Applying Hundreds of Visual Concept Detectors for Video Search via Reranking

Summary

In the past few years, some large-scale collections of pre-trained visual concept detectors (such as Columbia374) have been made publicly available. There is great promise for using these detectors (and their resulting detection scores) as semantic representations of the visual content in video and image databases. The exact mechanisms for effectively leveraging this broad set of information to enable semantic search is still an open research topic. We propose to utilize a reranking approach, where we issue a simple initial search (such as a text-based or concept-based search) over the collection and take the top-returned results to be pseudo-positives and the bottom-returned results to be pseudo-negatives. We can then look at the distributions of concept detector scores across the results in each of these sets to learn relevant concepts for the query and then reorder the results.
Concept-based Search
In concept-based search, we are essentially using the space of several hundred concept detectors as an intermediate semantic representation for both visual content and the queries that users are issuing. The detection scores of each of the concept detectors can encapsulate the visual content of the images. Textual keyword queries can then be mapped to concepts via some set of pre-defined lexical relationships. Given the concept-space representation of both queries and images, textual searches can be conducted against visual content by ranking visual documents by their similarity to the query in concept space.
In the figure below, we show an example of this framework might work with a lexicon of five visual concepts ("anchor," "snow," "soccer," "building," and "outdoor," shown at the bottom of the figure). Then, a set of images (shown on the right) can be represented by the detected presence of each of these concepts in the image (shown in the graphs above each image). Similarly, the incoming text queries (shown on the left) can be mapped into similar confidences of the relevance of each concept (shown in the graphs below each query). The search problem then reduces to finding images that have concept distributions similar to the query.
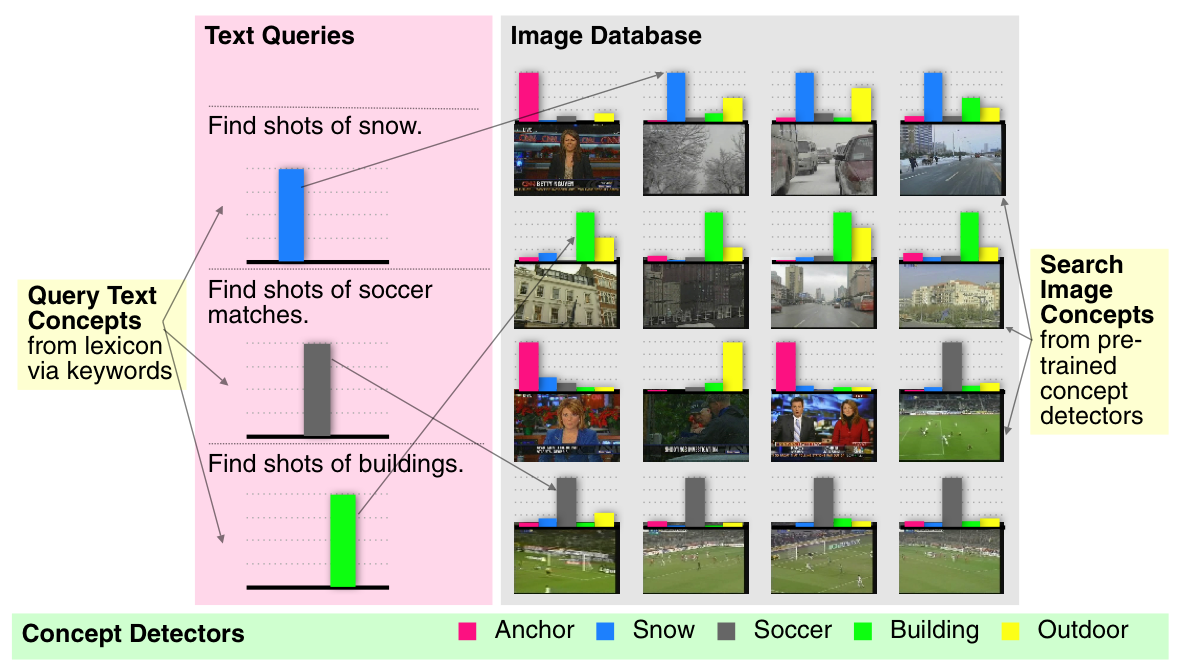
The primary problem here is determining an appropriate method for mapping textual keywords to visual concepts. For example, a query for "Find shots of boats or ships" could directly utilize the "boat/ship" detector, but could also benefit from "sky," "water," and "outdoor" detectors. The relationship between the query and the "boat/ship" detector is very direct and easily discovered, but the relationship with other peripheral concepts is difficult to discover. Similarly, for a query for "Find shots of Condoleezza Rice," there is not directly-matching "Condoleezza Rice" detector, so we would have to be able to discover peripheral concepts, like "government leader," "female," and "face." So, it's intuitive that many concepts can be leveraged to help search. But, discovering the right concepts can be difficult. Most current approaches are very conservative, typically only using the most direct relationships. To address this, we propose a reranking approach.
