|
|
|
| |
 |
|
Cross-media Structured Common Space for Multimedia Event Extraction. Manling Li*, Alireza Zareian*, Qi Zeng, Spencer Whitehead, Di Lu, Heng Ji and Shih-Fu Chang (*equal contributions) In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL2020) Seattle, WA July, 2020 (Oral presentation) [pdf] [Project Page] |
| |
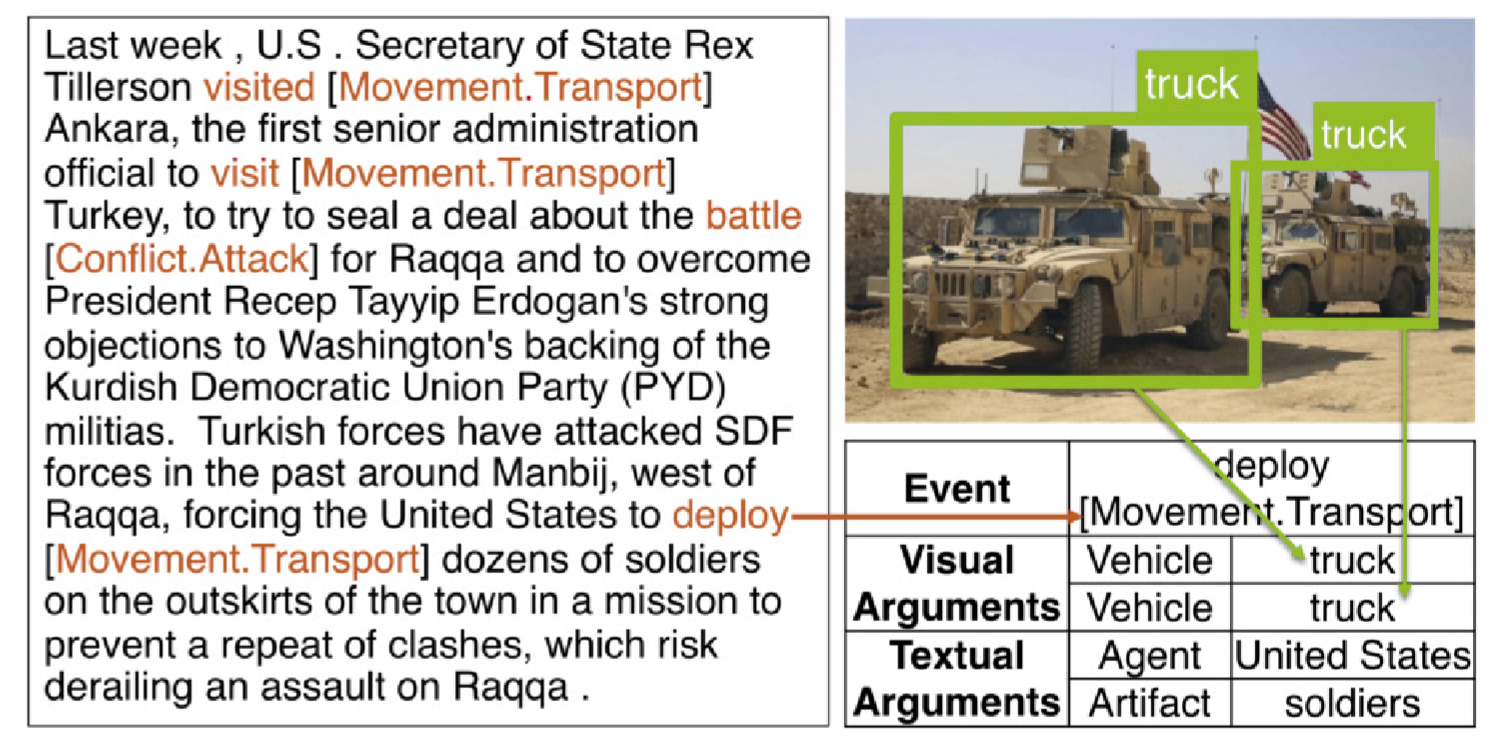
We introduce a new task, MultiMedia Event Extraction (M2E2), which aims to extract events and their arguments from multimedia documents. We develop the first benchmark and collect a dataset of 245 multimedia news articles with extensively annotated events and arguments. We propose a novel method, Weakly Aligned Structured Embedding (WASE), that encodes structured representations of semantic information from textual and visual data into a common embedding space. The structures are aligned across modalities by employing a weakly supervised training strategy, which enables exploiting available resources without explicit cross-media annotation. Compared to unimodal state-of-the-art methods, our approach achieves 4.0% and 9.8% absolute F-score gains on text event argument role labeling and visual event extraction. Compared to stateof-the-art multimedia unstructured representations, we achieve 8.3% and 5.0% absolute Fscore gains on multimedia event extraction and argument role labeling, respectively. By utilizing images, we extract 21.4% more event mentions than traditional text-only methods.
