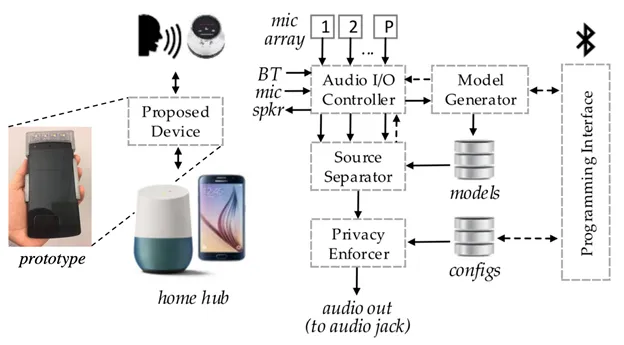
EE professor Xiaofan (Fred) Jiang and his collaborator, computer science professor Shahriar Nirjon, of the University of North Carolina at Chapel Hill, have received a three-year grant from the National Science Foundation (NSF) to develop a system that will defend against unwanted uses of voice assistants such as Amazon Echo and Google Home, Apple’s Siri, and Microsoft’s Cortana. Existing acoustic sensing, or continuous listening, devices apply standard noise-cancellation techniques to suppress background sounds and improve signal quality, but do not adequately protect against unintended uses and acoustic-based attacks.
“The ubiquity of continuous listening devices in our daily lives poses risks to our privacy,” says Jiang. “Voice-enabled devices, in particular, are vulnerable to activation by false commands, such as from a TV, and by unauthorized commands, such as from an outsider placing orders on Amazon. Eventually, hackers may be able to activate these devices for more nefarious purposes, such as controlling home appliances. Information leakage is also of particular concern in sensitive areas such as mobile health-care applications.”
Rather than develop application-specific systems, Jiang and Nirjon envision an independent and adaptive system that will allow the user to specify both the relevant sound and irrelevant, potentially privacy-threatening sounds. To gain wide adoption, such a system must be portable, lightweight, and convenient to use. Jiang and Nirjon expect the eventual system to take the form of an accessory, such as a sleeve, that will attach to the home hub or smartphone.
Jiang and Nirjon plan to start testing the technology with three applications: 1) a voice assistant that interacts with a user’s home hub or smartphone via voice commands; 2) an asthma-monitoring application that records lung sounds and sends them to the user’s doctor by smartphone, over the internet; and 3) an audio-based sleep-monitoring application that measures a user’s sleep quality in terms of snoring, sleep talking, coughs, and other sounds. The system would adapt to the purpose of the specific application—for example, enhancing voice in the voice assistant, while suppressing it in the asthma-monitoring application.
“The ultimate goal of this project,” says Jiang, “is to protect against information leakage by ensuring that no unintended personal or contextual information can be recovered or inferred from the audio output. During the course of the project, we will periodically collect outputs from our system and launch attacks on the data, to identify any vulnerabilities. This essential step will help us to develop and validate the system iteratively.”