TRECVID2010 Multimedia Event Detection (MED) System

Overview
We participated in the Multimedia Event Detection (MED) task at NIST TREC Video Retrieval Evaluation (TRECVID) 2010. The MED task was set up to advance research and development of systems that can automatically find video clips containing any event of interest. Figure 1 gives some example frames of the three evaluated events in MED 2010. Automatic detection of such complex video events has great potential for many applications, such as web video indexing, consumer content management, and open-source intelligence analysis.
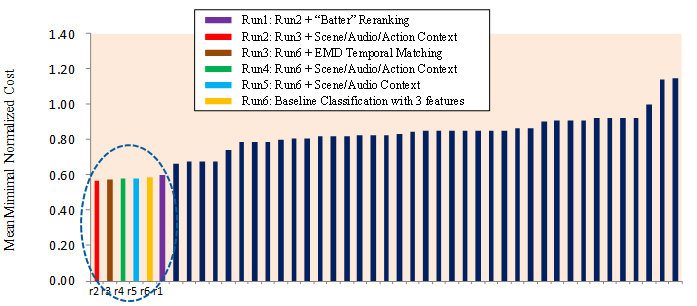
This project page introduces the techniques used in our MED 2010 system, which achieved the best performance among submissions from all participants. Figure 2 shows the evaluation results.
TRECVID is an open forum for encouraging and evaluating new research in
video retrieval. It features a benchmark activity sponsored annually, since
2001, by the National Institute of Standards and Technology (NIST). More
details about the evaluation procedures and outcomes can be found at the
NIST TRECVID site.
|
Figure 1: Example frames
of the 3 events evaluated in TRECVID MED 2010. Content of the same
class can be very different. Figure 2: Performance of our submitted MED runs (circled) and all 45 official submissions. The vertical axis shows the performance measured by mean Minimal Normalized Cost (MNC) of the three evaluated events. Note lower MNC means better performance. |