|
|
|
|
|
|
| |
 |
|
GAIA: A Fine-grained Multimedia Knowledge Extraction System. Manling Li*, Alireza Zareian*, Ying Lin, Xiaoman Pan, Spencer Whitehead, Brian Chen, Bo Wu, Heng Ji, Shih-Fu Chang, Clare Voss, Daniel Napierski and Marjorie Freedman (*equal contributions) In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL2020) Demo Track Seattle, WA July, 2020 [pdf] |
| |
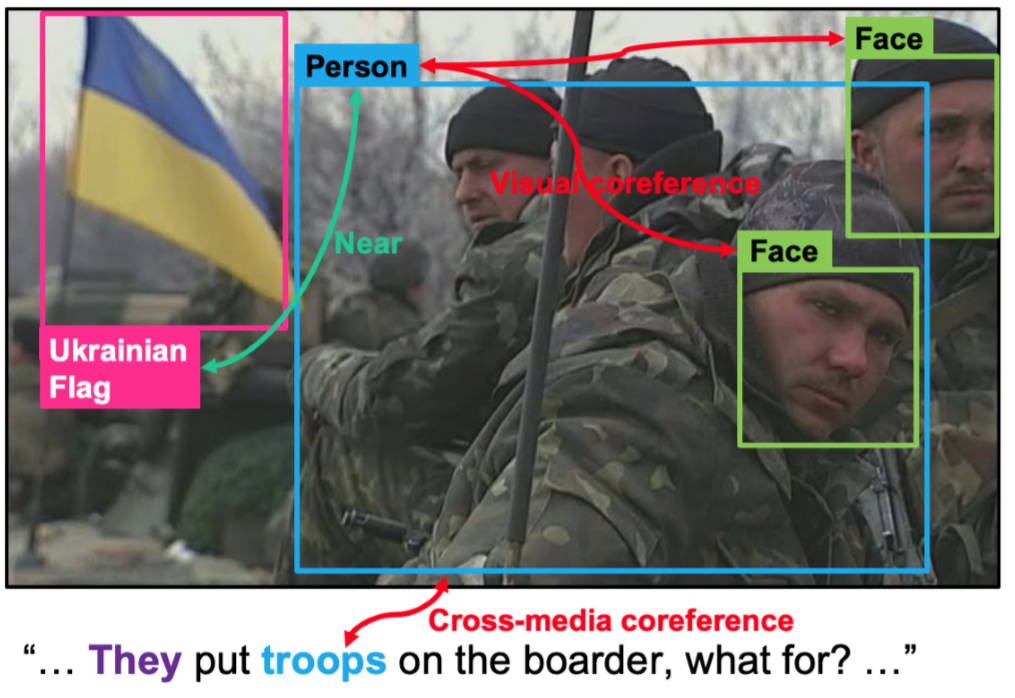
We present the first comprehensive, open source multimedia knowledge extraction system that takes a massive stream of unstructured, heterogeneous multimedia data from various sources and languages as input, and creates a coherent, structured knowledge base, indexing entities, relations, and events, following a rich, fine-grained ontology. Our system, GAIA, enables seamless search of complex graph queries, and retrieves multimedia evidence including text, images and videos. GAIA achieves top performance at the recent NIST TAC SM-KBP2019 evaluation. The system is publicly available at GitHub and DockerHub, with complete documentation.
