
Columbia News Video Search Engine and TRECVID 2005 Evaluation

Summary

We are developing an integrated search engine for broadcast news video, which has been used in our work in NIST TRECVID video retrieval evaluation 2005. We have incorporated some of our latest research results in story segmentation, multimodal retrieval, semantic concept detection, and duplicate detection. Our objectives are to investigate the effectiveness of individual indexing components and their impact on the overall user experience in video retrieval.
TRECVID is an open forum for encouraging and evaluating new research in video retrieval. It features a benchmark activity sponsored annually, since 2001, by the National Institute of Standards and Technology (NIST). In 2005, the evaluation included five tasks: shot boundary detection, low-level feature (camera motion) detection, high-level feature (concept) detection, search, and stock footage exploration. The data set for TRECVID 2005 was greatly expanded over previous years, including more than 160 hours of broadcast news video from 6 different channels in 3 different languages. The evaluation attracted more than 60 groups from around the world, resulting in very informative outcomes in assessing the state of the art and exchanging new ideas. More details about the evaluation procedures and outcomes can be found at the NIST TRECVID site.
Columbia's DVMM team participated in TRECVID 2005 evaluation and joined the tasks of high-level feature (concept) detection and search.
Search
For the search task, we explored several novel approaches to leveraging cues from the audio/visual streams to improve upon standard text and image-example searches in all three video search tasks. We employed “Cue-X re-ranking” to discover relevant visual clusters from rough search results; “concept search” to allow text searches against concept detection results; and “near duplicate detection” for finding re-used footage of events across various sources. We also apply our story segmentation framework and share the results with the community. In the end, we find that each of these components provides significant improvement for at least some, if not all, search topics. Combinations of these new tools achieved top AP for four topics (Mahmoud Abbas, fire, boat, people/building) and good performance for an additional ten topics. We develop an analysis tool to take an in-depth look at the logs from interactive runs and gain insight into the relative usefulness of each tool for each topic.
The following diagram summarizes the conceptual architecture of our search engine and the component tools.
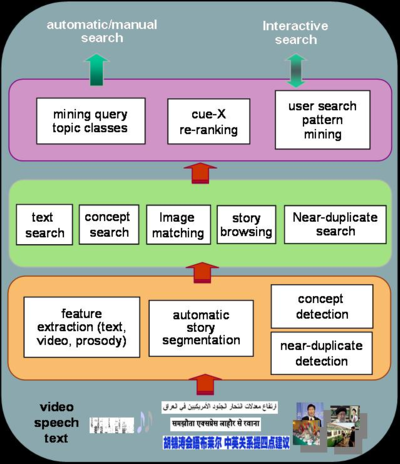
The following figure illustrates the user interfaces of our integrated search engine. For interactive demos of the system over the entire TRECVID 2005 data, visit our online search system here.

