The analysis of emotion, affect and sentiment from visual content has become an
exciting area in the multimedia community allowing to build new applications
for brand monitoring, advertising, and opinion mining.
There exists no corpora for sentiment analysis on visual content, and therefore
limits the progress in this critical area.
To stimulate innovative research on this challenging issue, we constructed a new
benchmark and database (you can browse the database at
VSO Browsing Interface).
This database contains a Visual Sentiment Ontology (VSO) consisting of
3244 adjective noun pairs (ANP), SentiBank a set of 1200 trained
visual concept detectors providing a mid-level representation of
sentiment, associated training images acquired from Flickr, and a
benchmark containing 603 photo tweets covering a diverse set of 21
topics.
This website provides the above mentioned material for download and is structured as the following:
Benchmark and Dataset Citation
Damian Borth, Rongrong Ji, Tao Chen, Thomas Breuel and Shih-Fu Chang.
"Large-scale Visual Sentiment Ontology and Detectors Using Adjective Noun Pairs,"
ACM Multimedia Conference, Barcelona, Oct 2013.
download paper
download material
Update: Thanks for checking out VSO, you may also be interested in our new expanded and multilingual version
MVSO
The benchmark includes 603 tweets with photos and is intended
for evaluating the performance of automatic sentiment prediction using
features of different modalities (text only, image only, and text-image
combined). It was collected in November 2012 via the PeopleBrowsr API
using 21 hashtags listed below. Ground truths of sentiment values were obtained by Amazon
Mechanic Turk annotation, resulting in 470 positive and 133 negative labels.
Hashtags
Human:
#abortion, #religion, #cancer, #aids,
#memoriesiwontforget
Social:
#police, #globalwarming, #gaymarriage
Event:
#election, #hurricanesandy, #blackfriday,
#agt (america got talent), #nfl,
#championsleague, #decemberwish,
Location:
#cairo, #newyork
Technology:
#android, #applefanboy
People:
#obama, #zimmerman
Ground truth labeling
To obtain sentiment ground truth for the collected image tweets, Amazon
Mechanical Turk annotation was used. Three labeling runs, namely image
only inspection, text only inspection, and full inspection of both image
and text contained in the tweet, have been performed on 2000 image
tweets of different hashtags. For each run and each tweet, 3 independent
Turkers were asked to label the sentiment label (positive, negative, or
neutral). The figure on the upper right shows the percentage of tweeets
that receive three completely different labels, confirming the benefits
of inspecting both image and text content. At the end, only tweets with
unanimous labels (agreed by all three Turkers) are included in the
released benchmark (603 tweets).
Sentiment Prediction Performance
Fig. 2 and Fig. 3 shows the accuracy of predicting the
sentiment values of photo tweets using late fusion of text-based
classifiers and visual concept based classifiers (SentiBank v1.02 and SentiBank v1.1 respectively). For
details please see the
paper
*The Phototweet sentiment prediction experiment in the paper used SentiBank v1.01.
Files for Download
1. Phototweet Sentiment Benchmark:
- tweet text
- tweet photo
- sentiment label (pos., neg.).
2. Dataset partitions for training and
testing the baseline prediction
system
(5 runs, see details in paper)
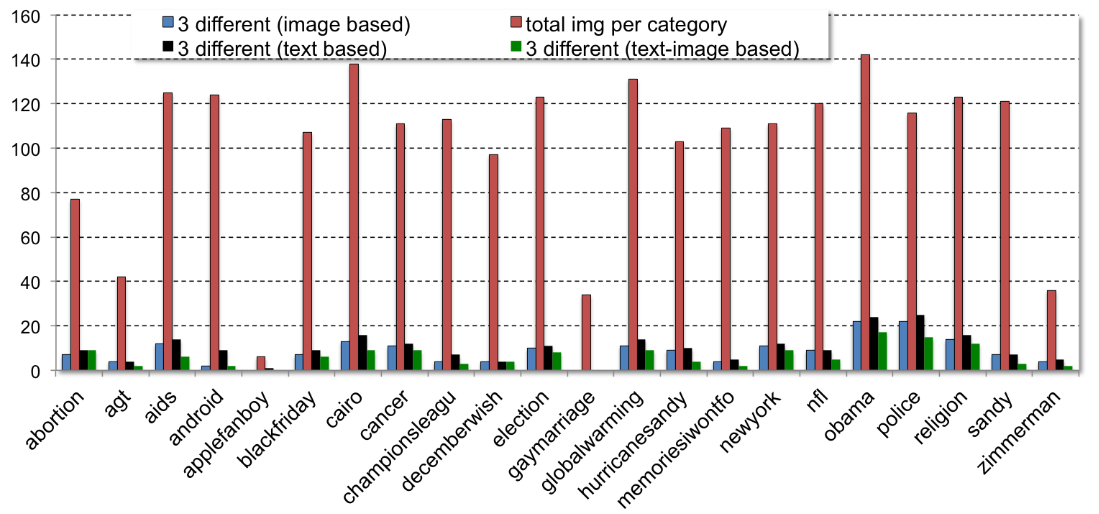
Fig.1 The volumes and label disagreements for different hashtags. For each hashtag, the total number of images
is shown, in addition to the number of images receiving complete disagreement among turkers (i.e., 3 different sentiment labels: positive, negative and neural),
while labeling is done using text only, image only, and joint image-text combined.
