Part-based Object/Scene Detection by Learning
Random Attributed Relational Graph (RARG)
Motivation and Introduction

Due to the popularity of digital cameras and camcorders, we have witnessed
the dramatic increase of visual content such as photos and videos in recent
years. The exponential accumulation of content calls for the need of efficient
and accurate indexing and search of visual contents. Users usually are
more interested in searching photos and videos in the semantic level instead
of the traditional visual feature level. Semantic visual indexing therefore
tries to index visual content by tagging photos or video segments with
semantic labels, known as visual concepts, which include single or composite
objects, visual scenes, events, or their compositions. Due to the large
number of visual concepts for indexing, it is necessary to enable the
system to automatically learn the concept models from training data, instead
of designing them manually by researchers.
We have developed a novel model called Random Attributed Relational Graph
for part-based static concept (object and scene) detection. The model
extends the traditional Attributed Relational Graph or Random Graph by
attaching the graph with random variables, which are used to capture the
statistics of part appearance features and part relational features. Random
Attributed Relational Graphs can be learned from the training images in
an unsupervised manner (i.e. no need to label the parts), and offers high
accuracy of detecting objects and scenes and higher learning speed than
the previous methods.
The Random Attributed Relational Graph
model
![]()
Random Attributed Relational Graph (RARG) is the extension of the Attributed Relational Graph or Random Graph by attaching the vertexes and edges of a graph with random variables. The probability density functions or mass functions of the random variables are used to capture the statistics of the part appearances and part relations.
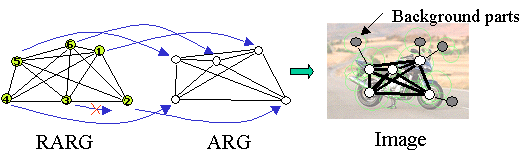
If we represent an object or image as an Attributed Relational Graph, then an object is an instance generated from a RARG, and an image can be represented as an ARG formed by generating the object instance from the RARG and then adding additional background parts. This generation process is illustrated below.
 |
||
|
A simplified generation process for generating
the part-based representation of an image
|
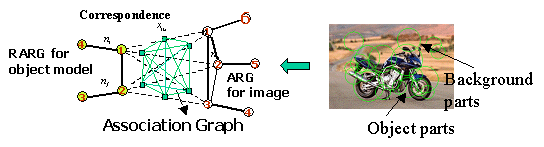
Based on this generative framework, object detection problem therefore is reduced to a likelihood test problem. We need to calculate the generation likelihood and learn the parameters of the above generative process. In our paper, we show that we can reduce the likelihood calculation to a binary pairwise MRF defined on the association graph between the RARG and ARG (Figure below). The generation likelihood is shown to be related to the partition functions of the MRFs. Because the log partition function of a MRF has variational representation, we can realize the likelihood computation by variational inference (for example, Loopy Belief Propagation) and learning parameters by variational Expectation-Maximization (EM).
 |
||
|
The association graph on which the binary pairwise
MRF is defined
|
Multi-view Object Detection
![]()
In order to extend the sing-view object detection to the multi-view object detection, we have developed a Mixture of RARG (MOR) model. In the MOR, each component RARG capture the statistics of an object view. The detection likelihood then becomes the linear combination of the detection likelihood of the individual RARG.
Besides the MOR model, we also explored the use of SVM plus fisher kernel for multi-view object detection. Different from the MOR model, the SVM fisher kernel method captures the statistics of an object view using a set of support vectors. The fisher kernel approach only learns one single RARG model, and realize the detection by mapping the input ARG into the tangent space of the RARG likelihood manifold. The SVM based approach can alleviate the overfitting problem encountered in the MOR model for learning the mixture coefficients, and greatly increases the detection and learning speed.
 |
||
|
Multi-view objects (images are from web)
|
Experiments
![]()
We compare the performance of our system with the constellation model developed by the Oxford and Caltech computer vision group. The constellation is considered as the state-of-the-art method in the community. We use the same image data sets. We achieved a comparable detection performance with significantly increased learning speed. The learning speed of our system is more than 2 times faster than the constellation model using Gibbs sampling, and more than 5 times faster using the Loopy Belief Propagation approach, either measured by the learning iteration number or the total learning time.
For the multi-view object detection, we have built up our own data set by searching the goolge and altavista image search engine. By using the Mixture of RARG model, we improved the performance of the single RARG model by about 5 percent.
People
![]()
Publication
![]()
Dongqing Zhang, Shih-Fu Chang. A Generative-Discriminative Hybrid Method for Multi-View Object Detection. In IEEE CVPR, New York City, New York, June 2006. (PDF)
Dongqing Zhang. Statistical Part-Based Models: Theory and Applications in Image Similarity, Object Detection and Region Labeling. PhD Thesis Graduate School of Arts and Sciences, Columbia University, 2005. (PDF)
Dongqing Zhang, Shih-Fu Chang. Learning Random Attributed Relational Graph for Part-based Object Detection. ADVENT Technical Report #212-2005-6 Columbia University, May 2005. (PDF)
Dong-Qing Zhang and Shih-Fu Chang, "Detecting Image Near-Duplicate by Stochastic Attributed Relational Graph Matching with Learning", ACM conference of Multimedia 2004, (ACM MM). (PDF)
Dong-Qing Zhang and Shih-Fu Chang, "Stochastic Attributed Relational
Graph Matching for Image Near-Duplicate Detection", Columbia University
ADVENT Technical Report #206-2004-6 Columbia University, October 2004.
(PDF)
Related Projects
![]()