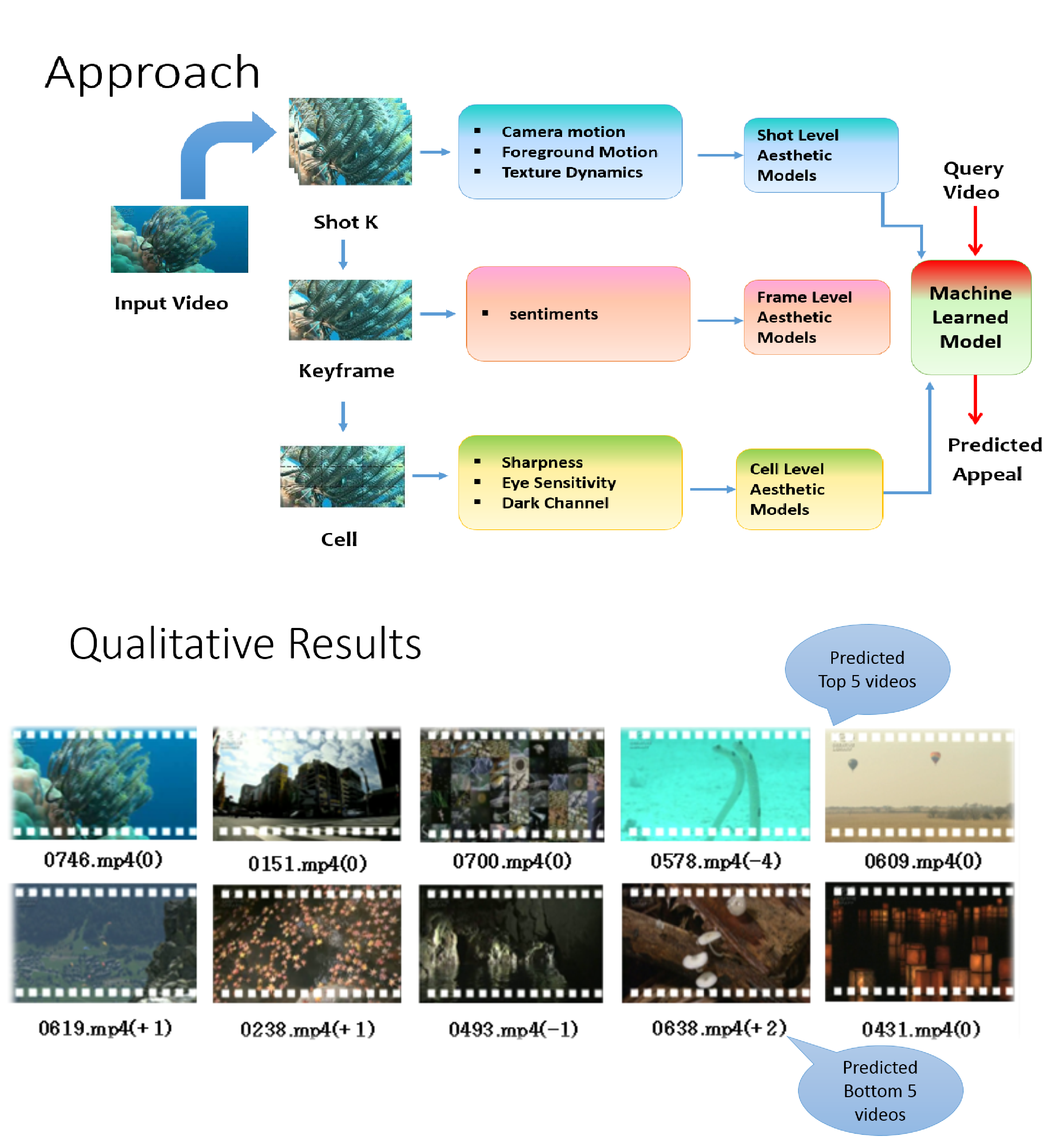
Towards a Comprehensive Computational Model for Aesthetic Assessment of Videos. Subhabrata Bhattacharya, Behnaz Nojavanasghari, Tao Chen, Dong Liu, Shih-Fu Chang, Mubarak Shah In ACM International Conference on Multimedia (ACM MM) Barcelona, Spain October, 2013 www.ee.columbia.edu/ln/dvmm/publications/13/mm207gc-bhattacharya.pdf |
| |
In this paper we propose a novel aesthetic model emphasizing psycho-visual statistics extracted from multiple levels in contrast to earlier approaches that rely only on descriptors suited for image recognition or based on photographic principles. At the lowest level, we determine dark-channel, sharpness and eye-sensitivity statistics over rectangular cells within a frame. At the next level, we extract Sentibank features (1,200 pre-trained visual classifiers) on a given frame, that invoke specific sentiments such as "colorful clouds", "smiling face" etc. and collect the classifier responses as frame-level statistics. At the topmost level, we extract trajectories from video shots. Using viewer's