Domain Adaptive Semantic Diffusion for Large Scale Context-Based Video Annotation

Summary
Learning to cope with domain change has been known as a challenging problem in many real-world applications. We propose a novel and efficient approach, named domain adaptive semantic diffusion (DASD), to exploit semantic context while considering the domain-shift-of-context for large scale video concept annotation. Starting with a large set of concept detectors, the proposed DASD refines the initial annotation results using graph diffusion technique, which preserves the consistency and smoothness of the annotation over a semantic graph. Different from the existing graph learning methods which capture relations among data samples, the semantic graph treats concepts as nodes and the concept affinities as the weights of edges. Particularly, the DASD approach is capable of simultaneously improving the annotation results and adapting the concept affinities to new test data. The adaptation provides a means to handle domain change between training and test data, which occurs very often in video annotation task. We conduct extensive experiments to improve annotation results of 374 concepts over 340 hours of videos from TRECVID 2005-2007 data sets. Results show consistent and significant performance gain over various baselines. In addition, DASD is very efficient, completing diffusion over 374 concepts within just 2 milliseconds for each video shot on a regular PC.
Background and Motivation
Annotating large scale video data with semantic concepts has been a popular topic in computer vision and multimedia research in recent years. The predefined concepts may cover a wide range of topics such as those related to objects (e.g., car, airplane), scenes (e.g., mountain, desert), events (e.g., people marching) etc. Existing studies in image and video annotation mainly aim at the assignment of single or multiple concept labels to a target data set, where the assignment is often done independently without considering the inter-concept relationship. Due to the fact that concepts do not occur in isolation (e.g., smoke and explosion), more research attentions have been paid recently for improving annotation accuracy by learning from semantic context. Nevertheless, the learning of contextual knowledge is often conducted in an offline manner based on training data, resulting in the classical problem of over fitting. For large scale video annotation which could involve simultaneous labeling of hundreds of concepts, the problem becomes worse when the unlabeled videos are from a domain different from that of the training data. This brings two challenges related to scalability: the need for adaptive learning and the demand for efficient annotation.
To achieve these dual goals, we propose a novel and efficient approach for improving large scale video semantic annotation using graph diffusion technique. Our approach, named domain adaptive semantic diffusion (DASD), uses a graph diffusion formulation to enhance the consistency of concept annotation scores. First, we construct an undirected and weighted graph, namely semantic graph, to model the concept affinities (semantic context). The graph is then applied to refine concept annotation results using a function level diffusion process, named semantic diffusion (SD). To handle the domain change problem, DASD further allows to simultaneously optimize the annotation results and adapt the concept affinities according to the test data distribution. Figure 1 gives an idealized example of DASD.
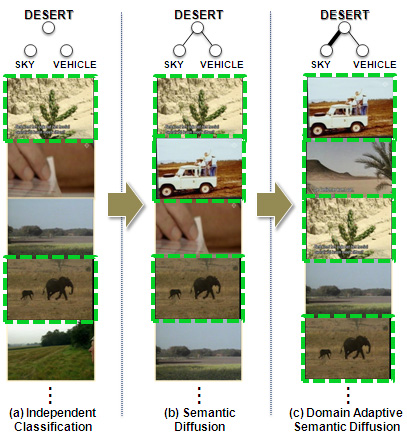
| Figure 1: Illustration of context-based video annotation. (a) Top 5 video shots of concept desert according to the annotation scores from an existing pre-trained detector, in which the semantic context was not considered. (b) Refined shot list by semantic diffusion. The subgraph on the top shows two concepts with higher correlations to desert. Line width indicates graph edge weight. (c) Refined subgraph and shot list by the proposed domain adaptive semantic diffusion (DASD). The graph adaptation process in DASD is able to refine the concept relationship which in turn can further help improve the annotation accuracy. |
Approach
The semantic graph is characterized by the relationship between concepts, i.e., the affinity matrix W. We estimate the concept relationship using TRECVID 2005 development set X and its corresponding label matrix Y, where yij=1 denotes the presence of concept ci in the sample xj , otherwise yij=0. The pairwise concept relationship (W) is computed using Pearson product moment correlation of the row vectors in Y.
Denote g(ci) as an annotation score vector of concept ci over a test set. Intuitively, the function values g(ci) and g(cj) should be consistent with the affinity between concepts ci and cj, i.e. Wij. In other words, strongly correlated concepts should have similar concept annotation scores. Motivated by this semantic consistency, here we formulate this problem as a graph diffusion process and define a cost function on the semantic graph as:
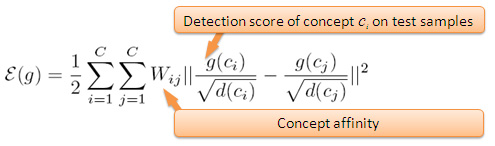
|
Apparently, this cost function evaluates the smoothness of the function g over the semantic graph. Reducing the function value makes the annotation results more consistent with the concept relationships. Specifically, as shown in the following equation, our objective is to reduce ε by updating g and W iteratively. The modification of g makes it more consistent with the concept affinities, while the refinement of W facilitates the domain adaptation of the semantic context.
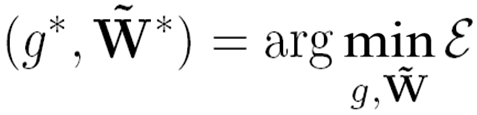
|
Experiments and Results
We evaluate the approach against TRECVID 2005--2007 video data sets. The data sets were used in the annual TRECVID benchmark evaluation by NIST. In total, there are 340 hours of video data. The videos are partitioned into shots and one or more representative keyframes are extracted from each shot. The 2005 and 2006 videos are broadcast news from different TV programs in English, Chinese and Arabic, while the 2007 data set consists mainly of documentary videos in Dutch.
