Dan Ellis :
Music Content Analysis :
Practical :
A Practical Investigation of Singing Detection:
5. Temporal Smoothing
As we saw in the last example, our frame-by-frame classifications vary
very rapidly, with the likelihood ratio (or MLP output) varying wildly
from frame to frame. This is in stark contrast to the labeling data
we have (and, by extension, the kind of results we'd like to get from
our classifier) where the class stays the same for many successive frames.
Perhaps by somehow constraining our classifier to behave like this too,
we can improve accuracy.
There are two ways we can approach this, the heuristic signal-processing way,
and the probabilistic, principled way. The heuristic approach is simply to
smooth the raw classification variable along the time dimension, essentially
replacing the value at each time frame with a kind of weighted average of
the values over a wider window. This is equivalent to low-pass filtering
the decision variable (e.g. the log-likelihood ratio) prior to applying
the hard decision threshold. Thus, for our previous example:
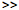 % Try using a 1 second (50-frame) raised-cosine averaging window
LRaS = conv(hanning(51)/sum(hanning(51)), LRa);
% Need to trim ends to make it line up properly
LRaS = LRaS(25 + [1:length(LRa)]);
% Now what's the classification?
mean((LRaS>0)==lsamp')
ans =
0.5209
% Hmm, no better. Let's look at it
subplot(311)
plot(tt, lsamp);
axis([0 265.3 0 1.2])
title('Ground truth')
subplot(312)
plot(tt, LRa, tt, LRaS)
axis([0 265.3 -2.5 2.5])
% Try using a 1 second (50-frame) raised-cosine averaging window
LRaS = conv(hanning(51)/sum(hanning(51)), LRa);
% Need to trim ends to make it line up properly
LRaS = LRaS(25 + [1:length(LRa)]);
% Now what's the classification?
mean((LRaS>0)==lsamp')
ans =
0.5209
% Hmm, no better. Let's look at it
subplot(311)
plot(tt, lsamp);
axis([0 265.3 0 1.2])
title('Ground truth')
subplot(312)
plot(tt, LRa, tt, LRaS)
axis([0 265.3 -2.5 2.5])
When we look at the smoothed log-likelihood ratio, it looks like it might
be useful, but the threshold of 0 seems a little too high - almost all frames
are being classified as unsung. Maybe we can find a better threshold:
% Try thresholds over a range (training on the test data...)
th = linspace(-2.5, 2.5); % Linear range of thresholds
pp = 0*th;
for i = 1:length(th); pp(i) = mean((LRaS > th(i)) == lsamp'); end
max(pp)
ans =
0.8686
% Wow, best threshold is much better. What is it?
thopt = th(find(pp==max(pp)))
thopt =
-0.4798
% But remember, we couldn't have found this without already knowing the ground-truth answer (lsamp)
% Plot the regions defined by the new threshold
subplot(313)
plot(tt,LRaS,[0 265.3], [thopt thopt], tt, (LRaS > thopt))
axis([0 265.3 -3 3])
![[Image of smoothed ratio with optimal threshold]](smoo.jpg)
We said this approach was heuristic; a more principled way to
incorporate temporal constraints is to use a hidden Markov model (HMM)...
This part still needs to be written!
Assignment
Write a script to take an arbitrary file name as input and generate the
per-frame singing/not singing labels as output. You can use any classifier,
feature set, etc., that you like. We can then test it on
(yet another) unseen test example, and compare everyone's results.
The output of your script should be a single binary vector with one value for each 20ms of the soundfile, where a 1 means that time frame is judged to contain voice.
When you're ready to test your system, just send me an email asking how to get hold of the final evaluation data.
Last updated: $Date: 2003/07/02 23:10:49 $
Dan Ellis <[email protected]>