|
|
|
|
|
|
| |
 |
|
Weakly Supervised Visual Semantic Parsing. Alireza Zareian, Svebor Karaman, and Shih-Fu Chang In IEEE International Conference on Computer Vision and Pattern Recognition (CVPR) Seattle, WA June, 2020 (Oral presentation) [pdf] [code] |
| |
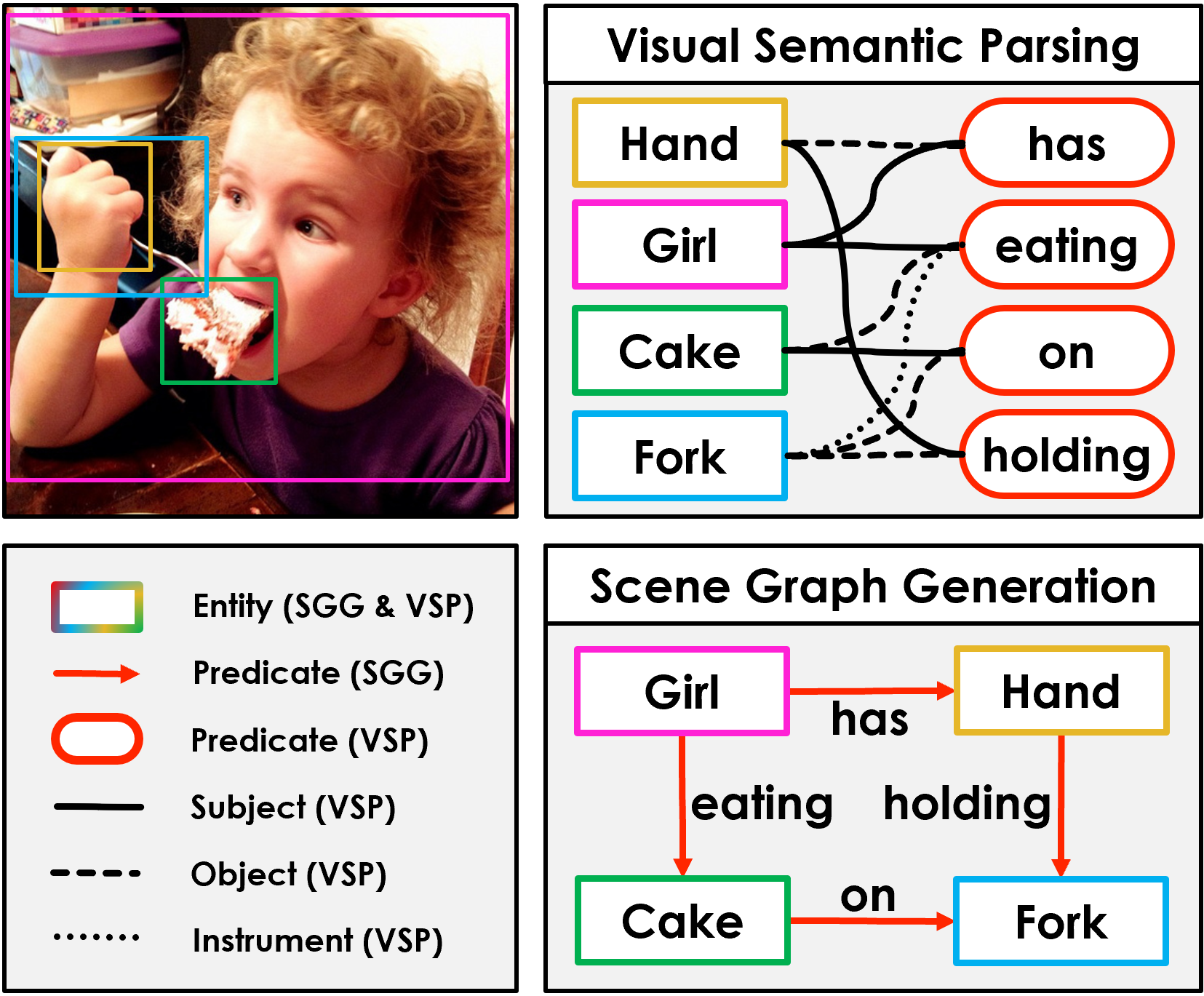
Scene Graph Generation (SGG) aims to extract entities, predicates and their semantic structure from images, enabling deep understanding of visual content, with many applications such as visual reasoning and image retrieval. Nevertheless, existing SGG methods require millions of manually annotated bounding boxes for training, and are computationally inefficient, as they exhaustively process all pairs of object proposals to detect predicates. In this paper, we address those two limitations by first proposing a generalized formulation of SGG, namely Visual Semantic Parsing, which disentangles entity and predicate recognition, and enables sub-quadratic performance. Then we propose the Visual Semantic Parsing Network, VSPNet, based on a dynamic, attention-based, bipartite message passing framework that jointly infers graph nodes and edges through an iterative process. Additionally, we propose the first graph-based weakly supervised learning framework, based on a novel graph alignment algorithm, which enables training without bounding box annotations. Through extensive experiments, we show that VSPNet outperforms weakly supervised baselines significantly and approaches fully supervised performance, while being several times faster. We publicly release the source code of our method.