We implemented a baseline system for sentiment prediction of image
tweets. The systems employs SentiBank visual concept features in
combination with text-based sentiment classification in a late-fusion
setup. The following figure shows the prediction accuracy for tweets of
each hashtag."
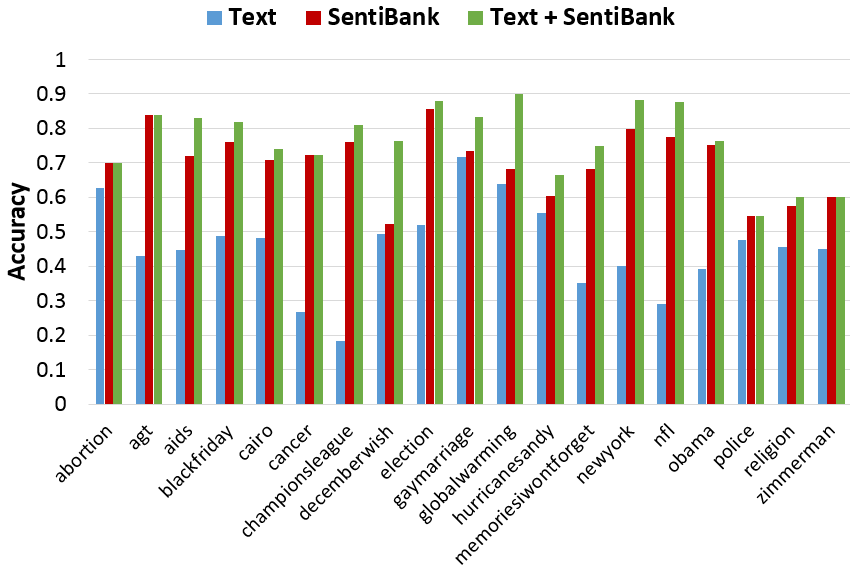 Fig.2
Fig.2 Phototweet sentiment prediction accuracy over different hashtags by using text only (SentiStrength), visual only (SentiBank v1.02), and combination. Accuracy averaged over 5 runs.
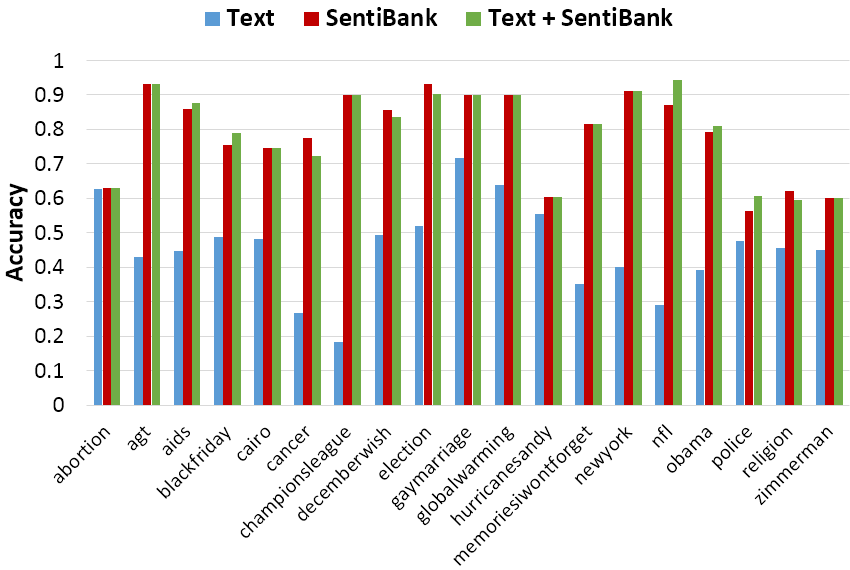 Fig.2
Fig.2 Phototweet sentiment prediction accuracy over different hashtags by using text only (SentiStrength), visual only (SentiBank v1.1), and combination. Accuracy averaged over 5 runs. The overall accuracy increased from 72% (v1.02) to 76% (v1.1).
By downloading the
Photo Tweet dataset, you agree that 1) the use of the data is restricted to research or education
purpose only, 2) all copyright and license restrictions associated with the dataset/code
will be followed, and 3) the authors of the above paper and their affiliated
organizations make no warranties regarding the database or software, including but not
limited to non-infringement.