In order to create a HMM definition, it is first necessary to produce a prototype definition. As explained in Chapter 7, HMM definitions can be stored as a text file and hence the simplest way of creating a prototype is by using a text editor to manually produce a definition of the form shown in Fig 7.2, Fig 7.3 etc. The function of a prototype definition is to describe the form and topology of the HMM, the actual numbers used in the definition are not important. Hence, the vector size and parameter kind should be specified and the number of states chosen. The allowable transitions between states should be indicated by putting non-zero values in the corresponding elements of the transition matrix and zeros elsewhere. The rows of the transition matrix must sum to one except for the final row which should be all zero. Each state definition should show the required number of streams and mixture components in each stream. All mean values can be zero but diagonal variances should be positive and covariance matrices should have positive diagonal elements. All state definitions can be identical.
Having set up an appropriate prototype, a HMM can be initialised using the HTK tool HINIT. The basic principle of HINIT depends on the concept of a HMM as a generator of speech vectors. Every training example can be viewed as the output of the HMM whose parameters are to be estimated. Thus, if the state that generated each vector in the training data was known, then the unknown means and variances could be estimated by averaging all the vectors associated with each state. Similarly, the transition matrix could be estimated by simply counting the number of time slots that each state was occupied. This process is described more formally in section 8.7 below.
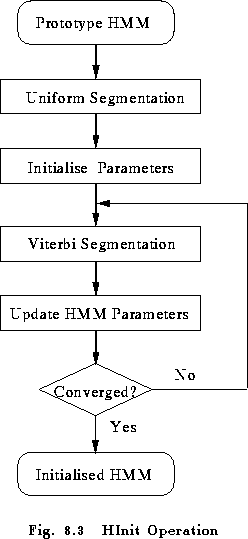
The above idea can be implemented by an iterative scheme as shown in Fig 8.3. Firstly, the Viterbi algorithm is used to find the most likely state sequence corresponding to each training example, then the HMM parameters are estimated. As a side-effect of finding the Viterbi state alignment, the log likelihood of the training data can be computed. Hence, the whole estimation process can be repeated until no further increase in likelihood is obtained.
This process requires some initial HMM parameters to get started. To circumvent this problem, HINIT starts by uniformly segmenting the data and associating each successive segment with successive states. Of course, this only makes sense if the HMM is left-right. If the HMM is ergodic, then the uniform segmentation can be disabled and some other approach taken. For example, HCOMPV can be used as described below.
If any HMM state has multiple mixture components, then the training vectors are associated with the mixture component with the highest likelihood. The number of vectors associated with each component within a state can then be used to estimate the mixture weights. In the uniform segmentation stage, a K-means clustering algorithm is used to cluster the vectors within each state.
Turning now to the practical use of HINIT, whole word models can be initialised by typing a command of the form
HInit hmm data1 data2 data3where hmm is the name of the file holding the prototype HMM and data1, data2, etc. are the names of the speech files holding the training examples, each file holding a single example with no leading or trailing silence. The HMM definition can be distributed across a number of macro files loaded using the standard -H option. For example, in
HInit -H mac1 -H mac2 hmm data1 data2 data3 ...then the macro files mac1 and mac2 would be loaded first. If these contained a definition for hmm, then no further HMM definition input would be attempted. If however, they did not contain a definition for hmm, then HINIT would attempt to open a file called hmm and would expect to find a definition for hmm within it. HINIT can in principle load a large set of HMM definitions, but it will only update the parameters of the single named HMM. On completion, HINIT will write out new versions of all HMM definitions loaded on start-up. The default behaviour is to write these to the current directory which has the usually undesirable effect of overwriting the prototype definition. This can be prevented by specifying a new directory for the output definitions using the -M option. Thus, typical usage of HINIT takes the form
HInit -H globals -M dir1 proto data1 data2 data3 ...
mv dir1/proto dir1/wordX
Here globals is assumed to hold a global
options macro (and possibly others).
