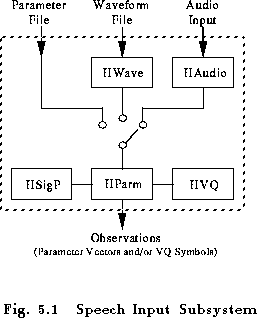
The facilities for speech input and output in HTK are provided by five distinct modules: HAUDIO, HWAVE, HPARM, HVQ and HSIGP. The interconnections between these modules are shown in Fig. 5.1.
Waveforms are read from files using HWAVE, or are input direct from an audio device using HAUDIO. In a few rare cases, such as in the display tool HSLAB, only the speech waveform is needed. However, in most cases the waveform is wanted in parameterised form and the required encoding is performed by HPARM using the signal processing operations defined in HSIGP. The parameter vectors are output by HPARM in the form of observations which are the basic units of data processed by the HTK recognition and training tools. An observation contains all components of a raw parameter vector but it may be possibly split into a number of independent parts. Each such part is regarded by a HTK tool as a statistically independent data stream. Also, an observation may include VQ indices attached to each data stream. Alternatively, VQ indices can be read directly from a parameter file in which case the observation will contain only VQ indices.
Usually a HTK tool will require a number of speech data files to be specified on the command line. In the majority of cases, these files will be required in parameterised form. Thus, the following example invokes the HTK embedded training tool HEREST to re-estimate a set of models using the speech data files s1, s2, s3, .... These are input via the library module HPARM and they must be in exactly the form needed by the models.
HERest ... s1 s2 s3 s4 ...
However, if the external form of the speech data files is not in the required form, it will often be possible to convert them automatically during the input process. To do this, configuration parameter values are specified whose function is to define exactly how the conversion should be done. The key idea is that there is a source parameter kind and target parameter kind. The source refers to the natural form of the data in the external medium and the target refers to the form of the data that is required internally by the HTK tool. The principle function of the speech input subsystem is to convert the source parameter kind into the required target parameter kind.
Parameter kinds consist of a base form to which one or more qualifiers may be attached where each qualifier consists of a single letter preceded by an underscore character. Some examples of parameter kinds are
The required source and target parameter kinds are specified using the configuration parameters SOURCEKIND and TARGETKIND . Thus, if the following configuration parameters were defined
SOURCEKIND = WAVEFORM
TARGETKIND = MFCC_E
then the speech input subsystem would expect each input file to contain
a speech waveform and it would convert it to mel-frequency cepstral
coefficients with log energy appended.
The source need not be a waveform. For example, the configuration parameters
SOURCEKIND = LPC
TARGETKIND = LPREFC
would be used to read in files containing linear prediction coefficients
and convert them to reflection coefficients.
For convenience, a special parameter kind called ANON is provided. When the source is specified as ANON then the actual kind of the source is determined from the input file. When ANON is used in the target kind, then it is assumed to be identical to the source. For example, the effect of the following configuration parameters
SOURCEKIND = ANON
TARGETKIND = ANON_D
would simply be to add delta coefficients to whatever the source form
happened to be.
The source and target parameter kinds default to ANON
to indicate that by default
no input conversions are performed. Note, however, that where two or more
files are listed on the command line, the meaning of
ANON will not be re-interpreted from one file to the next. Thus, it
is a general rule, that any tool reading multiple source speech files requires
that all the files have the same parameter kind.
The conversions applied by HTK's input subsystem can be complex and may not always behave exactly as expected. There are two facilities that can be used to help check and debug the set-up of the speech i/o configuration parameters. Firstly, the tool HLIST simply displays speech data by listing it on the terminal. However, since HLIST uses the speech input subsystem like all HTK tools, if a value for TARGETKIND is set, then it will display the target form rather than the source form. This is the simplest way to check the form of the speech data that will actually be delivered to a HTK tool. HLIST is described in more detail in section 5.12 below.
Secondly, trace output can be generated from the HPARM module by setting the TRACE configuration file parameter. This is a bit-string in which individual bits cover different parts of the conversion processing. The details are given in the reference section.
To summarise, speech input in HTK is controlled by configuration parameters. The key parameters are SOURCEKIND and TARGETKIND which specify the source and target parameter kinds. These determine the end-points of the required input conversion. However, to properly specify the detailed steps in between, more configuration parameters must be defined. These are described in subsequent sections.