4. Part 3: Add Support for Word Traceback and Skip Arcs to a Large-Vocabulary Decoder
In this part of the lab, we provide a nearly complete large vocabulary decoder, and you will need to add support for recording word traceback information as well as support for handling skip arcs, i.e., arcs with no output. However, we have done most of the work; these changes should involve adding/modifying only a few lines of code.
Now, we outline the basic functioning of the code. Recall the Viterbi algorithm we implemented for Lab 2:
C[0, start].vProb = 1
for t in [0 ... (T-1)]:
for s_src in [1 ... S]:
for a in outArcs(s_src):
s_dst = dest(a)
curProb = C[t, s_src].vProb * arcProb(a, t)
if curProb > C[t+1, s_dst].vProb:
C[t+1, s_dst].vProb = curProb
C[t+1, s_dst].trace = a
|
ViterbiLab4G in
Lab4_DP.C, which executes the Viterbi algorithm for
a single utterance. As mentioned in
[Lecture 8], it is not generally feasible to
store the whole dynamic programming
chart C[t, s] in large-vocabulary decoding.
Instead, we store only the active states
for the last and current frames. For each frame, we
store the active states in a FrameData structure.
We allocate two of these structures, and initially set
the variable lastFrame to point to one and
nextFrame to point to the other. For each iteration
in our outer loop over frames:
for (int frm = 0; frm <= numFrames; ++frm) |
Now, in Lab 2, we iterated over all states, but for LVCSR we can only iterate over active states. In addition, we must iterate over active states in topological order (relative to skip arcs) in order for the dynamic programming calculation to be correct, as mentioned in class. We handle this for you, using a data structure known as a [heap]. A heap holds a list of elements such that the top of the heap always holds the first element according to some ordering, in our case, the topological ordering. In the code, the loop over active states is implemented by first calling lastFrame->init_heap() to initialize the heap for active states in the last frame, and then doing
while ((curState = lastFrame->pop_heap())) |
To create/lookup a DP cell for a state, we
use the method insert_cell().
That is, we no longer preallocate all cells C[t, s] in the DP chart
for a frame t, and instead create cells on the fly as new active states
are created. For example, see the line
ChartCell& dstCell = nextFrame->insert_cell(dstState); |
ChartCell* dstCellPtr = &nextFrame->insert_cell(dstState); |
Now, the first task for Part 3 is to add backtrace updating; the
code as it stands only calculates the Viterbi probability but
not the best word sequence. Unlike in previous labs, we do not provide
BEGIN_LAB and END_LAB markers; you need to
figure out where to make the changes by yourself. Backtrace
information is stored in the wordTreeNodeM field of the
ChartCell structure. That is, in contrast to
[Lab 2] where we store the best incoming arc for each cell in
the chart, we now store the word sequence labeling the best
incoming path for each cell in the dynamic programming chart.
As described in class,
we encode the best word sequence as a single integer index that
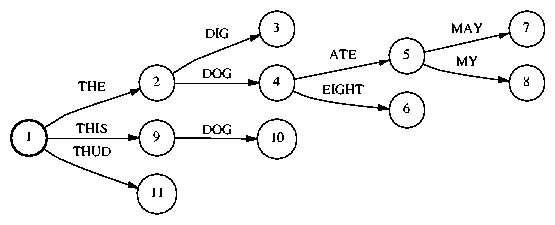
specifies a node in what we call a word tree. An example
word tree is depicted in Figure 1. The word
sequence associated with a node is the sequence of words
labeling the path from the root node to that node.
For example, with the word graph in Figure 1,
if a cell has a wordTreeNodeM value of 5, this signals
that the best path to this cell is labeled with the
word sequence THE DOG ATE.
For this part of the lab, you will need to set the
wordTreeNodeM field for all cells iterated over and
to update the word tree as you go, creating new nodes as needed.
The word tree is stored in a variable wordTree of
type WordTree.
(Note: In the code, the root has index 0 rather than 1 as in Figure 1.)
Initially, the word tree will consist of a single node, the root node.
To complete this task, you will need to access
the following method of WordTree:
wordTree.insert_node(prevNode, nextWord). This returns the index of
the node you arrive at if you extend the node prevNode with the
word nextWord (represented as an integer index),
creating the node if it doesn't already
exist. (Recall from Lab 3 that we can
represent word identities as integer indices.)
For example, wordTree.insert_node(5, nextWord) would return the
value 8 in the above example if nextWord corresponds to
the word MY. To find the word label residing on
an arc arcPtr, call the method arcPtr->get_label().
This returns the integer index of the word residing on the arc,
or 0 if there is no word label. Note: most arcs
do not have word labels on them.
To complete this task, you should need only write a few lines of code. Hint: if the best path into dstCell comes from curCell and the arc between them has no word label, how does the wordTreeNodeM value of dstCell compare to that of curCell? What if the arc between them does have a word label?
Your code will be compiled into the program DcdLab4, which is almost identical to the program DcdLab2 from [Lab 2], except that it links in the Lab 4 Viterbi implementation instead of the Lab 2 Viterbi implementation. To compile this program with your code, type
smk DcdLab4 |
lab4p3a.sh |
The target output can be found in the file p3a.out in ~stanchen/e6884/lab4/; you should match the decoded word sequence printed for each utterance. As usual, the -debug flag can be used to run the script in the debugger. The instructions in lab4.txt will ask you to run the script lab4p3b.sh, which does the same thing as lab4p3a.sh except on a different test set.
For the second task of this part, you need to add support for skip arcs, i.e., arcs with no output. That is, the code as is will not work correctly if skip arcs are present, and you need to find the fix that will make the code work correctly. Note that in the loop over arcs in the code, the variable hasOutput will be false for skip arcs. For this part, you need only change a single line of code; the code is designed so that the obvious change will result in the correct behavior. Again, you need to recompile DcdLab4 to test your change:
smk DcdLab4 |
lab4p3c.sh |