Columbia University's TRECVID-2008 Semantic Visual Concept Detection System

Overview
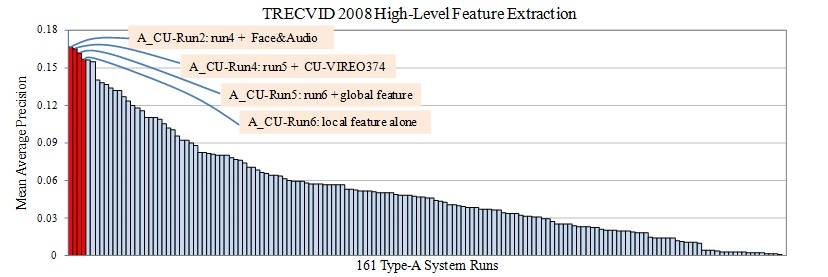
We participated in the 2008 TREC video retrieval evaluation (TRECVID). This page describes the technical components of our semantic visual concept detection (a.k.a. high-level feature extraction) system, which achieved the top performance among all 161 type-A submissions worldwide. Figure 1 shows the evaluation results.
|
Figure 1: Performance of our submitted type-A runs (red bars) and all 161 official type-A semantic concept detection submissions (Type-A is the most popular result category in TRECVID where only the officially provided training data and annotations are allowed to use). |
Our aim for the semantic visual concept detection task is to answer the following questions. What's the performance edge of local features over global features? How can one optimize design choices for systems using local features (vocabulary size, weighting etc)? Does cross-domain learning using external Web images help? Are concept-specific features (like face and audio) needed? Our findings indicate that a judicious approach using local features alone (without Web images or audio/face features) already achieves very impressive results, with a MAP (mean average precision) at 0.157. The combination of local features and global features introduces a moderate gain (MAP 0.162). The addition of training images from the Web provides intuitive benefits, but is accompanied by complications due to unreliable labels and domain differences. We developed and evaluated methods for addressing such issues and showed noticeable improvement especially for concepts that suffer from scarce positive training samples. Special features such as the presence of faces or audio are shown useful for concepts such as two-people and singing respectively, but do not improve other concepts (MAP 0.167). We found that detection methods based on local features and spatial layouts have converged to a mature solution for concept detection, and its combination with simple yet effective global features may be recommended for the concept detection task, as confirmed by its top performance shown in TRECVID 2008. In contrast to this maturity, learning from cross-domain or Web resources remains an attractive but unfulfilled research direction.
TRECVID is an open forum for encouraging and evaluating new research in
video retrieval. It features a benchmark activity sponsored annually, since
2001, by the National Institute of Standards and Technology (NIST). More
details about the evaluation procedures and outcomes can be found at the
NIST TRECVID site.
Technical Components
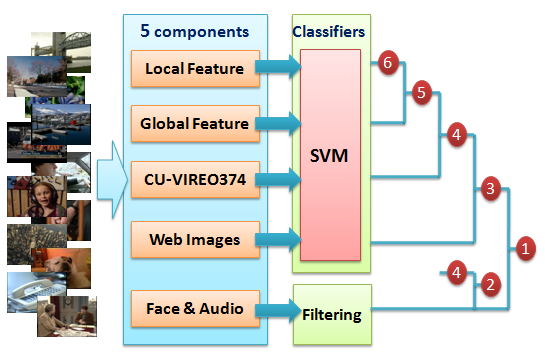
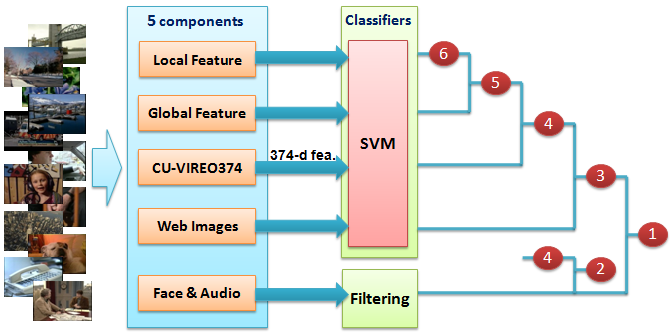
Figure 2 shows the overview of our visual concept detection system, which contains five major components: 1) local feature; 2) global feature; 3) CU-VIREO374; 4) training from Web images; and 5) special features from face and audio. Among the five components, local feature contributed most, and each of the other components incrementally improved the detection performance. For the first four components, we use SVM to train models separately, while the last component, face and audio, is used as a filtering step to rerank SVM classification results for only two concepts singing and two-people. Outputs of different SVMs are combined using average fusion.
