Dan
Ellis : Resources
: Matlab
:
PLP and RASTA (and MFCC, and inversion) in Matlab
using melfcc.m and invmelfcc.m
Introduction
One of the first decisions in any pattern recognition system is the
choice of what features to use: How exactly to represent the basic
signal that is to be classified, in order to make the classification
algorithm's job easiest.
Speech recognition is a typical example. Through more than 30 years
of recognizer research, many different feature representations of the
speech signal have been suggested and tried.
The most popular feature representation currently used is the
Mel-frequency Cepstral Coefficients or MFCC.
Another popular speech feature representation is known as
RASTA-PLP, an acronym for Relative Spectral Transform - Perceptual
Linear Prediction. PLP was originally proposed by Hynek Hermansky as
a way of warping spectra to minimize the differences between speakers
while preserving the important speech information [Herm90]. RASTA is
a separate technique that applies a band-pass filter to the energy in
each frequency subband in order to smooth over short-term noise
variations and to remove any constant offset resulting from static
spectral coloration in the speech channel e.g. from a telephone line [HermM94].
RASTA-PLP is implemented in a number of programs, such as the 'rasta'
program, and its enhanced version 'feacalc', which are distributed for
Unix as part of the
SPRACHcore
package.
In order to understand the algorithm, however, it's useful to have a
simple implementation in Matlab. By using Matlab's primitives for FFT
calculation, Levinson-Durbin recursion etc., the Matlab code can be
made quite small and transparent.
Mike Shire started
this implementation in 1997 while he was a graduate student in
Morgan's group at ICSI. I have recently revised and extended his
implementation to allow both spectral and cepstral outputs, and to
allow independent selection of RASTA and/or PLP processing.
This implementation offers only a few control parameters, namely a
switch to select or disable rasta filtering, and an option to set the
order of PLP modeling (which disables PLP modeling when set to zero).
Other important options, such as the basic window and hop sizes, can
easily be altered by editing the relevant routines, if desired.
MFCCs
Since Mel-frequency Cepstral Coefficients, the other really popular
speech feature, involve almost the same processing steps, I decided
to make an implementation for them as well, using the same blocks
as far as possible. See below.
Inverting Cepstra to Audio
Sometimes it's interesting to `listen' to what it is that the cepstral
representations are really capturing. You can do this, crudely, by
recovering the short-time magnitude spectrum implied by the cepstral
coefficients, then imposing it on white noise. The routine
invmelfcc below does this (actually, it can do it for both MFCC
and PLP cepstra, depending on the options you give it).
For more details on reproducing and inverting cepstra from several common feature calculation programs, see the companion page on Reproducing Feature Outputs....
Code
The routines provided here are:
- melfcc.m - main function for calculating PLP and MFCCs from sound waveforms, supports many options - including Bark scaling (i.e. not just Mel! but cannot do rasta).
- invmelfcc.m - main function for inverting back from cepstral coefficients to spectrograms and (noise-excited) waveforms, options exactly match melfcc (to invert that processing).
- rastaplp.m - the original main routine to
convert waveform data into a sequence of feature frames. Outputs
are both cepstra and spectra features, and options allow for
selection of RASTA, PLP, both, or neither. (Cannot do Mel-scaling).
m = rastaplp(d,sr,0,ord)
is equivalent to
m = melfcc(d,sr,'preemph',0,'modelorder',ord,'numcep',ord+1,'dcttype',1,'dither',1,'nbands',ceil(hz2bark(sr/2))+1,'fbtype','bark','usecmp',1);
- powspec.m - calculate the
short-time power spectrum, basically a wrapper around Matlab's
specgram.
- audspec.m - map the power
spectrum to an auditory frequency axis, by combining FFT bins into
equally-spaced intervals on the Bark axis (or one approximation of
it).
- fft2barkmx.m - function to
create the weight matrix that maps FFT bin magnitudes to the
Bark frequency axis, used by audspec.m.
- fft2melmx.m - generates a matrix of weights to convert FFT magnitudes into Mel bands, just like fft2barkmx above.