Reranking Framework
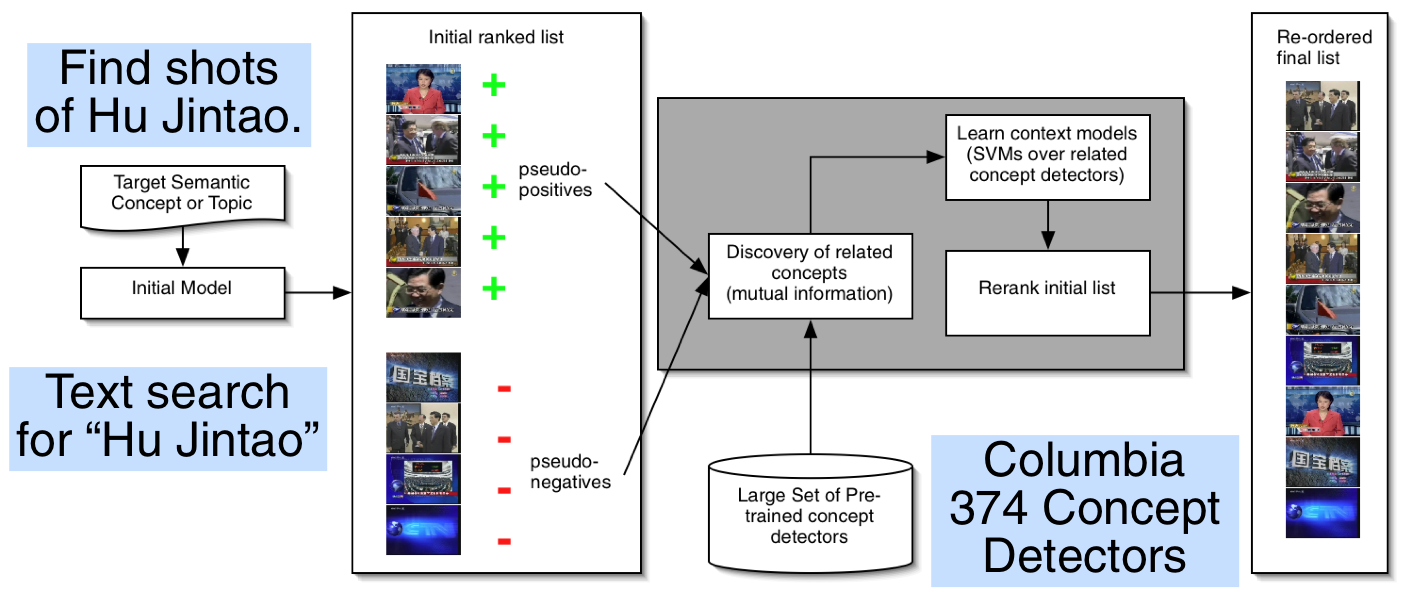
Our proposed reranking framework is shown in the figure below. Instead of trying to infer the peripherally-related concepts directly from the few textual keywords provided by the searcher, we instead issue a simple query first (either using text over text associated with the visual documents, or a simple concept-based search using only the most directly-matching concept). We then take the results of this query and assume that the top-ranking images are positive and the lower-ranking ones are negative. Given the distribution of concepts across these sets of images, we can then discover related concepts by comparing the mutual information between the concept scores and the pseudo-labels. Using the most-related concepts, we can then learn models of the relative importance of each of the concepts and apply them to reorder the initial search results.
Experiments and Results
We evaluate the approach against the TRECVID 2005 and 2006 automatic seach task. We compare against the baselines of using (1) simple text-based search over the speech recognition transcripts (2) simple concept-based search and (3) a fusion of both of those approaches. By reranking the results of any of these baseline methods, we see small, but consistent, improvement over all queries, and an improvement in mean average precision (MAP) of between 15% and 30%, depending on the baseline.
We also explore the types of concept relationships that the system discovers. For each of the concepts, we measured the strength of its relationship with the pseudo-labels of the initial results using mutual information. Here, we further classify the relationships as either positive (the concept should be present) or negative (the concept should be absent) using point-wise mutual information, which is defined as follows:

Interesting discovered query/concept relationships are then shown in figure below.