We briefly describe each of the components below.
|
Figure 2: System overview. Our system contains five major components, based on which we submitted 6 result runs (run 1 and run 3 do not belong to Type-A since additional training images from the Web are used). |
Local Feature (Bag-of-Visual-Words):
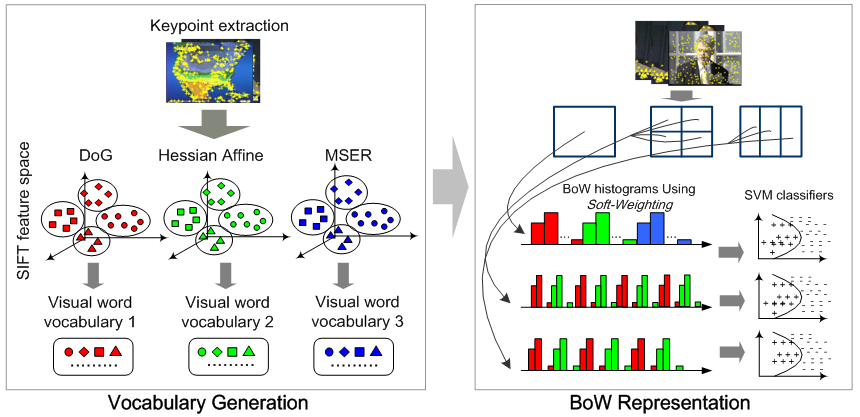
As mentioned above, local feature is the most important component in our system. We follow the popular bag-of-visual-words (BoW) framework, which has shown excellent results in many visual recognition/retrieval applications. The performance of BoW in semantic concept detection in large-scale multimedia corpus, however, strongly depends on several representation choices, such as visual vocabulary size, visual word weighting scheme, spatial information, and etc. We therefore conducted a comprehensive study of these representation choices for semantic visual concept detection, and designed an image (video frame) representation framework based on our empirical findings, which is shown in Figure 3. We used three local keypoint detectors (DoG, Hessian Affine, and MSER), and a visual vocabulary of 500 visual words is generated for each type of the keypoints. To model the spatial location of the keypoints, video frames are divided into uniform-sized grids at different granularities. In particular, we use a soft-weighting scheme to generate BoW histograms, which significantly improves the detection performance by 10-15% in most cases. In the SVM classifiers, Chi-square RBF kernel is used instead of the traditional Gaussian RBF kernel.
|
Figure 3: Framework of our local feature based image (video frame) representation. |
Global Feature:
In addition to the local features, we also chose two types of global features: 1) grid-based color moments (225-d); and 2) grid-based wavelet texture (81-d). The color moments feature is computed in Lab color space over 5*5 grid partition, and we used the first three moments for each color channel. For the wavelet texture, we used 3*3 grids and each grid is represented by the variances in 9 Haar wavelet sub-bands. One SVM classifier (Gaussian RBF kernel) is trained for each concept using each of the global features.
CU-VIREO374:
CU-VIREO374 provides fused detection scores of
Columbia374 and
VIREO-374 on
recent TRECVID datasets (374 semantic concepts). With the fused detection
scores, each video frame can be described as a 374-dimensional feature
vector. Then a SVM classifier is trained for each of the concepts evaluated
in TRECVID2008. This is analogous to the way of training other SVM
classifiers using the local and global features. Different from the
local/global features, this 374-d feature can be viewed as a higher level
representation with each dimension indicating the (noisy) probability of
presence of a semantic concept.
Training from Web Images:
One important problem in concept detection is the scarcity
of positive training samples for many concepts. Often for concepts with very
few positive samples, no classification method can achieve satisfactory
results. Manually labeling a large image dataset is too expensive; however,
there are billions of weakly annotated Web images freely available online.
