
NIST TRECVID 2003 Video Retrieval Evaluation

Summary

The main goal of the TREC Video Retrieval Evaluation (TRECVID) is to promote progress in content-based retrieval of digital video via open, metrics-based evaluation. TRECVID is a laboratory-style evaluation that attempts to model real world situations or significant component tasks involved in such situations. There are four main tasks in TRECVID 2003, including shot boundary determination, story segmentation detection, high-level feature extraction and search.
Story Segmentation
Story segmentation in news video is not a new topic, but there has never been any systematic benchmarking event conducted to assess the state of the art. In 2003, we participated in the task of news story segmentation in TREC Video.
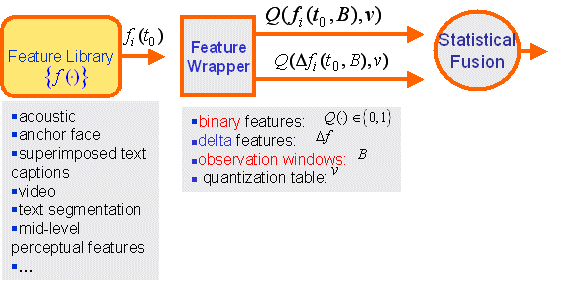
We utilize a statistical framework to fuse a large set (close to 200) of computational and mid-level perceptual features from visual, audio and text (ASR) modalities, as the figure below. We investigate salient mid-level perceptual features of motion, face, music/speech discrimination, pitch, significant pause, speech speed, commercials and cue terms extracted from ASR and video-OCR, and also demonstrate how these features contribute to the story boundaries individually and integrally. We also address the issues of boundary candidate selection and training label assignment arising from multi-modal fusion. We then propose a novel feature wrapper (shown below) that successfully fuses multi-modal, asynchronous, discrete or continuous features with different temporal granularity. Besides, the feature wrapper is capable of generating delta features, determining feature quantization levels and effective observation window size. Automatic selection of features and optimal parameters are achieved based on statistical gains, the reduction of Kullback-Leibler divergence, measured based on the definition in the Maximum Entropy (Exponential) model.
Extensive test data includes 218 half-hour sequences from ABC and CNN showing diverse production syntax and styles. Complete precision/recall results were reported, including the F1 measure ranging between 0.7 and 0.75. The results are very encouraging, but also indicative of challenging issues that can be further explored, including large spatial-temporal feature modeling, and pattern mining.
Overlay Text Detection
In 2002, we participated in the text overlay detection task (part of the feature detection task) in NIST TREC Video event, through collaboration with IBM Research. Our system is based on fusion of the following detection algorithms. It achieved the highest accuracy among all the systems responded to this task.
The first approach (Columbia U.) uses a multiple hypothesis testing approach.
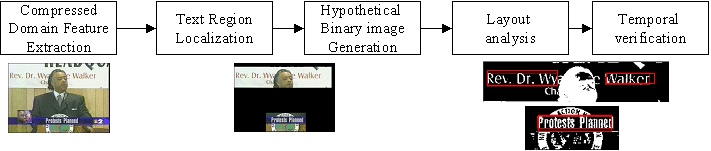
The region-of-interests (ROI) potentially containing the overlay texts
are decomposed into several
hypothetical binary images using color space partitioning. A grouping
algorithm then is used
to group the identified character blocks into text lines in each binary
image. Layout of the
grouped text lines are examined for conformance testing. Finally, motion
verification is used to reduce false alarms. In order to achieve real
time speed, ROI localization is realized using compressed domain features
including DCT coefficients and motion vectors in MPEG videos. The proposed
method showed promising results with average recall 96.9% and precision
71.6% when tested on broadcast news video.
The above detection system was statistically fused with another detection system developed in IBM. The combined system achieved the highest detection performance among systems responding to this task. The following figure shows several detection examples.
People
- Winston Hsu
- Dongqing Zhang
- Lyndon Kennedy
- Chih-wei Huang
- Prof. Shih-Fu Chang
in collaboration with IBM Research
Publication
Story Segmentation
Winston Hsu, Shih-Fu Chang,
Chih-Wei Huang, Lyndon Kennedy, Ching-Yung Lin, and Giridharan Iyengar,
"Discovery and Fusion of Salient Multi-modal Features towards News
Story Segmentation," to appear in SPIE/Electronic Imaging, Jan. 18-22,
2004, San Jose, CA. (PDF)
Winston Hsu, Lyndon Kennedy, Chih-Wei Huang, Shih-Fu Chang, Ching-Yung Lin, and Giridharan Iyengar, "News Video Story Segmentation using Fusion of Multi-Level Multi-modal Features in TRECVID 2003," conference paper, submitted. (PDF)
Gary Huang, Winston Hsu, Shih-Fu Chang, "Automatic Closed Caption Alignment Based on Speech Recognition Transcripts," Columbia DVMM Technical Report 005, 2003.(PDF)
Winston Hsu, Shih-Fu Chang, "A Statistical Framework for Fusing Mid-level Perceptual Features in News Story Segmentation," IEEE International Conference on Multimedia & Expo (ICME) 2003, invited paper.(PS.GZ/PDF), slides.
Overlay Text Detection
Dongqing Zhang, Belle L. Tseng, Ching-Yung Lin and Shih-Fu Chang, "Accurate Overlay Text Extraction for Digital Video Analysis", Proceeding of IEEE International Conference on Information Technology: Research and Education (ITRE 2003). (PS.GZ/PDF)
Belle L. Tseng, Ching-Yung Lin, DongQing Zhang, "Improved Text Overlay Detection in Videos Using a Fusion-Based Classifier", In Proceeding of IEEE Conference of Multimedia and Expo (ICME) 2003.
D. Zhang and S.-F. Chang, Accurate
Overlay Text Extraction for Digital Video Analysis, Columbia University
ADVENT Technical Report #005, 2002.
(PS.GZ/PDF)
(DQ: include the paper by Dorai of IBM)
Links
- DVMM Research Project: News Story Segmentation Using Statistical Fusion of Multi-modal
- DVMM Research Project: Text Overlay Detection, Recognition with Bayesian Fusion
- DVMM Research Project: 3D Scene Text Detection
- Official TRECVID 2003 Website
![]()
For problems or questions
regarding this web site contact The
Web Master.
Last updated: October 05, 2003.