Dan Ellis: Research
Projects:
Voice Transformation
|
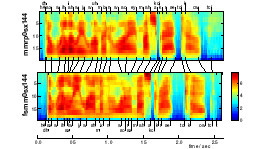
Spectrograms of two people speaking the same phrase, with the changing alignments of their corresponding phones shown in-between. This image is also available as a larger, scalable PDF file.
|
Voice transformation is the process of modifying an utterance from a
particular speaker to make it sound as if it was spoken by a
specific different speaker. This transformation might involve modifications
to any aspect of the signal that carries speaker identity, for instance:
- Formant spectra i.e. the coarse spectral structure associated
with the different phones in the speech. This is the most common
target of voice transformation algorithms, which work by constructing
a map between the formant spectra of the two voices (represented, for
instance, in the cepstral domain). See for example
Kain & Macon, 2001 "Design and evaluation of a voice conversion algorithm..." (which I got from Alex Kain's web site.
- Excitation function i.e. the `fine' spectral detail held
in the residual excitation after the broad spectra shape has been
flattened. There is evidence that this provides useful information
for speaker identification (e.g. indirect evidence from automatic
speaker identification based on whitened residual:
Yegnanarayana et al., Source and system features for speaker recongnition ....
- Prosodic features i.e. aspects of the speech that occur over
timescales larger than individual phonemes, such as fundamental
frequency (pitch), timing, and their patterns of variation.
- Mannerisms such as particular word choice or preferred phrases,
or all kinds of other very high-level behavioral characteristics that
we notice about our interlocutors.
These attributes cover a very wide range of properties. It's probably
true that for all of them, we don't really understand which properties
are most important for speaker identity, or how to modify them. However,
for the lower-level characteristics, good progress has been made.
What is the interest in speaker transformation? As an end in itself, it has
some limited use for anonymity and entertainment applictions, but this is
only a small part. By attempting both to analyze and then to synthesize
voices such that the message and speaker identity can be completely
separated, we will inevitably end up with a better understanding of how
both these aspects are represented in the signal. Thus, by looking at
voice transformation, we can learn things useful for:
- Speech coding: The problem of analyzing voice into a
suitably abstract domain so that it can be regenerated with a
convincing different speaker identity would give the kind of high-level
description that could be very useful for high-complexity, ultra-low
bandwidth voice communications. For instance, rather than resynthesizing
as a different speaker, resynthesize as the same speaker, but transmit
only the global speaker description, and whatever non-speaker-related
information residual is left for the actual speech.
- Speech synthesis: Implicit in the vision of the future
speech coder is a speech synthesis algorithm capable of reproducing
voice that sounds like any real speaker, based only on some high-level
speaker characteristics parameters. Although this is not necessarily
the same as a pure text-to-speech (since we are starting with a spoken
utterance, not a text stream), it could amount to something very
similar (i.e. the ultra-low bandwidth transmission might be something
very similar to the text of the message).
- Speech recognition: Also implicit in the coding scenario
is the idea of an analysis module able to identify and separate
speaker characteristics and content parameters. But even without
the (far-fetched?) transmission application, looking closely at
the speech signal and the nature of speech variation should help
us to improve recognition. For instance, current speech recognition
systems use almost no information other than the coarse spectral
structure (i.e. formant spectrum), and achieve speaker independence
essentially by averaging over all speakers in their training sets -
in contrast to the sense of `homing in' on a particular speaker's
voice or accent that we have as human listeners. A good understanding
and model of what attributes we are learning when we `home in'
could lead to much more detailed and accurate speech signal models
for recognizer front-ends.
Timing -- i.e. the duration of each successive speech sound -- is an
interesting example. Speech recognizer front-ends usually include some kind
of duration modeling (to discount very unlikely events, such as a vowel
that lasts 10 seconds), but the models are very weak because, again, they
are averaged across entire training sets which include all kinds of fast
and slow speech. The problem is made harder because people can vary their
rate of speech quite signficantly within a single phrase. However, it is
unlikely that there is no useful information to be obtained from
speech segment durations -- but to find out what it is, we need to look
at the variations in speech timing and gain a better understanding of
the existing patterns and available constraints.
This project might follow the outline below:
- Duplication of spectrally-based voice transformation results,
for instance by joint modeling of time-aligned parameters for pairs
of speakers, perhaps in LSP space.
- Investigation into generalizing these kinds of transformations based
on small amounts of example data, or on non-matching data.
- Examination of phone timing data: spread of phone duration, differences
in average and spread of duration variation between speakers,
patterns of speech rate within phrases.
- Assess viability of automatic transformation between timing patterns
of different speakers.
- Similar explorations for fundamental frequency.
- Application of some of the results for improved speech recognizer
front-ends.
Last updated: $Date: 2001/05/29 00:05:04 $
Dan Ellis <[email protected]>