
Concept-Based Video Search with Flickr Context Similarity

Summary
Automatic video search based on pre-trained semantic concept detectors has recently received significant attention. Since the number of available detectors is much smaller than the size of human vocabulary, one major challenge is to select appropriate (relevant) detectors to response textual user queries. In this project, we propose to exploit the context information associated with Flickr images to estimate query-detector similarity, instead of utilizing WordNet-based ontological measurements as most existing works. Our measurement, named Flickr context similarity (FCS), reflects the co-occurrence statistics of words in image context rather than the textual corpus (e.g., dictionaries or textual documents on the Web). Experiments on the TRECVID datasets using 100+ queries show that the FCS is suitable for measuring the query-detector similarity, producing better performance than several other popular measurements.
Background and Motivation
Recent advances in multimedia research have shown encouraging progress in
using a set of intermediate descriptors, namely semantic concept
detectors, to bridge the semantic gap between textual user queries and
low-level visual features. The detectors are classifiers that
automatically index the video contents with generic semantic concepts,
such as tree and water-scene. The indexing of these
concepts allows users to access a video database by textual queries. In
the search process, video clips which are most likely to contain the
concepts semantically related to the query words are returned to the
users. This video retrieval scenario is commonly referred to as
concept-based video search, as displayed in Figure 1.
|
Figure 1: Concept-based video search framework. The semantic concept detectors serve as an intermediate layer to bridge the semantic gap. The proposed Flickr context similarity is used (in the knowledge source layer) to select suitable concept detectors for each textual user query given on-the-fly. |

However, due to the lack of manually labeled training samples and the
limitation of computational resources, the number of available concept
detectors to date remains in the scale of hundreds, which is much
smaller compared to the size of human vocabulary. Therefore, one open
issue underlying this search methodology is the selection of appropriate
detectors for the queries, especially when direct matching of words
fails. For example, given a query find video shots of something
burning with flames visible, explosion_fire and smoke
are probably suitable detectors. Different from most existing works in
which semantic reasoning techniques based on the WordNet ontology were
used for detector selection, here we explore context information
associated with Flickr images for better query-detector similarity
estimation. This measurement, named Flickr context similarity (FCS), is
grounded on the co-occurrence statistics of two words in the context of
images (e.g., tags, title, descriptions etc.), and is therefore able to
reflect
word co-occurrence in image context rather than textual corpus. This
advantage of FCS enables a more appropriate selection of detectors for
searching image and video data. For example, two words bridge and
stadium have high semantic relatedness in WordNet, since both of
them are very close to a common ancestor construction in the
WordNet hierarchy. However, when a user issues a query find shots of
a bridge, stadium is obviously not a helpful detector since
it rarely co-occurs with bridge in images/videos. While for the
same query, our proposed FCS is able to suggest a more suitable detector
river.
Flickr Context Similarity
Given two words x and y, we query both words against Flickr images (via its API) separately and jointly (x AND y). Let f(x) denote the total number of images in Flickr containing word x in its context (e.g., title, tags, descriptions, and etc.), we first compute the distance of both words based on the definition of normalized Google distance (Cilibrasi and Vitanyi, IEEE TKDE 2007):
|
|

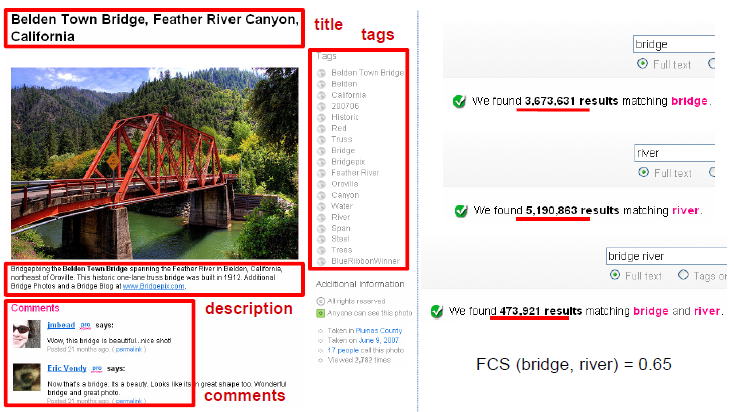
where f(x,y) is the number images with context containing both x and y, and N is the total number of images on Flickr (roughly estimated as 3.5 billion at the time we did the experiments). Notice that we search against all kinds of Flickr image contexts (not just the tags, as shown in the Figure below).
The word distance is then converted to a similarity value by a Gaussian kernel:
|
|
where ρ is a kernel width parameter.
|
Figure 2: Left. Rich context information associated with a Flickr image. Right. The total number of images returned using keyword-based search in Flickr image context. |
Experimental Results
We evaluate FCS using 100+ queries on the TRECVID video data sets. Table 1 shows the selected detectors for a few example queries, where our FCS is able to select more suitable detectors. For example, FCS selects 'Railroad' for the query term 'train', while WUP and NGD select 'Vehicle' and 'Car' respectively. Obviously 'Railroad' is a better detector for searching 'train' since they frequently co-occur with each other.
Figure 3 further compares FCS with other query-detector measurements based on WordNet and Web documents (NGD computed based on results from Yahoo web search API). FCS consistently shows better performance in terms of mean average precision over the queries evaluated in TRECVID 2005-2008.
 Table 1: Detector selection using various query-detector similarity measurements, including WUP based on WordNet hierarchy, NGD based on textual Web documents (via Yahoo search API), and our FCS based on Flickr context. The detectors are selected according to the query words shown in bold ('goal', 'flames', 'scenes', and 'train' respectively from each of the queries). |
|
Figure 3: Search performance comparison using various query-detector similarity measurements. Resnik, JCN, WUP, and Lesk are all based on the WordNet lexicon/hierarchy. Results are shown in terms of mean average precision over the queries used in the official TRECVID evaluations 2005-2008 (TV05-08). |

People
Publications
-
Yu-Gang Jiang, Chong-Wah Ngo, Shih-Fu Chang, Semantic Context Transfer across Heterogeneous Sources for Domain Adaptive Video Search, ACM Multimedia (ACM MM), Beijing, China, October 2009. [pdf]
- Yu-Gang Jiang, Akira Yanagawa, Shih-Fu Chang, Chong-Wah Ngo. CU-VIREO374: Fusing Columbia374 and VIREO374 for Large Scale Semantic Concept Detection. In Columbia University ADVENT Technical Report #223-2008-1, August 2008. [pdf]
Related Projects
- Download: CU-VIREO374: Fusing Columbia374 and VIREO374 for Large Scale Semantic Concept Detection
- Download: VIREO-374: Keypoint-Based LSCOM Semantic Concept Detectors
- Domain Adaptive Semantic Diffusion for Large Scale Context-Based Video Annotation
- Columbia University's TRECVID-2008 Semantic Visual Concept Detection System
For problems or questions
regarding this web site contact The
Web Master.
Last updated: Oct. 30th, 2009.