In this section, the basic mechanisms involved in transforming a speech waveform into a sequence of parameter vectors will be described. Throughout this section, it is assumed that the SOURCEKIND is WAVEFORM and that data is being read from a HTK format file via HWAVE. Reading from different format files is described below in section 5.8. Much of the material in this section also applies to data read direct from an audio device, the additional features needed to deal with this latter case are described later in section 5.9.
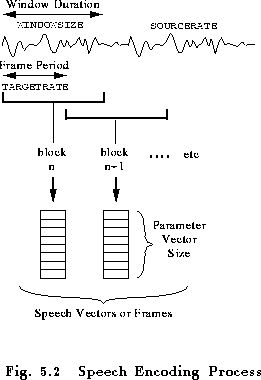
The overall process is illustrated in Fig. 5.2 which shows the sampled waveform being converted into a sequence of parameter blocks. In general, HTK regards both waveform files and parameter files as being just sample sequences, the only difference being that in the former case the samples are 2-byte integers and in the latter they are multi-component vectors. The sample rate of the input waveform will normally be determined from the input file itself. However, it can be set explicitly using the configuration parameter SOURCERATE. The period between each parameter vector determines the output sample rate and it is set using the configuration parameter TARGETRATE. The segment of waveform used to determine each parameter vector is usually referred to as a window and its size is set by the configuration parameter WINDOWSIZE. Notice that the window size and frame rate are independent. Normally, the window size will be larger than the frame rate so that successive windows overlap as illustrated in Fig. 5.2.
For example, a waveform sampled at 16kHz would be converted into 100 parameter vectors per second using a 25 msec window by setting the following configuration parameters.
SOURCERATE = 625
TARGETRATE = 100000
WINDOWSIZE = 250000
Remember that all durations are specified in 100 nsec units .
.
Independent of what parameter kind is required, there are some simple
pre-processing operations that can be applied prior to performing the actual
signal analysis.
Firstly, the DC mean can be removed from the source waveform by setting the
Boolean configuration parameter
ZMEANSOURCE to true
(i.e. T). This is useful when
the original analogue-digital conversion has added a DC offset to the
signal. It is applied to each window individually so that it can be
used both when reading from a file and when using direct audio
input.
Secondly, it is common practice to pre-emphasise the signal by applying the first order difference equation
to the samples
![]() in each window. Here k is the
pre-emphasis coefficient which should be in the range
in each window. Here k is the
pre-emphasis coefficient which should be in the range
![]() . It is specified using the configuration
parameter PREEMCOEF .
Finally,
it is usually beneficial to taper the
samples in each window so that discontinuities at the window
edges are attenuated. This is done by setting the
Boolean configuration
parameter USEHAMMING
to true.
This applies the following transformation to the samples
. It is specified using the configuration
parameter PREEMCOEF .
Finally,
it is usually beneficial to taper the
samples in each window so that discontinuities at the window
edges are attenuated. This is done by setting the
Boolean configuration
parameter USEHAMMING
to true.
This applies the following transformation to the samples
![]() in the window
in the window
When both pre-emphasis and Hamming windowing are enabled, pre-emphasis is performed first.
In practice, all three of the above are usually applied. Hence, a configuration file will typically contain the following
ZMEANSOURCE = T
USEHAMMING = T
PREEMCOEF = 0.97
Certain types of artificially generated waveform data can cause numerical
overflows with some coding schemes. In such cases adding a small amount of
random noise to the waveform data solves the problem. The noise is added
to the samples using
where RND() is a uniformly distributed random value over the interval [-1.0, +1.0) and q is the scaling factor. The amount of noise added to the data (q) is set with the configuration parameter ADDDITHER (default value 0.0). A positive value causes the noise signal added to be the same every time (ensuring that the same file always gives exactly the same results). With a negative value the noise is random and the same file may produce slightly different results in different trials.
One problem that can arise when processing speech waveform files obtained from
external sources, such as databases on CD-ROM, is that the
byte-order may be different to that used by the machine on
which HTK is running. To deal with this problem, HWAVE can perform
automatic byte-swapping in order to preserve proper byte order. HTK assumes
by default that speech waveform data is encoded as a sequence of 2-byte
integers as is the case for most current speech databases.
If the source format is known, then HWAVE will also make an assumption
about the byte order used to create speech files in that format. It then checks
the byte order of the machine that it is running on and automatically performs
byte-swapping if the order is different. For unknown formats, proper byte order
can be ensured by setting the configuration parameter
BYTEORDER to VAX if the
speech data was created on a little-endian machine such as a VAX or an IBM PC,
and to anything else (e.g. NONVAX) if the speech data was created on a
big-endian machine such as a SUN, HP or Macintosh machine.
The reading/writing of HTK format waveform files can be further controlled via the configuration parameters NATURALREADORDER and NATURALWRITEORDER. The effect and default settings of these parameters are described in section 4.9. Note that BYTEORDER should not be used when NATURALREADORDER is set to true. Finally, note that HTK can also byte-swap parameterised files in a similar way provided that only the byte-order of each 4 byte float requires inversion.