fixation priors, the trajectories are labeled as foreground, and background/camera on which statistics are computed. Additionally, spatio-temporal local binary patterns are computed that capture texture variations in a given shot. Classifiers are trained on individual feature representations independently. On thorough evaluation of 9 different types of features, we select the best features from each level -- dark channel, affect and camera motion statistics. Next, corresponding classifier scores are integrated in a sophisticated low-rank fusion framework to improve the final prediction scores. Our approach demonstrates strong correlation with human prediction on 1,000 broadcast quality videos released by NHK as an aesthetic evaluation dataset.
|
|
|
|
|
|
| |
 |
|
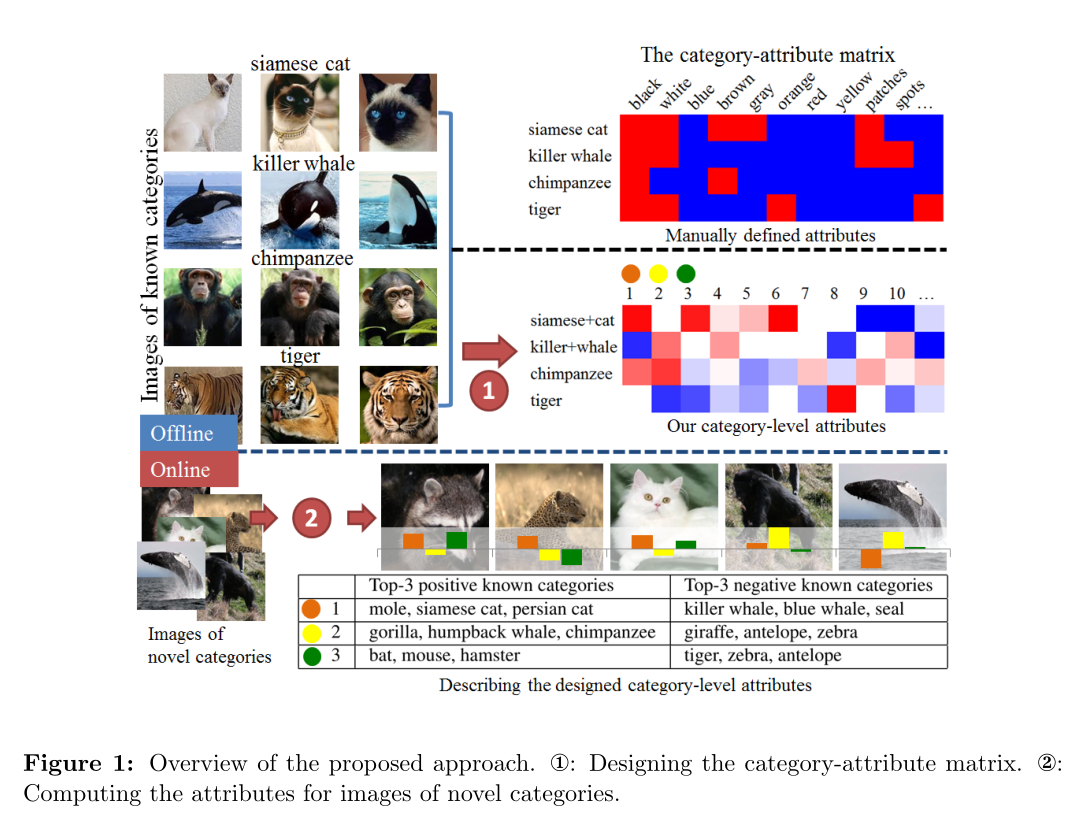
Designing category-level attributes for discriminative visual recognition. Felix X. Yu; Liangliang Cao; Rogerio S. Feris; John R. Smith; Shih-Fu Chang In IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR) Portland, OR, June, 2013 [pdf][supplementary material] |