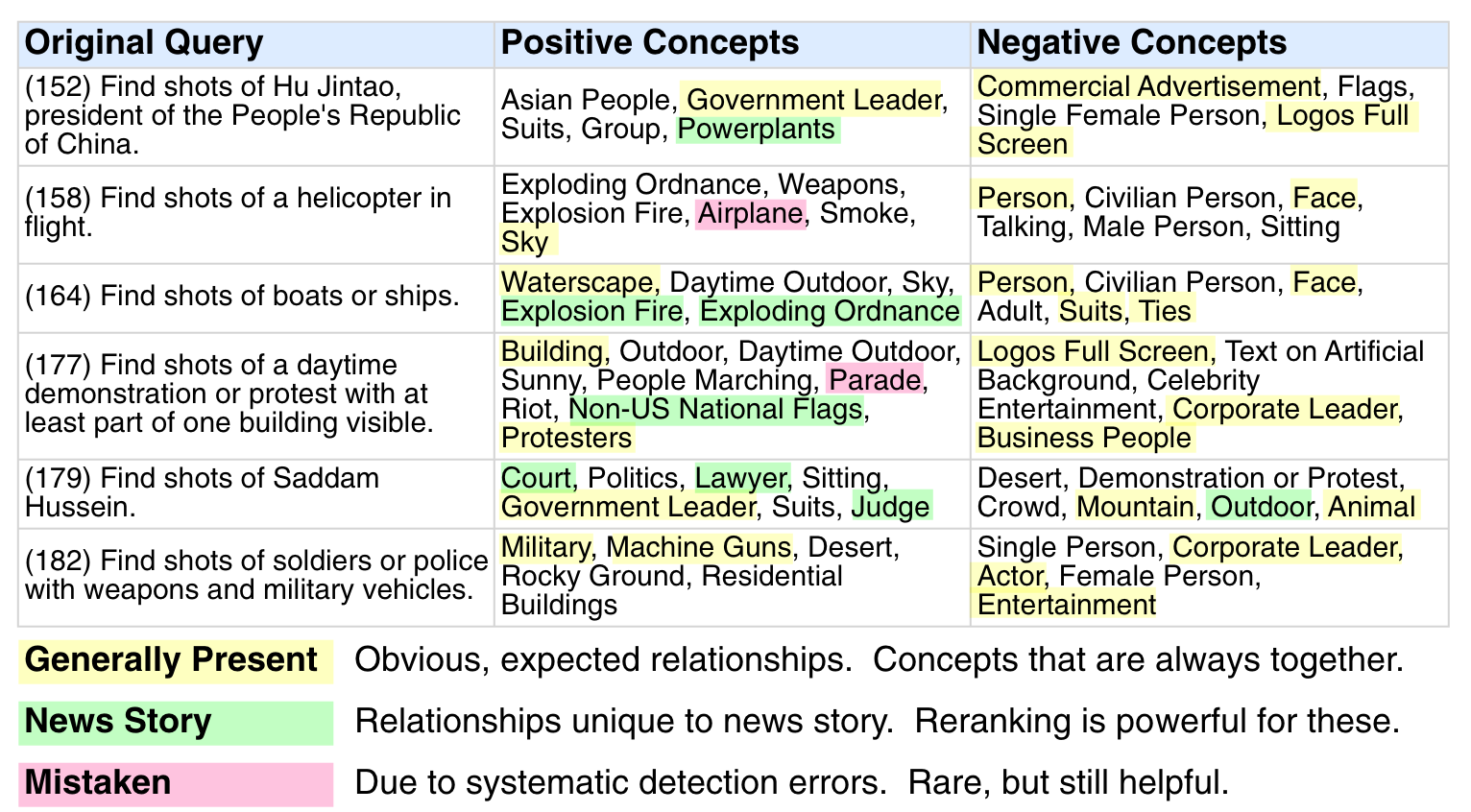
We generally classify the results into three types of relationships: "generally present," "news story," and "mistaken." The "generally present" class represents the types of relationships that we would intuitively expect to arise from such a statistical approach: it it not surprising that the "sky" concept is related to the "helicopter" query or that "waterscapes" are related to the "boats and ships" query. The "news story" class contains an interesting set of relationships that are due to the news stories present in the search set. We would not expect to find that "explosion/fire" is related to a query for "boats and ships," but, indeed, there was a big news story in our search set about a boat that had caught fire. Similarly, "court," "lawyer," and "judge" concepts are not typically related to "Saddam Hussein," but, during the period of time covered by our search set, the trial of Saddam Hussein was a top news story. Finally, there is a class that we term "mistaken," which feeds on relationships between true-positive visual examples and faulty concept detectors. For example, given the low-level representation of images, "helicopters" will look like "airplanes," so, even though a helicopter is not an airplane, shots that have high scores for "airplane" are still likely to contain "helicopters." Similarly, a "parade" might look like "protest" to our detectors. Interestingly, these errors are still helpful for reranking.
People
Publications
![]()
-
Lyndon Kennedy, Shih-Fu Chang. A Reranking Approach for Context-based Concept Fusion in Video Indexing and Retrieval. In ACM International Conference on Image and Video Retrieval, Amsterdam, Netherlands, July 2007. [pdf]
- Shih-Fu Chang, Lyndon Kennedy, Eric Zavesky. Columbia University's Semantic Video Search Engine. In ACM International Conference on Image and Video Retrieval, Amsterdam, Netherlands, July 2007. [pdf]
Demo
Columbia Concept-based Video Seach Engine (link)
Columbia CuVid Video Search Engine (link)
Related Projects
- Large Scale Concept Ontology for Multimedia (LSCOM)
- Download: Columbia University’s Baseline Detectors for 374 LSCOM Semantic Visual Concepts
- Download: Columbia Story Boundary Data Set for TRECVID 2005
- IBM Research TRECVID 2006 Video Retrieval Evaluation
- Columbia University TRECVID-2006 Video Search and High-Level Feature Extraction
Sponsor
IARPA VACE Program
![]()
For problems or questions
regarding this web site contact The
Web Master.
Last updated: Sept. 30th, 2008.