Although most Web images are not well-labeled, many of them contain
metadata, from which we can obtain partial tagging information, i.e., 'noisy
labels'. So one interesting problem for concept detection is how to make use
of the large amount of 'noisily labeled' Web images.
We collected around 18,000 images from Flickr, using the name of each of
the evaluated concepts as a query. There are two major challenges in using
these Web images to improve the detection performance on the TRECVID data:
1) how to filter the Web images and remove the false positive samples; 2)
the Web images and the TRECVID images are not from the same domain (Figure
4), and
hence another challenge is how to alleviate the effect of domain changes? In
this work, we tried several potential solutions, and used graph-based
semi-supervised learning for positive sample filtering, and weighted SVM for
learning from Web-images, where each training sample is weighted based on
its estimated domain difference to the target TRECVID data.
|
Figure 4: Significant domain difference between Flickr images and TRECVID video frames (for concept airplane). |

Face & Audio:
'Face Detection' and 'Speech/Music/Singing Detection' are two techniques that were explored
separately in
the literature to index people presence and activities in multimedia
documents. In this work, these are analyzed to determine the
impact they introduce on generic high-level feature detection methods.
Particularly, we used the techniques developed at IRIT laboratory for
reranking results of two-people and singing concept detectors
(outputs of the SVM classifiers).
Two-people detection: Human face is now relatively simple to detect
or
localize. Here we use the well-known object detection
method of Viola-Jones to detect both frontal and
profile faces in the video frames. Moreover, clothing detection from histograms
comparison and skin detection by a 2D-Gaussian color model are
applied to form a temporal forward/backward tracking algorithm. Figure 5
illustrates the tracking process, which
helps to detect people in neighboring frames where face detectors failed.
Based on the face detection and the tacking algorithm, video shots that are
likely to contain two detected people are assigned with higher scores than
the initial SVM-based predictions.
Singing detection: Audio features are more suitable
for detecting this concept. We explore two features: Vibrato and Harmonic Coefficient. The Vibrato is the
variation of the frequency of an instrument or human voice. It can identify particular voiced segments, which
appear only during singing
(not during speech). The Harmonic Coefficient is a parameter that
indicates the most important trigonometric series representing the audio
spectrum. It has been proven that this coefficient is higher in the presence
of singing. Similar to the detection of two-people, video shots
having higher values of these two audio features are assigned with higher
prediction score for concept singing.
|
Figure 5: Face detection and tracking. We used Viola-Jones face detector for initial detection and then performed tracking based on both clothing and skin color. |

People
- Shih-Fu Chang, Yu-Gang Jiang, Elie El Khoury, Junfeng He, Chong-Wah Ngo.
- We acknowledge AT&T research lab for providing their detected shot boundaries over the TRECVID2008 test dataset.
Related Publications
-
S.-F. Chang, J. He, Y.-G. Jiang, E. El Khoury, C.-W. Ngo, A. Yanagawa, E. Zavesky. Columbia University/VIREO-CityU/IRIT TRECVID2008 High-Level Feature Extraction and Interactive Video Search. In NIST TRECVID Workshop, Gaithersburg, MD, November 2008. [pdf]
- Y.-G. Jiang, A. Yanagawa, S.-F. Chang, C.-W. Ngo. CU-VIREO374: Fusing Columbia374 and VIREO374 for Large Scale Semantic Concept Detection. In Columbia University ADVENT Technical Report #223-2008-1, August 2008. [pdf]
Related Projects
- Download: CU-VIREO374: Fusing Columbia374 and VIREO374 for Large Scale Semantic Concept Detection
- Columbia University at TRECVID 2006: Semantic Visual Concept Detection and Video Search
- Domain Adaptive Semantic Diffusion for Large Scale Context-Based Video Annotation
- Concept-Based Video Search with Flickr Context Similarity
- CuZero: Guided Search for Zero-Latency Interaction with Diverse Content
For problems or
questions regarding this webpage please contact the
Web Master.
Last updated: April 2010.