| |
Attribute-based representation has shown great promises for visual recognition but usually requires human design efforts. In this paper, we propose a novel formulation to automatically design discriminative category-level attributes, which are distinct from prior works focusing on sample-level attributes. The designed attributes can be used for tasks of cross-category knowledge transfer and zero-shot learning, achieving superior performance over well-known attribute dataset Animals with Attributes (AwA) and a large-scale ILSVRC2010 dataset (1.2M images).
|
|
|
|
|
|
| |
 |
|
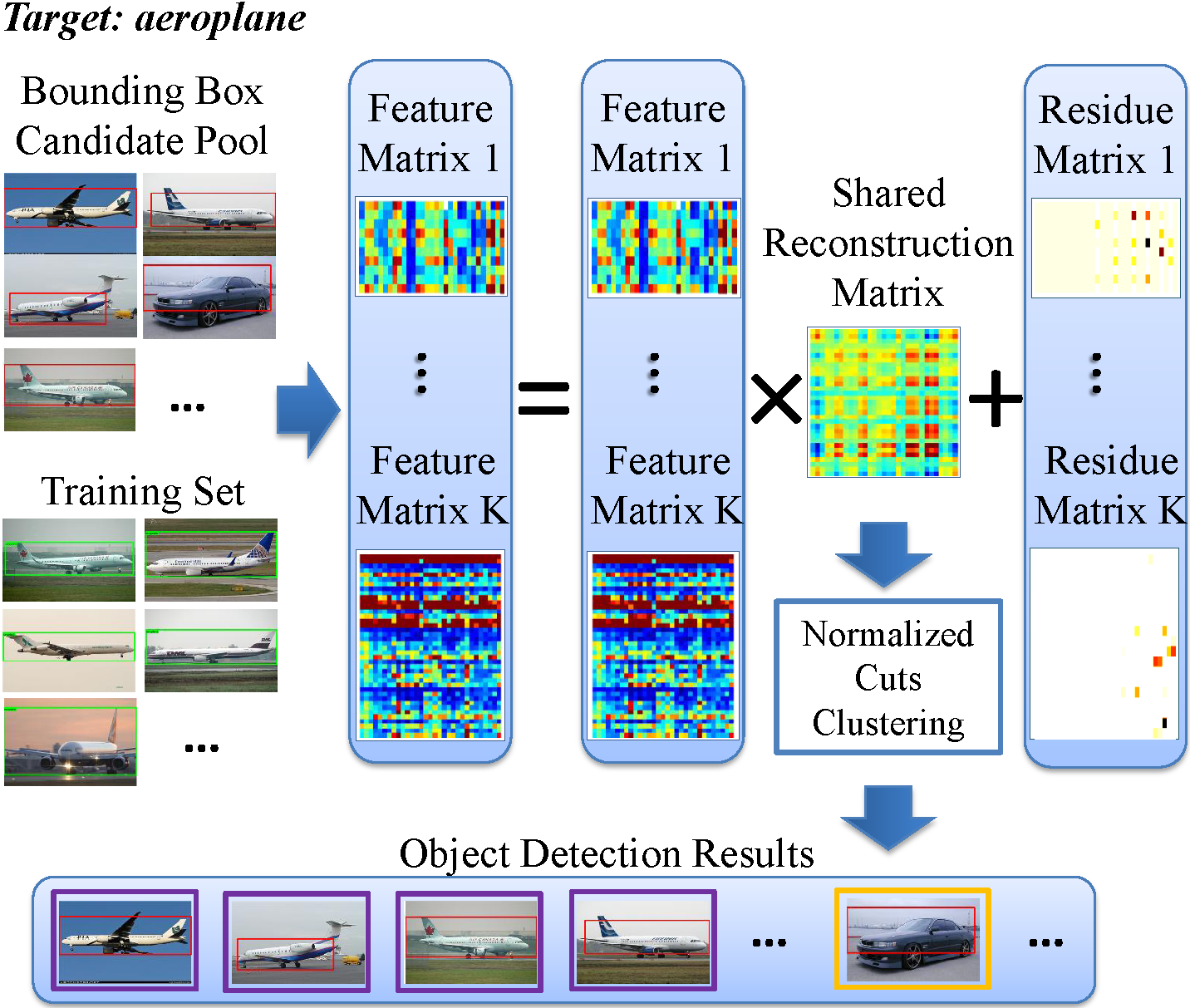
Robust Object Co-Detection. Xin Guo, Dong Liu, Brendan Jou, Mojun Zhu, Anni Cai, Shih-Fu Chang In IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR) Portland, OR, June, 2013 [pdf] |
| |
Object co-detection aims at simultaneous detection of objects of the same category from a pool of related images by exploiting consistent visual patterns present in candidate objects in the images. In this paper, we propose a novel robust approach to