|
|
Research
Semantic Concept Detection by Multi-Modal Learning
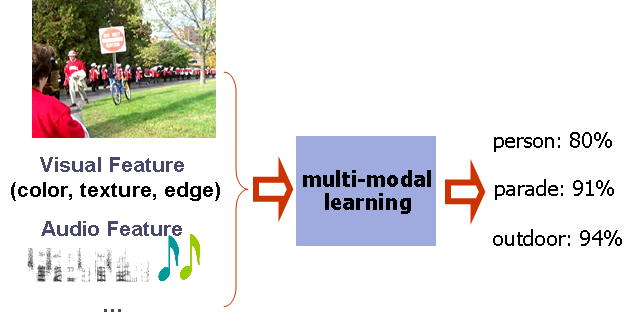
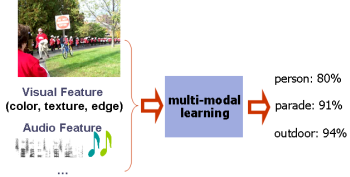
| Semantic concept detection in images and videos has become an increasingly
critical issue for organizing, browsing, and retrieving multimedia assets.
Traditional approaches mainly focus on visual aspects, i.e., extracting
visual features to train various concept detectors. Besides visual modality,
others like audio modality and textual modality are also indispensable
for effective multimedia classification. Our goal is to develop multi-modal
learning algorithms that can utilize the advantages of different modalities
for better semantic concept detection.
Project Link
|
 |
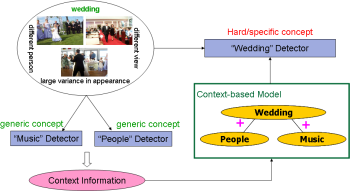
Semantic Concept Detection by Cross Concept Learning
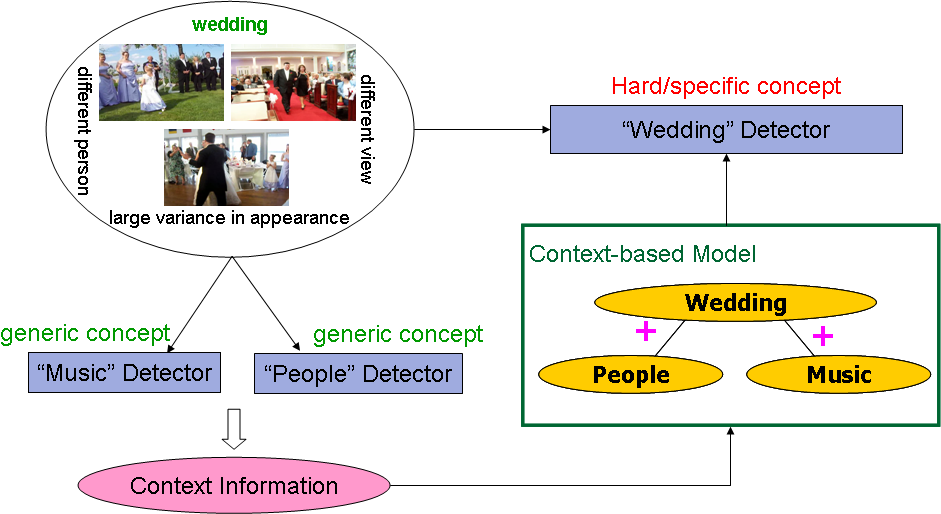
| Semantic concepts usually do not occur in isolation, and the contextual
relationships provide important information for automatic concept detection
in images/videos. Unlike traditional approaches that independently build binary
classifiers to detect individual concepts, we develop algorithms that consider
inter-conceptual relationships.
Project Link
|
 |
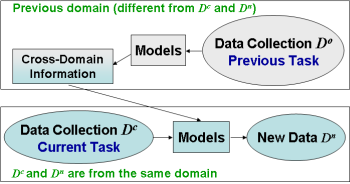
Semantic Concept Detection by Cross Domain Learning
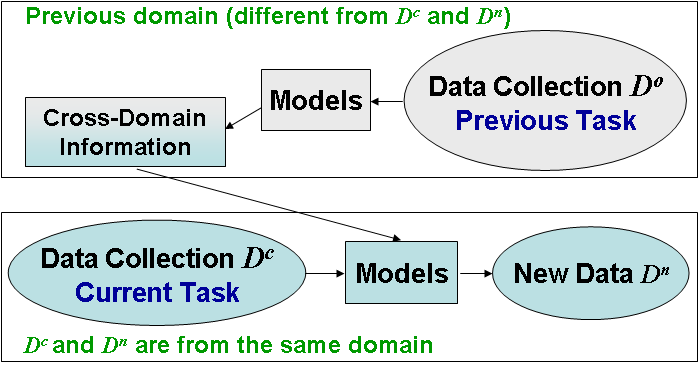
| Exploding amounts of multimedia data increasingly require automatic indexing and
classification, e.g., training classifiers to produce high-level features,
or semantic concepts, chosen to represent image content, like car, person,
etc. When changing the applied domain (e.g., from the news domain to consumer
home videos), the classifiers trained in one domain often perform poorly in
the other domain due to changes in feature distributions. Additionally, classifiers
trained on the new domain alone may suffer from too few positive training samples.
Appropriately adapting data/models from an old domain to help classify data in a new
domain is an important issue.
Project Link
|
 |
High-Level Feature Extraction for NIST TRECVID
| The high-level feature extraction task aims at
detecting semantic concepts from video shots, including objects like car, building,
scenes like waterscape-waterfront, events like parade & demonstration, etc. For
each video shot, a probability hypothesis is given for each concept indicating the
chance of concept occurrence. Accordingly for each concept, video shots are ranked
based on these probabilities in descending order. Precision values at different recall
positions are calculated for evaluation.
Official TRECVID Website: http://www-nlpir.nist.gov/projects/trecvid
Project Link
|
|