Many HTK tools, particularly recognition tools, can input speech waveform data directly from an audio device. The basic mechanism for doing this is to simply specify the source format as being HAUDIO following which speech samples will be read directly from the host computer's audio input device.
When using direct audio input , the input sampling rate may be set explicitly using the configuration parameter SOURCERATE, otherwise HTK will assume that it has been set by some external means such as an audio control panel. In the latter case, it must be possible for HAUDIO to obtain the sample rate from the audio driver otherwise an error message will be generated.
Although the detailed control of audio hardware is typically machine dependent, HTK provides a number of Boolean configuration variables to request specific input and output sources. These are indicated by the following table
| Variable | Source/Sink |
| LINEIN | line input |
| MICIN | microphone input |
| LINEOUT | line output |
| PHONESOUT | headphones output |
| SPEAKEROUT | speaker output |
The major complication in using direct audio is in starting and stopping the input device. The simplest approach to this is for HTK tools to take direct control and, for example, enable the audio input for a fixed period determined via a command line option. However, the HAUDIO/HPARM modules provides two more powerful built-in facilities for audio input control.
The first method of audio input control involves the use of an automatic energy-based speech/silence detector which is enabled by setting the configuration parameter USESILDET to true. Note that the speech/silence detector can also operate on waveform input files.
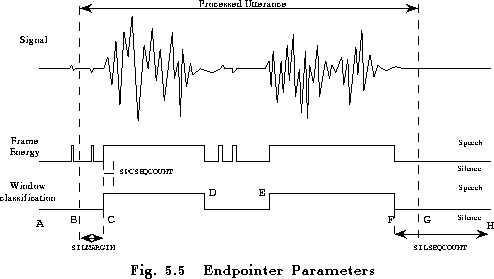
The automatic speech/silence detector uses a two level algorithm which first classifies each frame of data as either speech or silence and then applies a heuristic to determine the start and end of each utterance. The detector classifies each frame as speech or silence based solely on the log energy of the signal. When the energy value exceeds a threshold the frame is marked as speech otherwise as silence. The threshold is made up of two components both of which can be set by configuration variables. The first component represents the mean energy level of silence and can be set explicitly via the configuration parameter SILENERGY. However, it is more usual to take a measurement from the environment directly. Setting the configuration parameter MEASURESIL to true will cause the detector to calibrate its parameters from the current acoustic environment just prior to sampling. The second threshold component is the level above which frames are classified as speech (SPEECHTHRESH) . Once each frame has been classified as speech or silence they are grouped into windows consisting of SPCSEQCOUNT consecutive frames. When the number of frames marked as silence within each window falls below a glitch count the whole window is classed as speech. Two separate glitch counts are used, SPCGLCHCOUNT before speech onset is detected and SILGLCHCOUNT whilst searching for the end of the utterance. This allows the algorithm to take account of the tendancy for the end of an utterance to be somewhat quieter than the beginning. Finally, a top level heuristic is used to determine the start and end of the utterance. The heuristic defines the start of speech as the beginning of the first window classified as speech. The actual start of the processed utterance is SILMARGIN frames before the detected start of speech to ensure that when the speech detector triggers slightly late the recognition accuracy is not affected. Once the start of the utterance has been found the detector searches for SILSEQCOUNT windows all classified as silence and sets the end of speech to be the end of the last window classified as speech. Once again the processed utterance is extended SILMARGIN frames to ensure that if the silence detector has triggered slightly early the whole of the speech is still available for further processing.
Fig 5.5 shows an example of the speech/silence detection process. The waveform data is first classified as speech or silence at frame and then at window level before finally the start and end of the utterance are marked. In the example, audio input starts at point A and is stopped automatically at point H. The start of speech, C, occurs when a window of SPCSEQCOUNT frames are classified as speech and the start of the utterance occurs SILMARGIN frames earlier at B. The period of silence from D to E is not marked as the end of the utterance because it is shorter than SILSEQCOUNT. However after point F no more windows are classified as speech (although a few frames are) and so this is marked as the end of speech with the end of the utterance extended to G.
The second built-in mechanism for controlling audio input is by arranging for a signal to be sent from some other process. Sending the signal for the first time starts the audio device. If the speech detector is not enabled then sampling starts immediately and is stopped by sending the signal a second time. If automatic speech/silence detection is enabled, then the first signal starts the detector. Sampling stops immediately when a second signal is received or when silenece is detected. The signal number is set using the configuration parameter AUDIOSIG . Keypress control operates in a similar fashion and is enabled by setting the configuration parameter AUDIOSIG to a negative number. In this mode an initial keypress will be required to start sampling/speech detection and a second keypress will stop sampling immediately.
Audio output is also supported by HTK. There are no generic facilities for output and the precise behaviour will depend on the tool used. It should be noted, however, that the audio input facilities provided by HAUDIO include provision for attaching a replay buffer to an audio input channel. This is typically used to store the last few seconds of each input to a recognition tool in a circular buffer so that the last utterance input can be replayed on demand.