dramatically enhance co-detection by extracting a shared low-rank representation of the object instances in multiple feature spaces. The low-rank approach enables effective removal of noisy and outlier samples and can be used to detect the target objects by spectral clustering.
|
|
|
|
|
|
| |
 |
|
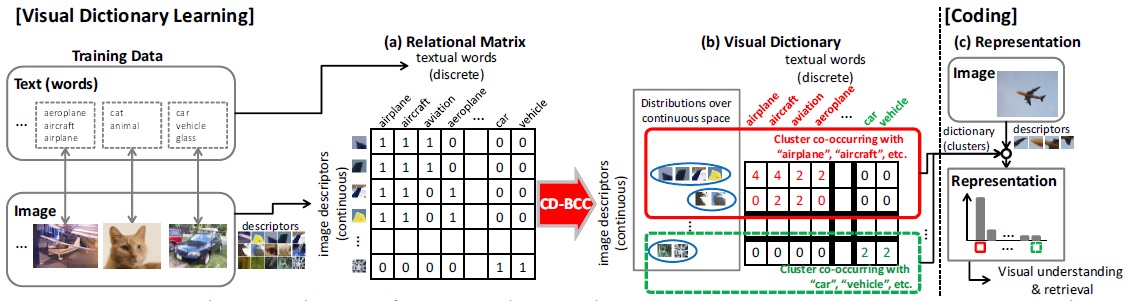
A Bayesian Approach to Multimodal Visual Dictionary Learning. Go Irie, Dong Liu, Zhenguo Li, Shih-Fu Chang In IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR) Portland, OR, June, 2013 [pdf] [supplementary material] |
| |
In this paper, we propose a Bayesian co-clustering approach to multimodal visual dictionary learning. Most existing visual dictionary learning methods rely on image descriptors alone. However, Web images are often associated with text data which may carry substantial information regarding image semantics. Our method jointly estimates the underlying distributions of the continuous image descriptors as well as the relationship between such distributions and the textual words through a unified Bayesian inference.