We use the publicly available VIREO-374 as baseline, which includes SVM models of 374 LSCOM concepts. These models have been shown in TRECVID evaluations to achieve top performance. A semantic graph with 374 nodes is built using mannual labels on the TRECVID 2005 development set. In our experiments, for TRECVID 2005, we adopt the development set as our target database and report performance of 39 concepts. The development set is partitioned into training, validation and test sets. For TRECVID 2006 and 2007, we report performance of the 20 official evaluated concepts on each year's test set.
Table 1 shows the results, achieved by the VIREO-374 baseline, the semantic diffusion (SD, without graph adaptation), and the DASD. When SD is used, the performance gain ranges from 11.8% to 15.6%. DASD further boosts the performance for TRECVID 2006 and 2007 data sets. There is no improvement from DASD for TRECVID 2005 since the graph was built using manual labels on the same data set. These results confirm the effectiveness of our approach by formulating graph diffusion for improving video annotation accuracy. Figure 2 demonstrates the adaptation process of a fraction of the semantic graph. Figure 3 further gives per-concept performance of the 20 evaluated concepts in TRECVID 2006. Our approach consistently improves all the concepts.
DASD is highly efficient. The complexity is O(mn), where m is the number of concepts and n is the number of test video shots/frames. On TRECVID 2006 data set which contains 79,484 video shots, DASD finishes in just 165 seconds. In other words, running DASD over 374 concepts for each video shot only takes 2 milliseconds.
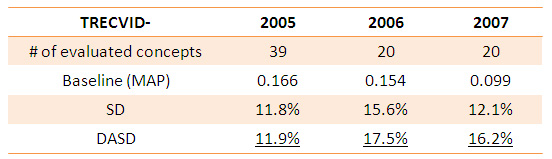 Table 1: Overall performance gain (relative improvement) on TRECVID 2005-2007 data sets. SD: semantic diffusion. DASD: domain adaptive semantic diffusion. |
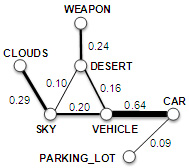
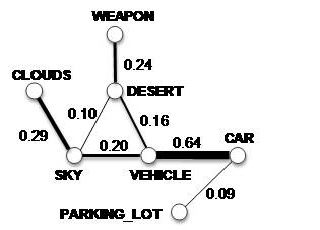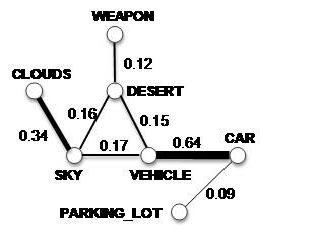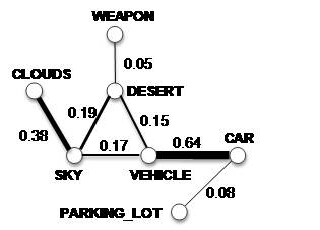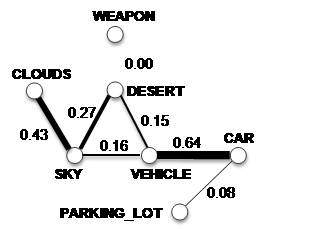 Figure 2: A fraction of the semantic graph. The animation shows the adaptation process of concept affinities from broadcast news videos to documentary videos. |
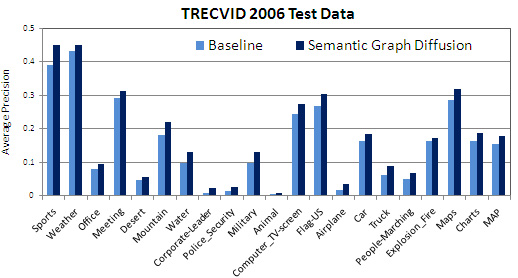 Figure 3: Per-concept performance before and after semantic diffusion on TRECVID 2006 test set. Consistent improvments are observed for all of the 20 semantic concepts. |
People
Publications
-
Yu-Gang Jiang, Qi Dai, Jun Wang, Chong-Wah Ngo, Xiangyang Xue, Shih-Fu Chang. Fast Semantic Diffusion for Large Scale Context-Based Image and Video Annotation. IEEE Transactions on Image Processing, 2012.[pdf]
-
Yu-Gang Jiang, Jun Wang, Shih-Fu Chang, Chong-Wah Ngo. Domain Adaptive Semantic Diffusion for Large Scale Context-Based Video Annotation. In IEEE International Conference on Computer Vision (ICCV), Kyoto, Japan, September 2009. [pdf]
- Yu-Gang Jiang, Akira Yanagawa, Shih-Fu Chang, Chong-Wah Ngo. CU-VIREO374: Fusing Columbia374 and VIREO374 for Large Scale Semantic Concept Detection. In Columbia University ADVENT Technical Report #223-2008-1, August 2008. [pdf]
Source Code
- Matlab source code can be downloaded from here. VIREO-374 detection scores on TRECVID 2006 test set along with the constructed semantic graph are also included in the download package. Users can run the demo script to see how to use this program.
Related Projects
- Download: CU-VIREO374: Fusing Columbia374 and VIREO374 for Large Scale Semantic Concept Detection
- Download: VIREO-374: Keypoint-Based LSCOM Semantic Concept Detectors
- Graph Transduction via Alternating Minimization (GTAM)
- CuZero: Guided Search for Zero-Latency Interaction with Diverse Content
For problems or questions
regarding this web site contact The
Web Master.
Last updated: Oct. 30th, 2009.