|
|
|
|
|
|
| |
 |
|
General Partial Label Learning via Dual Bipartite Graph Autoencoder. Brian Chen, Bo Wu, Alireza Zareian, Hanwang Zhang, and Shih-Fu Chang In The Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI) New York, NY February, 2020 [pdf] |
| |
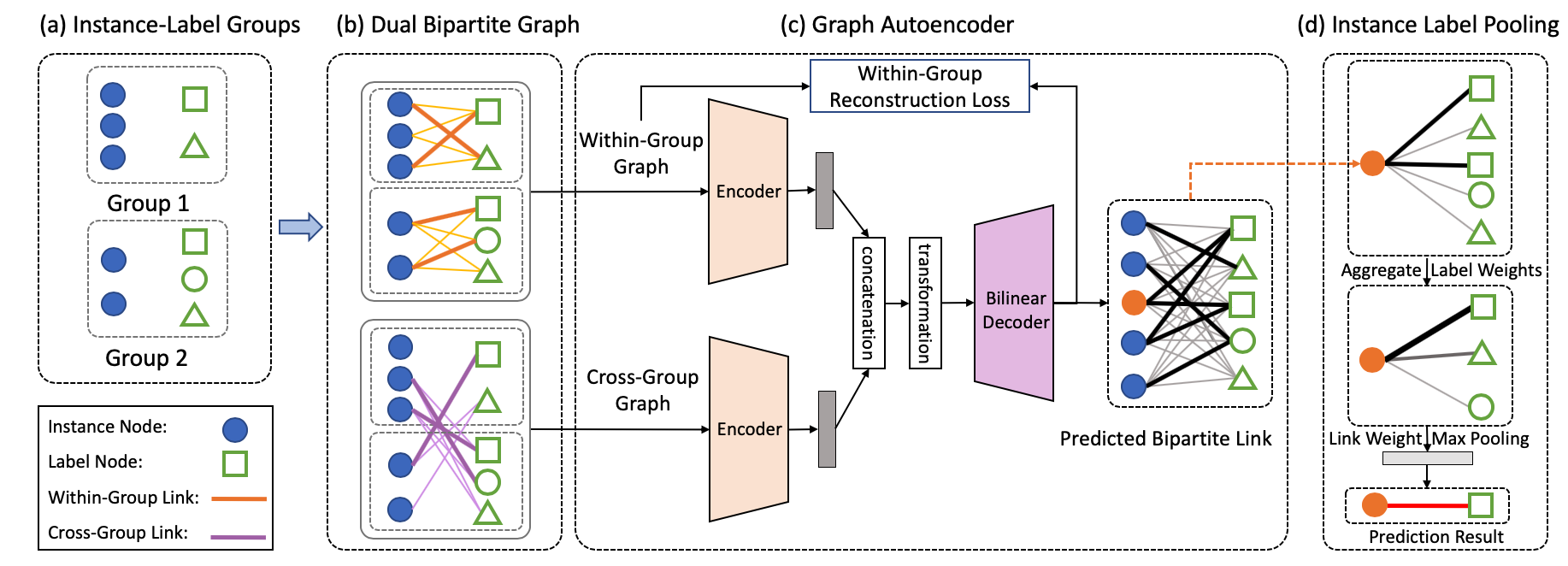
We formulate a practical yet challenging problem: General Partial Label Learning (GPLL). Compared to the traditional Partial Label Learning (PLL) problem, GPLL relaxes the supervision assumption from instance-level --- a label set partially labels an instance --- to group-level: 1) a label set partially labels a group of instances, where the within-group instance-label link annotations are missing, and 2) cross-group links are allowed --- instances in a group may be partially linked to the label set from another group. Such ambiguous group-level supervision is more practical in real-world scenarios as additional annotation on the instance-level is no longer required, e.g., face-naming in videos where the group consists of faces in a frame, labeled by a name set in the corresponding caption. In this paper, we propose a novel graph convolutional network (GCN) called Dual Bipartite Graph Autoencoder (DB-GAE) to tackle the label ambiguity challenge of GPLL. First, we exploit the cross-group correlations to represent the instance groups as dual bipartite graphs: within-group and cross-group, which reciprocally complements each other to resolve the linking ambiguities. Second, we design a GCN autoencoder to encode and decode them, where the decodings are considered as the refined results. It is worth noting that DB-GAE is self-supervised and transductive, as it only uses the group-level supervision without a separate offline training stage. Extensive experiments on two real-world datasets demonstrate that DB-GAE significantly outperforms the best baseline over absolute 0.159 F1-score and 24.8% accuracy. We further offer analysis on various levels of label ambiguities.
|
|
|