|
|
|
|
|
|
| |
 |
|
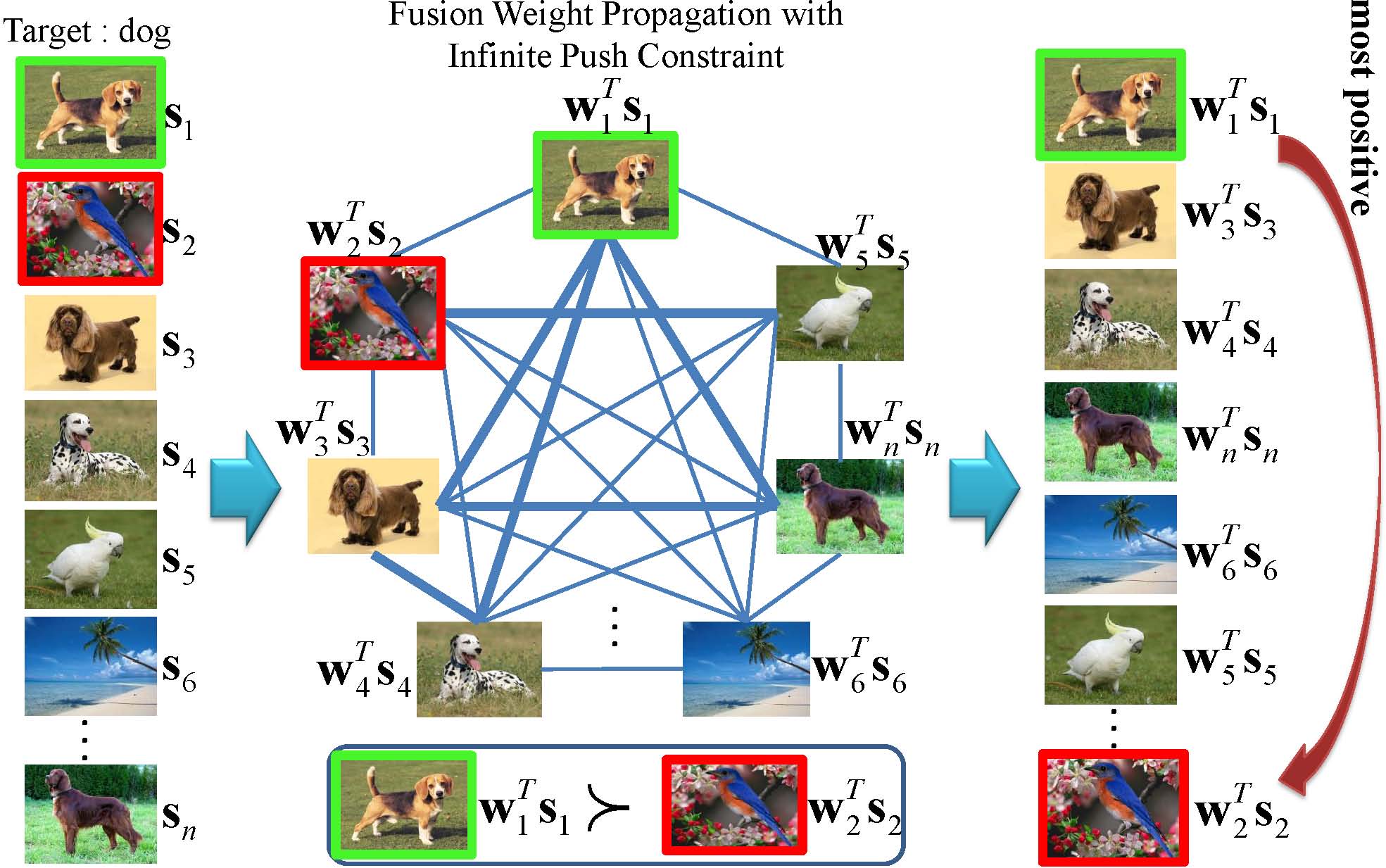
Sample-Specific Late Fusion for Visual Category Recognition. Dong Liu, Kuan-Ting Lai, Guangnan Ye, Ming-Syan Chen, Shih-Fu Chang In IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR) Portland, OR, June, 2013 [pdf] |
| |
In this paper, we propose a sample-specific late fusion method to optimally determine the fusion weight for each sample. The problem is cast as an information propagation process which propagates the fusion weights learned on the labeled samples to unlabeled samples, while enforcing that positive samples have higher fused scores than negative ones. We formulate our problem as a L_infinity norm constrained optimization problem and apply the Alternating Direction Method of Multipliers for optimization. Extensive experiment results on various visual categorization tasks show that the proposed method consistently and significantly outperforms the state-of-the-art late fusion methods. To the best knowledge, this is the first method supporting sample-specific fusion weight learning.