- rastafilt.m - filter each
frequency band (now in terms of log energy) with the RASTA filter.
- postaud.m - fix-up the auditory
spectrum with equal-loudness weighting and cube-root
compression.
- dolpc.m - convert the auditory
spectra directly to LPC coefficients via Levinson-Durbin.
- lpc2cep.m - convert LPC
coefficients directly to cepstral values.
- lpc2spec.m - convert LPC
coefficients back into spectra by sampling the z-plane.
- spec2cep.m - calculate
cepstra by taking the DCT/DFT of the log of a set of spectra.
- hz2bark.m - convert frequency in
Hz to the auditory Bark scale.
- bark2hz.m - convert back from
Bark units to frequency in Hz.
- hz2mel.m - convert frequency in
Hz to the auditory Mel scale (either Slaney's or HTK mapping).
- mel2hz.m - convert back from
Mel units to frequency in Hz.
- lifter.m - apply (or remove) weighting from cepstral dimensions.
- deltas.m - calculate delta features over a limited window, just like feacalc/calc_deltas etc.
- process_options.m - Mark Paskin's utility to parse long 'name', value pair lists (which I found out about through Kevin Murphy's KPMtools), used by melfcc.m.
- cep2spec.m - inverse of spec2cep, undoes the DCT.
- invpowspec.m - invert powspec.m i.e. go back from an STFT magnitude to a (noise-excited) time waveform.
- ispecgram.m - precisely invert the short-time Fourier transform performed by specgram, taking the same argument (but fudges inverting the window at the moment).
- invaudspec.m - invert audspec i.e. expand the condensed, nonlinear frequency axis to the full FFT detail. Intrinsically lossy, but does its best.
- invpostaud.m - undo the weighting and compression of postaud, mostly lossless except the very edge bands are lost.
You can download the complete set of routines above as
rastamat.tgz (a gzipped tar file).
Examples
An example of calculating various speech features is shown below:
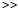 % Load a speech waveform
[d,sr] = wavread('sm1_cln.wav');
% Look at its regular spectrogram
subplot(411)
specgram(d, 256, sr);
% Calculate basic RASTA-PLP cepstra and spectra
[cep1, spec1] = rastaplp(d, sr);
% .. and plot them
subplot(412)
imagesc(10*log10(spec1)); % Power spectrum, so dB is 10log10
axis xy
subplot(413)
imagesc(cep1)
axis xy
% Notice the auditory warping of the frequency axis to give more
% space to low frequencies and the way that RASTA filtering
% emphasizes the onsets of static sounds like vowels
% Calculate 12th order PLP features without RASTA
[cep2, spec2] = rastaplp(d, sr, 0, 12);
% .. and plot them
subplot(414)
imagesc(10*log10(spec2));
axis xy
% Notice the greater level of temporal detail compared to the
% RASTA-filtered version. There is also greater spectral detail
% because our PLP model order is larger than the default of 8
% Load a speech waveform
[d,sr] = wavread('sm1_cln.wav');
% Look at its regular spectrogram
subplot(411)
specgram(d, 256, sr);
% Calculate basic RASTA-PLP cepstra and spectra
[cep1, spec1] = rastaplp(d, sr);
% .. and plot them
subplot(412)
imagesc(10*log10(spec1)); % Power spectrum, so dB is 10log10
axis xy
subplot(413)
imagesc(cep1)
axis xy
% Notice the auditory warping of the frequency axis to give more
% space to low frequencies and the way that RASTA filtering
% emphasizes the onsets of static sounds like vowels
% Calculate 12th order PLP features without RASTA
[cep2, spec2] = rastaplp(d, sr, 0, 12);
% .. and plot them
subplot(414)
imagesc(10*log10(spec2));
axis xy
% Notice the greater level of temporal detail compared to the
% RASTA-filtered version. There is also greater spectral detail
% because our PLP model order is larger than the default of 8
![[rasta and plp spectrograms]](rasta.jpg)
% Append deltas and double-deltas onto the cepstral vectors
del = deltas(cep2);
% Double deltas are deltas applied twice with a shorter window
ddel = deltas(deltas(cep2,5),5);
% Composite, 39-element feature vector, just like we use for speech recognition
cepDpDD = [cep2;del;ddel];
This example calculates 20th order MFCC features (as close as I can get it
to the features we distribute for the uspop2002 Music IR dataset) and then turns them back into audio - pretty weird sounding!