The actual HMM definition is loaded from the file proto in the current directory and
the newly initialised definition along with a copy of globals will be written to
dir1. Since the newly created HMM will still be called proto, it is renamed
as appropriate.
For most real tasks, the number of data files required will exceed the command line argument limit and a script file is used instead. Hence, if the names of the data files are stored in the file trainlist then typing
HInit -S trainlist -H globals -M dir1 protowould have the same effect as previously.
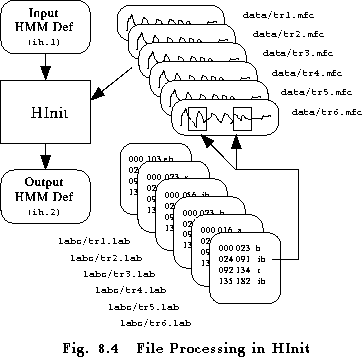
When building sub-word models, HINIT can be used in the same manner as above to initialise each individual sub-word HMM. However, in this case, the training data is typically continuous speech with associated label files identifying the speech segments corresponding to each sub-word. To illustrate this, the following command could be used to initialise a sub-word HMM for the phone ih
HInit -S trainlist -H globals -M dir1 -l ih -L labs proto
mv dir1/proto dir1/ih
where the option -l defines the name of the sub-word model, and
the file trainlist is assumed to hold
data/tr1.mfc
data/tr2.mfc
data/tr3.mfc
data/tr4.mfc
data/tr5.mfc
data/tr6.mfc
In this case, HINIT will first try to find label
files corresponding to each data file. In the example here, the
standard -L option
indicates that they are
stored in a directory called labs. As an alternative, they
could be stored in a Master Label File (MLF) and
loaded via the standard option -I.
Once the label files have been loaded, each data file is scanned and all segments
corresponding the label ih are loaded. Figure 8.4
illustrates this process.
All HTK tools support the -T trace option and although the details of tracing varies from tool to tool, setting the least signicant bit (e.g. by -T 1), causes all tools to output top level progress information. In the case of HINIT, this information includes the log likelihood at each iteration and hence it is very useful for monitoring convergence . For example, enabling top level tracing in the previous example might result in the following being output
Initialising HMM proto . . .
States : 2 3 4 (width)
Mixes s1: 1 1 1 ( 26 )
Num Using: 0 0 0
Parm Kind: MFCC_E_D
Number of owners = 1
SegLab : ih
maxIter : 20
epsilon : 0.000100
minSeg : 3
Updating : Means Variances MixWeights/DProbs TransProbs
16 Observation Sequences Loaded
Starting Estimation Process
Iteration 1: Average LogP = -898.24976
Iteration 2: Average LogP = -884.05402 Change = 14.19574
Iteration 3: Average LogP = -883.22119 Change = 0.83282
Iteration 4: Average LogP = -882.84381 Change = 0.37738
Iteration 5: Average LogP = -882.76526 Change = 0.07855
Iteration 6: Average LogP = -882.76526 Change = 0.00000
Estimation converged at iteration 7
Output written to directory :dir1:
The first part summarises the structure of the HMM, in this case, the data is
single stream MFCC coefficients with energy and deltas appended. The HMM has
3 emitting states, each single Gaussian and the stream width is 26. The current
option settings are then given followed by the convergence information. In this
example, convergence was reached after 6 iterations, however if the maxIter
limit was reached, then the process would terminate regardless.
HINIT provides a variety of command line options for controlling its detailed behaviour. The types of parameter estimated by HINIT can be controlled using the -u option, for example, -u mtw would update the means, transition matrices and mixture component weights but would leave the variances untouched. A variance floor can be applied using the -v to prevent any variance getting too small. This option applies the same variance floor to all speech vector elements. More precise control can be obtained by specifying a variance macro (i.e. a v macro) called varFloor1 for stream 1, varFloor2 for stream 2, etc. Each element of these variance vectors then defines a floor for the corresponding HMM variance components.
The full list of options supported by HINIT is described in the Reference Section.