|
|
|
|
|
|
| |
 |
|
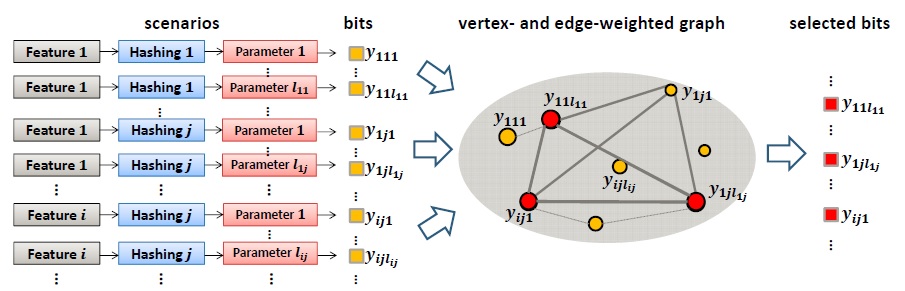
Hash Bit Selection: a Unified Solution for Selection Problems in Hashing. Xianglong Liu, Junfeng He, Bo Lang, Shih-Fu Chang In IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR) Portland, OR, June, 2013 [pdf] |
| |
Hashing based methods recently have been shown promising for large-scale nearest neighbor search. However, good designs involve difficult decisions of many unknowns - data features, hashing algorithms, parameter settings, kernels, etc. In this paper, we provide a unifiied solution as hash bit selection, i.e., selecting the most informative hash bits from a pool of candidates that may have been generated under various conditions mentioned above. We represent the candidate bit pool as a vertex- and edge-weighted graph with the pooled bits as vertices. Then we formulate the bit selection problem as quadratic programming over the graph, and solve it efficiently by replicator dynamics. Extensive experiments show that our bit selection approach can achieve superior performance over both naive selection methods and state-of-the-art methods under each scenario, usually with significant accuracy gains from 10% to 50% relatively.