% Read in an mp3 file, downsampled to 22 kHz mono
[d,sr] = mp3read('thompson_twins--Into_The_Gap--Hold_Me_Now--3.mp3',[1 30*22050],1,2);
/usr/bin/mpg123 -2 -m -n 1150 -q -w /tmp/tmp950.wav "thompson_twins--Into_The_Gap--Hold_Me_Now--3.mp3"
soundsc(d,sr)
% Convert to MFCCs very close to those genrated by feacalc -sr 22050 -nyq 8000 -dith -hpf -opf htk -delta 0 -plp no -dom cep -com yes -frq mel -filt tri -win 32 -step 16 -cep 20
[mm,aspc] = melfcc(d*3.3752, sr, 'maxfreq', 8000, 'numcep', 20, 'nbands', 22, 'fbtype', 'fcmel', 'dcttype', 1, 'usecmp', 1, 'wintime', 0.032, 'hoptime', 0.016, 'preemph', 0, 'dither', 1);
% .. then convert the cepstra back to audio (same options)
[im,ispc] = invmelfcc(mm, sr, 'maxfreq', 8000, 'numcep', 20, 'nbands', 22, 'fbtype', 'fcmel', 'dcttype', 1, 'usecmp', 1, 'wintime', 0.032, 'hoptime', 0.016, 'preemph', 0, 'dither', 1);
% listen to the reconstruction
soundsc(im,sr)
% compare the spectrograms
subplot(311)
specgram(d,512,sr)
caxis([-50 30])
title('original music')
subplot(312)
specgram(im,512,sr)
caxis([-40 40])
title('noise-excited reconstruction from cepstra')
% Notice how spectral detail is blurred out e.g. the triangle hits around 6 kHz are broadened to a noise bank from 6-8 kHz.
% save out the reconstruction
max(abs(im))
ans =
3.085
wavwrite(im/4,sr,'HoldMeNow.wav');
![[example of spectrograms before and after MFCC processing]](invmelfcc-example.jpg)
Other Resources
The de-facto standard Matlab implementation of MFCCs for Matlab
is the one in Malcolm Slaney's
Auditory Toolbox. This version has been verified to give
(nearly) identical results, but offers flexibility to adapt to
different bandwidths, sampling rates, etc.
An alternative Matlab implementation of PLP and RASTA can be found in
Fernando Santos Perdigão's Auditory/Cochlea Toolbox.
If you use this code in your research and would like to acknowledge
it (and direct others to it), you could use a reference like this:
@misc{Ellis05-rastamat,
Author = {Daniel P. W. Ellis},
Year = {2005},
Title = {{PLP} and {RASTA} (and {MFCC}, and inversion) in {M}atlab},
Url = {http://www.ee.columbia.edu/~dpwe/resources/matlab/rastamat/},
Note = {online web resource}}
Changes
- 2012-09-03: Added 'useenergy' flag to overwrite C0 with log(E) (thanks to Ines Ben Fredj); fixed bug with equal-loudness mapping in rastaplp.m.
References
- [Herm90]
- H. Hermansky, "Perceptual linear predictive (PLP) analysis of
speech", J. Acoust. Soc. Am., vol. 87, no. 4, pp. 1738-1752, Apr. 1990.
- [HermM94]
- H. Hermansky and N. Morgan, "RASTA processing of speech",
IEEE Trans. on Speech and Audio Proc., vol. 2, no. 4, pp. 578-589,
Oct. 1994.
Last updated: $Date: 2012/09/03 22:59:36 $
Dan Ellis <[email protected]>