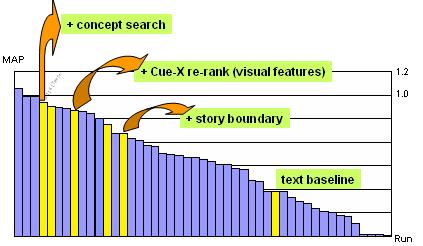
The following diagram shows the relative contributions of each of our search tools towards to the final performance, in comparison with submissions from other participants in the task of automatic search. It confirms the large improvement due to the use of story boundaries in basic text search and the enhancement due to the Cue-X re-ranking method.
Story Segmentation [link to project]
The story segmentation algorithm uses a process based on the information bottleneck principle and fusion of visual features and prosody features extracted from speech. The approach emphasizes the automatic discovery of salient features and effective classification via information theory measures and was shown to be effective in the TRECVID 2004 benchmark. The biggest advantage of the proposed approach is to remove the dependence on the manual process in choosing the mid-level features and the huge labor cost involved in annotating the training corpus for training the detector of each mid-level feature. For this year’s data different detectors are trained separately for each language. The performance, evaluated with TRECVID metrics (F1), is 0.52 in English, 0.87 in Arabic, and 0.84 in Chinese. The results were distributed to all active participants of TRECVID. In our experiments, the story segmentation was used primarily to associate text with shots. We found that story segmentation improves text search almost 100% over ASR/MT “phrase” segmentation. In the interactive system, we also enabled exploring full stories and find that a significant number of additional shots can be found this way, especially for named person topics.
Near Duplicate Detection [link to project]
Near-duplicate detection uses a parts-based approach to detect duplicate scenes across various news sources. In some senses, it is very similar to content-based image retrieval, but is highly sensitive to scenes which are shown multiple times, perhaps from slightly different angles or with different graphical overlays on various different channels. It rejects image pairs where general global features are similar and retains only pairs with highly similar objects and spatial relationships. We apply near-duplicate detection in interactive search as a tool for relevance feedback. Once the searcher finds positive examples through text search or some other approach, they can look for near-duplicates of those positive shots. We have found that duplicate detection, on average, tends to lead to double the number of relevant shots found when used in addition to basic text, image, and concept searches.
High-Level Feature Extraction
In TRECVID 2005, we explored the potential of parts-based statistical approaches in detecting generic concepts. Parts-based object representation and its related statistical detection models have gained great attention in recent years. This is evidenced by promising results reported in conferences like CVPR, ICCV, and NIPS. We analyzed their performance and compared them with some of the state of the art such as those using fusion of SVM-based classifiers over various visual features. We adopted a general approach and applied the same technique to all of the 10 concepts. One of our main objectives was to understand what types of high-level features would benefit most from such new representation and detection paradigm.
Parts-Based Object/Scene Detection [link to project]
The following diagram illustrates the results in detecting an instance of "motor bike" object by detection of parts of interest in an image and then statistically matching the image parts graph to the random attributed relational graph (R-ARG) learned from a collection of training samples a priori.
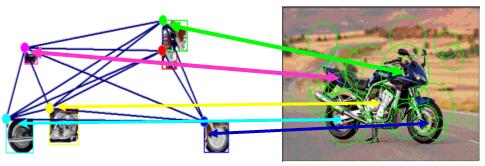
From the TRECVID 2005 results, we found the parts-based approach significantly improved upon the baseline, consistently for every concept. The MAP was increased by about 10%. For the “US Flag” concept, the improvement by fusing the parts-based detection with the baseline was as high as 25%, making it the best performing run. The results confirm that parts-based approach is powerful for detecting generic visual concepts, especially those dominated by the local attributes and topological structures.
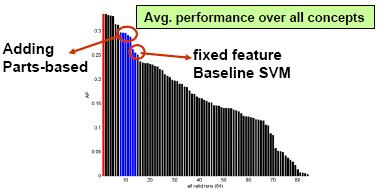
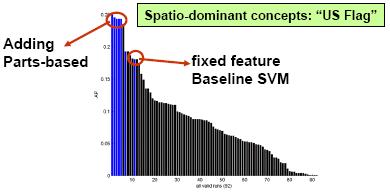
The above figures show the performance (in terms of Average Precision
defined in TRECVID) of the parts-based detectors, compared with the SVM
baseline detectors and submissions by other groups (in black). The left
one shows the average over all of 10 concepts. The right one shows the
superiority of the parts-based detectors over concepts (such as US Flag)
that have strong cues from both spatial structures and visual attributes.
People
- Shih-Fu Chang, Winston Hsu, Lyndon Kennedy, Lexing Xie, Akira Yanagawa, Eric Zavesky, Dong-Qing Zhang
in collaboration with IBM Research
Publications and Talks
Shih-Fu Chang, Winston Hsu, Lyndon Kennedy, Lexing Xie, Akira Yanagawa, Eric Zavesky, Dong-Qing Zhang, "Columbia University TRECVID-2005 Video Search and High-Level Feature Extraction," in NIST TRECVID workshop, Gaithersburg, MD, Nov. 2005. [abstract][pdf]
Columbia University TRECVID 2005 Search Task [talk slide]
Columbia University TRECVID 2005 High-Level Feature Detection task [talk slide]
Poster for Columbia University News Video Search System [full-resolution pdf file][link to low-resolution]
(Parts-based Object/Scene Detectors)
Dongqing Zhang, Shih-Fu Chang, "Learning Random Attributed Relational
Graph for Part-based Object Detection," ADVENT Technical Report #212-2005-6
Columbia University, May 2005. [pdf]
(Near-Duplicate Detector)
Dong-Qing Zhang, Shih-Fu Chang, “Detecting Image Near-Duplicate
by Stochastic Attributed Relational Graph Matching with Learning,”
In ACM Multimedia, New York City, USA, October 2004.[abstract][pdf]
(Story Segmentation and Cue-X Re-ranking)
Winston Hsu, Shih-Fu Chang, “Visual Cue Cluster Construction via
Information Bottleneck Principle and Kernel Density Estimation,”
In International Conference on Content-Based Image and Video Retrieval
(CIVR), Singapore, 2005.[abstract][pdf]
Demo
Columbia News Video Search Engine (link)
Related Projects
- DVMM Project: Parts-Based Object and Scene Detection [link to project]
- DVMM Project: Near Duplicate Detection [link to project]
- DVMM Project: News Story Segmentation [link to project]
- Columbia Story Boundary Data Set for TRECVID 2005
Sponsor
ARDA VACE II Program
![]()
For problems or questions
regarding this web site contact The
Web Master.
Last updated: January 2nd, 2006.