|
|
|
|
|
|
| |
 |
|
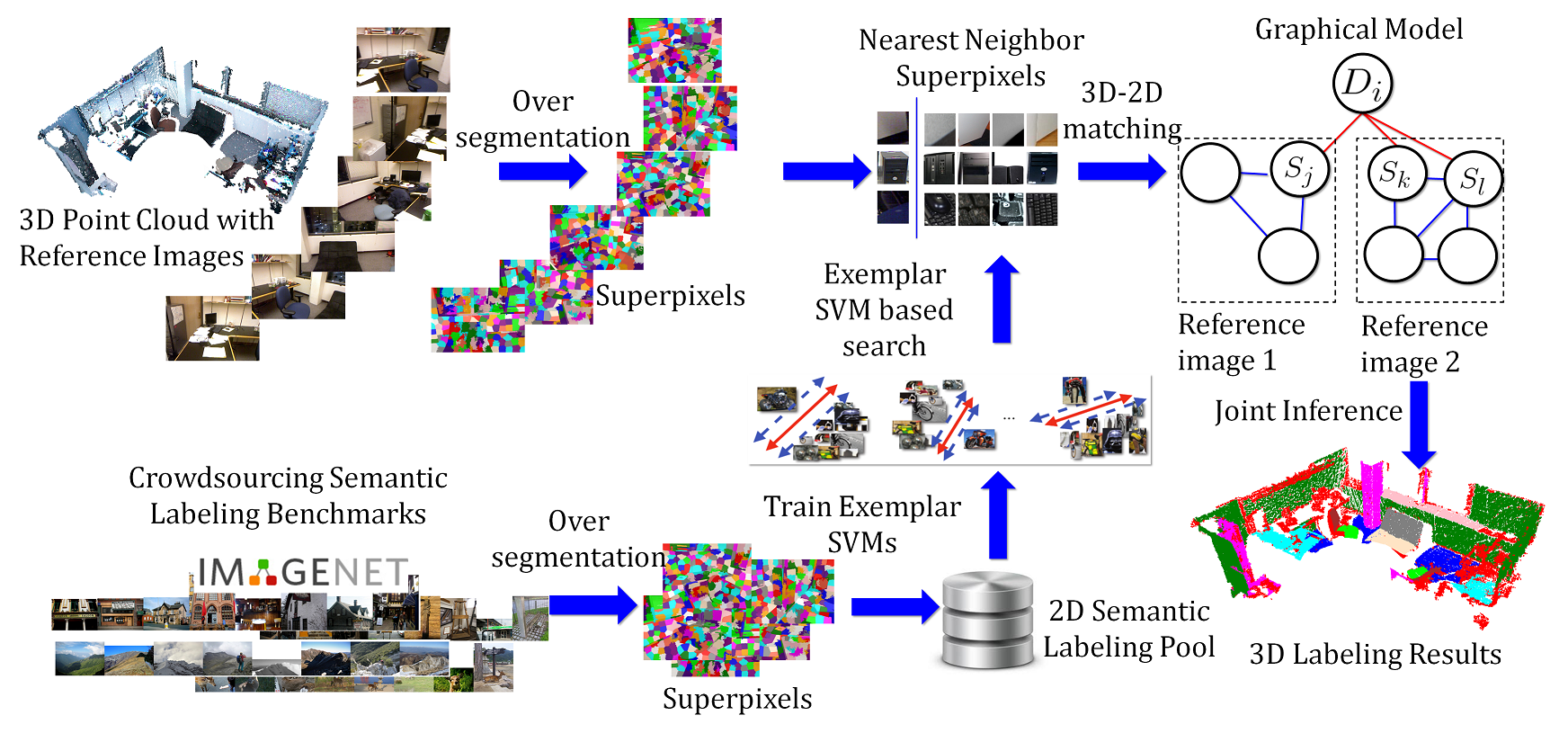
Label Propagation from ImageNet to 3D Point Clouds. Yan Wang, Rongrong Ji, Shih-Fu Chang In IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR) Portland, OR, June, 2013 [pdf] |
| |
Despite of the growing popularity of 3D data, 3D point cloud labeling remains an open problem, due to the difficulty in acquiring sufficient labels. In this paper, we overcome the challenge by utilizing the massive existing 2D semantic labeled datasets, such as ImageNet and LabelMe, and a novel "cross-domain" label propagation framework. Our method consists of two novel components- Exemplar SVM based label propagation for solving the cross-domain issue, and a graphical model based contextual refinement process. The entire solution does not require any training data from the target 3D scenes, and has excellent scalability towards large applications. It achieves significantly higher efficiency and comparable accuracy when no 3D training data is used, and a major accuracy gain when incorporating the target training data.