Technical Components
In MED 2010, we aim at answering the following questions. What kind of feature is more effective for multimedia event detection? Are features from different feature modalities (e.g., audio and visual) complementary for event detection? Can we benefit from generic concept detection of background scenes, human actions, and audio concepts? Are sequence matching and event-specific object detectors critical? Our findings indicate that spatial-temporal feature is very effective for event detection, and it's also very complementary to other features such as static SIFT and audio features. As a result, our baseline run combining these three features already achieves very impressive results, with a mean MNC of 0.586. Incorporating the generic concept detectors using a graph diffusion algorithm provides marginal gains (mean MNC 0.579). Sequence matching with Earth Mover's Distance (EMD) further improves the results (mean MNC 0.565). The event-specific detector ("batter"), however, didn't prove useful from our current re-ranking tests. We conclude that it is important to combine strong complementary features from multiple modalities for multimedia event detection, and cross-frame matching is helpful in coping with temporal order variation. Leveraging contextual concept detectors and foreground activities remains a very attractive direction requiring further research.
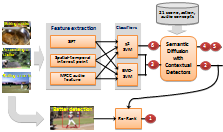
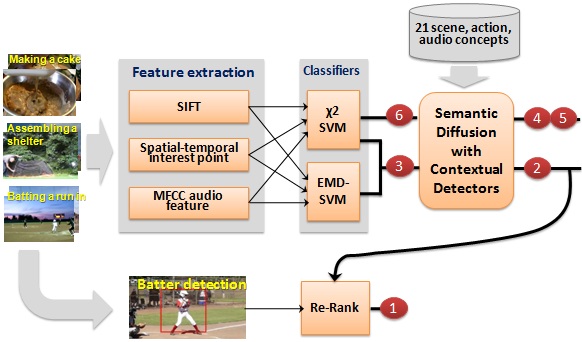
Figure 3 shows an overview of our system, which contains four major components: 1) multiple feature modalities; 2) EMD-based temporal matching; 3) contextual diffusion; and 4) event-specific object detector. We briefly describe each of the components below.|
Figure 3: Framework overview. Our system contains four major components, based on which we submitted 6 result runs. |
1. Multiple Feature Modalities
We consider three visual/audio features that are expected to be useful and complementary for event detection in videos.
Static SIFT feature:
We adopt two sparse keypoint detectors: Difference of Gaussian (DoG) and
Hessian Affine. Since the two detectors extract keypoints of different
properties, we expect that they are complementary. Using multiple keypoint
detectors is also suggested by many previous works for better
performance. SIFT is then adopted to describe each keypoint as a 128
dimensional vector. As processing all MED video frames will be computationally very
expensive, we sample one frame from every two seconds.
Spatial-temporal interest points: While SIFT describes 2D local structures in images, spatial-temporal
interest points (STIP) capture space-time volumes where the image values
have significant local variations in both space and time. We use Laptev's
method to compute locations and descriptors for STIPs in video. The
detector is based on an extension of Harris operator to space-time. Their code does not contain scale selection; instead
interest points are detected at multiple spatial and temporal scales. HOG
(Histograms of Oriented Gradients; 72 dimensions) and HOF (Histograms of
Optical Flow; 72 dimensions) descriptors are computed for the 3D video
patches in the neighborhood of the detected STIPs. We use concatenated
HOGHOF feature (144 dimensions) as the final descriptor for each STIP.
MFCC audio feature:
In addition to visual features like SIFT and STIP, audio is another
important cue for detecting events in videos. We expect it to be
complementary to the visual features. For this, we use the popular MFCC (Mel-frequency cepstral
coefficients) feature. We compute MFCC feature
over every 32ms time-window with 50% (16ms) overlap.
Given a video clip, we now have three sets of features
(SIFT, STIP, and MFCC). Due to the variations in length and content
complexity, the sets of the same feature differ in cardinality across
different video clips. We therefore adopt the popular bag-of-X
representation to convert the feature sets into fixed dimensional
histograms, one for each descriptor type. Details of the our feature
representations can be found in our
notebook paper. With the bag-of-X histogram features, we train separate
one-versus-all χ2 kernel SVMs as our baseline classifiers. The average
fusion of probability predictions from the three SVM classifiers forms our
baseline submission run 6.
2. EMD-based Temporal Matching
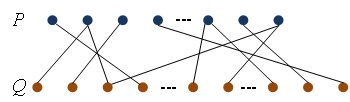
While accumulating all the SIFT/STIP/MFCC features from a video clip into a single feature vector seems a reasonable choice, it neglects the temporal information within the video clip. We therefore apply the earth mover's distance (EMD) to measure video clip similarity. We only adopt SIFT feature in this experiment, and thus each video clip is represented by a sequence of 5000-d bag-of-visual-word feature vectors (cardinality equals to the number of sampled frames). As shown in Figure 4, EMD computes the optimal flows between two sets of frames/features, producing the optimal match between both sets. The EMD is then used in a generalized form of Gaussian kernel for SVM classification.|
Figure 4: Toy example of EMD-based temporal matching between two sets of frames P and Q; lines indicate the presence of nonzero flows between corresponding frame pairs. |
3. Contextual Diffusion
Events are mostly defined by several (moving) objects such
as "person", and generally occur under particular scene settings with
certain audio sounds. For example, as shown in Figure 1, "batting a run in"
contains people of various actions in the baseball field scene with
typically some cheering or clapping sounds. Such event-scene-object-sound
dependency provides rich contextual information for understanding the
events. Most previous approaches, however, handled events, scenes, objects,
and audio sounds separately without considering their relationship. Our
intuition is that once the contextual cues can be computed, they can be
utilized to make the event detection more robust. We therefore explore such
contexts in MED 2010.
To build detectors (classifiers) for a large number of contextual concepts,
we first need to collect enough training samples. To this end, we defined 21
contextual concepts as listed below the correlation table in Figure 5, and
designed an annotation tool to label the training videos for the 21 concepts
(download annotations). Each video is divided to multiple
10-sec clips. With the labeled training data, we train SVM classifiers for
detecting the concepts. For Human Action concepts, we use the bag-of-X
representation of the STIP feature, while for the scene and audio concepts,
we adopt similar classification framework based on the SIFT and MFCC
features respectively.
|
Figure 5: Estimated relationship (correlation) between the 3 events and the 21 contextual concepts according to ground-truth annotations. The color-highlighted cells indicate the strong correlations discovered between events and the concepts. |

4. Event-specific Object Detector
Besides the generic methods mentioned above, we are also interested in evaluating some ad-hoc ideas that are specific to individual events only. For event "batting a run in", videos usually contain certain human objects (e.g., batters) of familiar gestures and similar clothing. Assuming that videos of this event should have a high ratio of frames with batter visible, we trained a "batter" detector as an additional clue for detecting this specific event. Example detection results are given in Figure 6. The batter detector is applied as a post-processing reranking step. For every test video, the ratio of frames that have positive detection of the batter object is first computed. If the ratio is larger than an estimated threshold, the event score of the video clip will be multiplied with the ratio and the video will be moved up to the top of the ranked list. Event detection scores of other videos are not modified.|
Figure 6: "batter" detection results. |

For detailed result analysis of each technical
component, please refer to
our TRECVID 2010 paper and
talk slides.
People
- Yu-Gang
Jiang1, Xiaohong Zeng1, Guangnan Ye1, Subh
Bhattacharya2, Dan Ellis1, Mubarak Shah2, Shih-Fu Chang1
(1Columbia University; 2University of Central Florida)
Download
Publication
- Yu-Gang Jiang, Xiaohong Zeng, Guangnan Ye, Subh Bhattacharya, Dan Ellis, Mubarak Shah, Shih-Fu Chang. Columbia-UCF TRECVID2010 Multimedia Event Detection: Combining Multiple Modalities, Contextual Concepts, and Temporal Matching. In NIST TRECVID Workshop, Gaithersburg, MD, November 2010. [talk slides]
Related Projects
- Columbia University's TRECVID-2008 Semantic Visual Concept Detection System
- Domain Adaptive Semantic Diffusion for Large Scale Context-Based Video Annotation
For problems or
questions regarding this webpage please contact the
Web Master.
Last updated: Dec. 2010.