|
|
|
| |
 |
|
Unsupervised Embedding Learning via Invariant and Spreading Instance Feature. Mang Ye, Xu Zhang, Pong C. Yuen, and Shih-Fu Chang In IEEE International Conference on Computer Vision and Pattern Recognition (CVPR) Long Beach, California June, 2019 [pdf] [code] |
| |
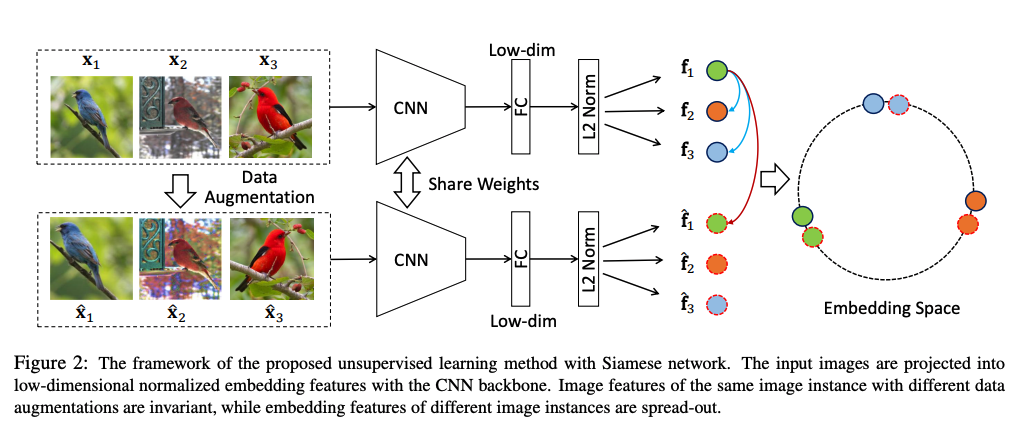
This paper studies the unsupervised embedding learning problem, which requires an effective similarity measurement between samples in low-dimensional embedding space. Motivated by the positive concentrated and negative separated properties observed from category-wise supervised learning, we propose to utilize the instance-wise supervision to approximate these properties, which aims at learning data augmentation invariant and instance spread-out features. To achieve this goal, we propose a novel instance based softmax embedding method, which directly optimizes the ‘real’ instance features on top of the softmax function. It achieves significantly faster learning speed and higher accuracy than all existing methods. The proposed method performs well for both seen and unseen testing categories with cosine similarity. It also achieves competitive performance even without pre-trained network over samples from fine-grained categories.
|
|
|
|
|
|
| |
 |
|
DMC-Net: Generating Discriminative Motion Cues for Fast Compressed Video Action Recognition. Zheng Shou, Xudong Lin, Yannis Kalantidis, Laura Sevilla-Lara, Marcus Rohrbach, Shih-Fu Chang, and Zhicheng Yan In IEEE International Conference on Computer Vision and Pattern Recognition (CVPR) Long Beach, California June, 2019 [pdf] |
| |
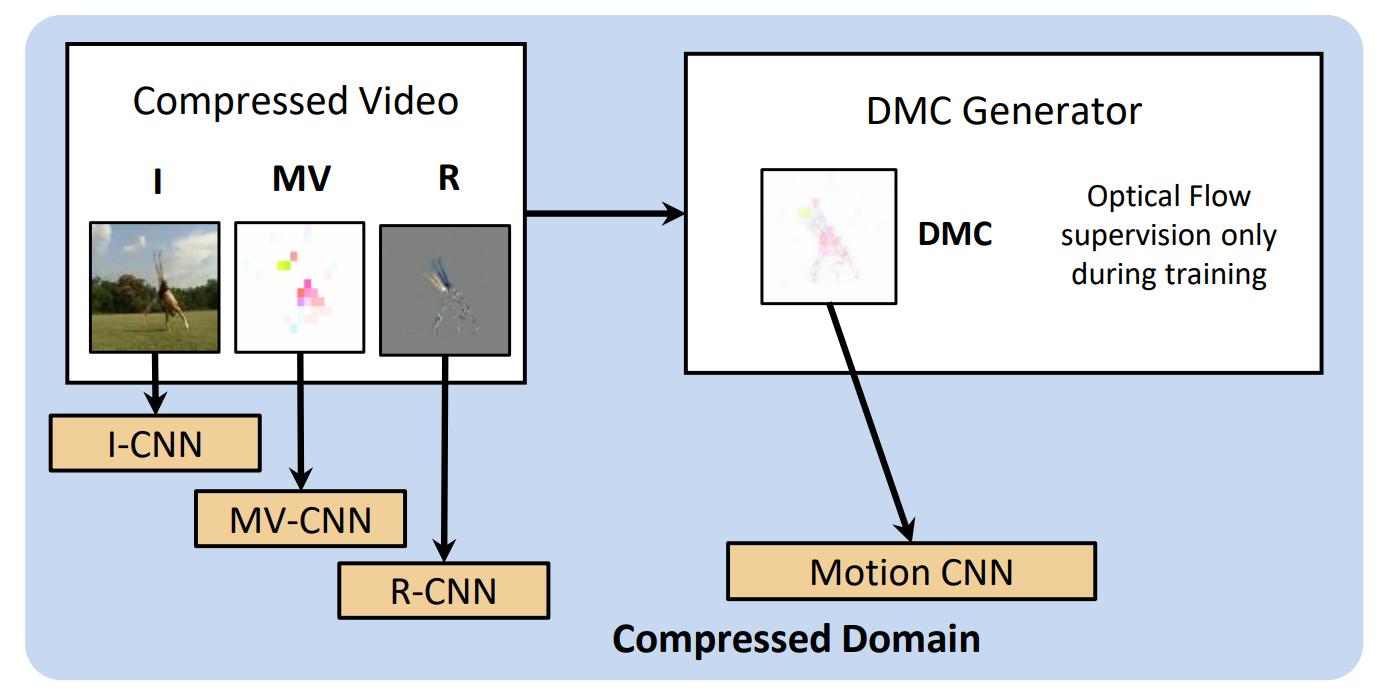
Motion has shown to be useful for video understanding, where motion is typically represented by optical flow. However, computing flow from video frames is very time-consuming. Recent works directly leverage the motion vectors and residuals readily available in the compressed video to represent motion at no cost. While this avoids flow computation, it also