|
|
|
|
|
|
| |
 |
|
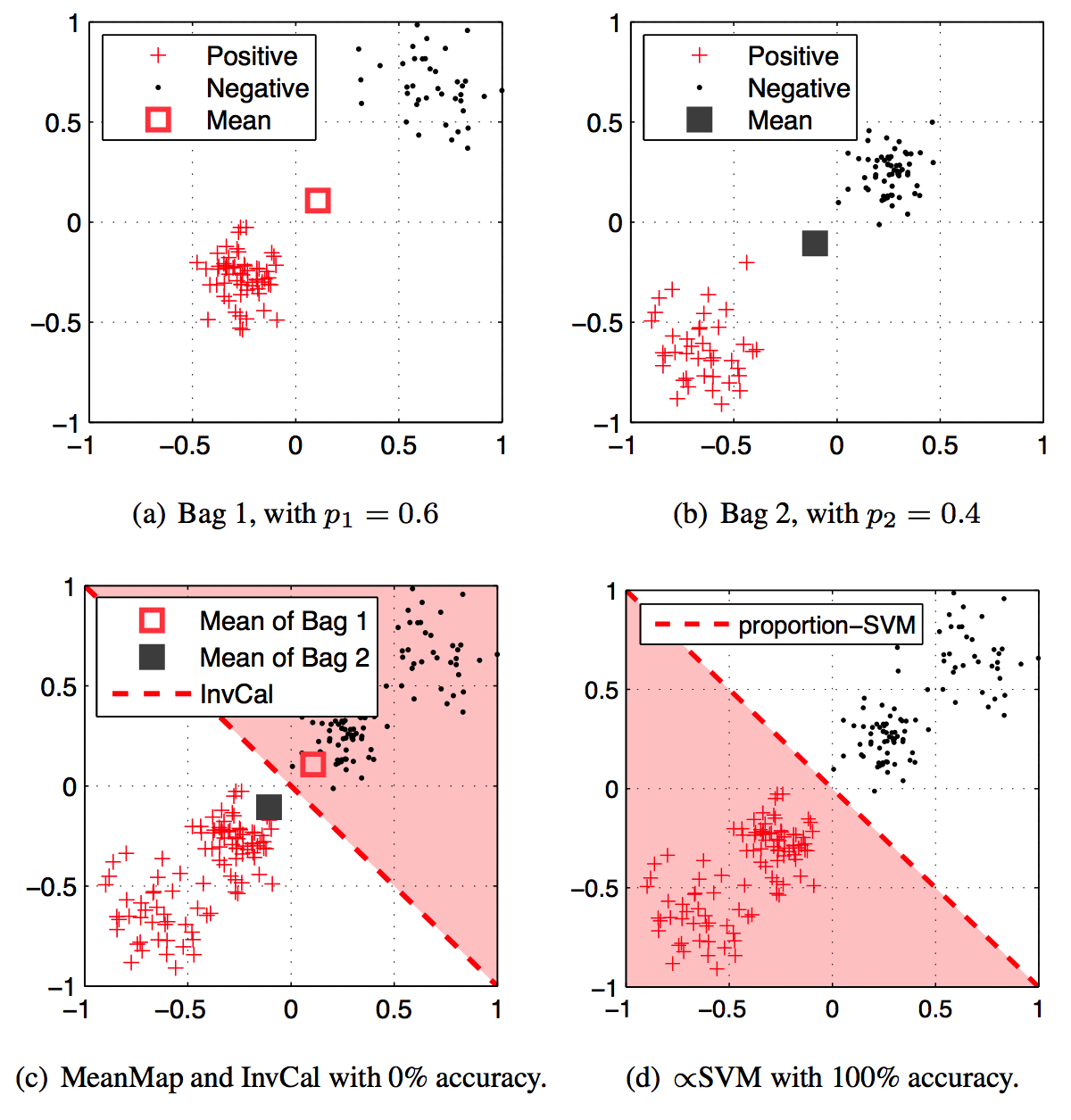
$\propto$SVM for learning with label proportions. Felix X. Yu, Dong Liu, Sanjiv Kumar, Tony Jebara, Shih-Fu Chang. In International Conference on Machine Learning (ICML) Atlanta, GA June, 2013 [PDF][Supp][arXiv][Slides] |
| |
We study the problem of learning with label proportions in which the training data is provided in groups and only the proportion of each class in each group is known. This learning setting has broad applications in data privacy, political science, healthcare, marketing and computer vision.
We propose a new method called proportion-SVM, or $\propto$SVM, pSVM, which explicitly models the latent unknown instance labels together with the known group label proportions in a large-margin framework. Unlike the existing works, the approach avoids making restrictive assumptions about the data. The $\propto$SVM model leads to a non-convex integer programming problem. In order to solve it efficiently, we propose two algorithms: one based on simple alternating optimization and the other based on a convex relaxation. Extensive experiments on standard datasets show that $\propto$SVM outperforms the state-of-the-art, especially for larger group sizes.
|
|
|
|
|