hurts accuracy since the motion vector is noisy and has substantially reduced resolution, which makes it a less discriminative motion representation. To remedy these issues, we propose a lightweight generator network, which reduces noises in motion vectors and captures fine motion details, achieving a more Discriminative Motion Cue (DMC) representation. Since optical flow is a more accurate motion representation, we train the DMC generator to approximate flow using a reconstruction loss and a generative adversarial loss, jointly with the downstream action classification task. Extensive evaluations on three action recognition benchmarks (HMDB-51, UCF-101, and a subset of Kinetics) confirm the effectiveness of our method. Our full system, consisting of the generator and the classifier, is coined as DMC-Net which obtains high accuracy close to that of using flow and runs two orders of magnitude faster than using optical flow at inference time.
|
|
|
|
|
|
| |
 |
|
Multi-level Multimodal Common Semantic Space for Image-Phrase Grounding. Hassan Akbari, Svebor Karaman, Surabhi Bhargava, Brian Chen, Carl Vondrick, and Shih-Fu Chang In IEEE International Conference on Computer Vision and Pattern Recognition (CVPR) Long Beach, California June, 2019 [pdf] [code] |
| |
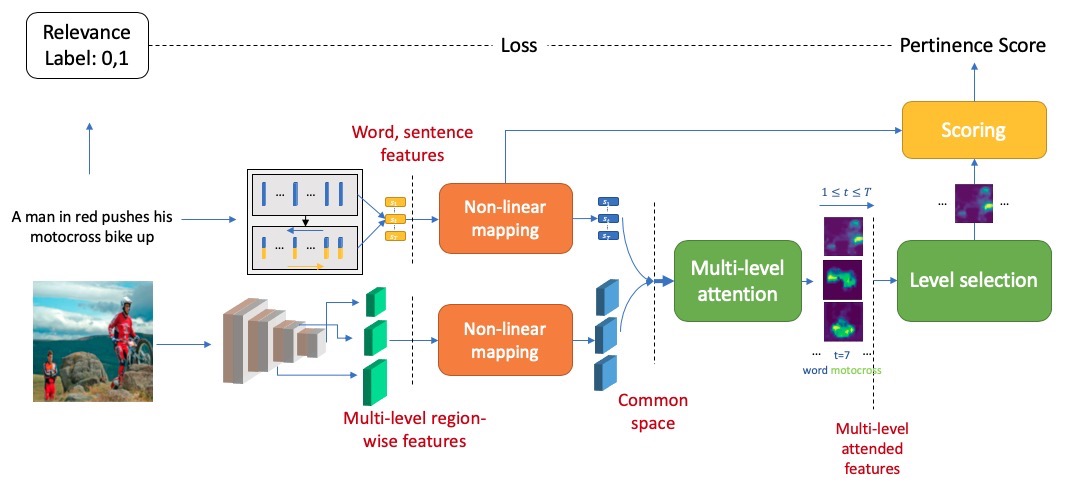
We address the problem of phrase grounding by learning a multi-level common semantic space shared by the textual and visual modalities. We exploit multiple levels of feature maps of a Deep Convolutional Neural Network, as well as contextualized word and sentence embeddings extracted from a character-based language model. Following dedicated non-linear mappings for visual features at each level, word, and sentence embeddings, we obtain multiple instantiations of our common semantic space in which comparisons between any target text and the visual content is performed with cosine similarity. We guide the model by a multi-level multimodal attention mechanism which outputs attended visual features at each level. The best level is chosen to be compared with text content for maximizing the pertinence scores of image-sentence pairs of the ground truth. Experiments conducted on three publicly available datasets show significant performance gains (20%-60% relative) over the state-of-the-art in phrase localization and set a new performance record on those datasets. We provide a detailed ablation study to show the contribution of each element of our approach and release our code on GitHub.
|
|
|
|
|
|
| |
 |
|
Unsupervised Rank-Preserving Hashing for Large-Scale Image Retrieval. Svebor Karaman, Xudong Lin, Xuefeng Hu, and Shih-Fu Chang
In International Conference on Multimedia Retrieval (ICMR) Ottawa, Canada June, 2019 [pdf] |
| |
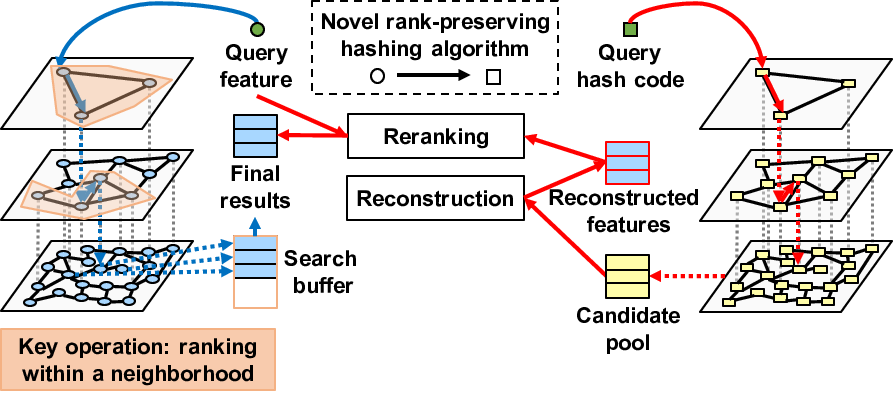
We propose an unsupervised hashing method, exploiting a shallow neural network, that aims to produce binary codes that preserve the ranking induced by an original real-valued representation. This is motivated by the emergence of small-world graph-based approximate search methods that rely on local neighborhood ranking. We formalize the training process in an intuitive way by considering each training sample as a query and aiming to obtain a ranking of a random subset of the training set using the hash codes that is the same as the ranking using the original features. We also explore the use of a decoder to obtain an approximated reconstruction of the original features. At test time, we retrieve the most promising database samples using only the hash codes and perform re-ranking using the reconstructed features, thus allowing the complete elimination of the original real-valued features and the associated high memory cost. Experiments conducted on publicly available large-scale datasets show that our method consistently outperforms all compared state-of-the-art unsupervised hashing methods and that the reconstruction procedure can effectively boost the search accuracy with a minimal constant additional cost.
|
|
|
