Dan Ellis :
Music Content Analysis :
Practical :
A Practical Investigation of Singing Detection:
4. Evaluation
Although measuring performance on the training data lets you know if your
classifier is learning anything at all, it's not a good predictor of
performance in the real world, since unseen test data will differ from
the training data in unpredictable ways. Thus, final evaluation is
normally performed on held-out data that was not used at all in tuning
the system parameters. Of course, depending on the amount and variety of
this data, it may still give an inaccurate estimate of the average system
performance, but at least it is a fair test.
We can evaluate our models so far on a new piece of data, a single (entire)
pop song which has also been hand-labeled for vocal portions. We need to
calculate the same features and labels for it, run the classifiers, then
compare the results:
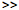 % Load the new test data waveform (warning: it's big - you'll need several 100M of memory)
[d,sr] = wavread('aimee.wav');
cc = mfcc(d,sr,1/0.020);
% load the labels
[stt,dur,lab] = textread(['aimee.lab'], '%f %f %s','commentstyle','shell');
ll = zeros(length(lab),1);
ll(strmatch('vox',lab)) = 1;
size(cc)
ans =
13 13263
% Define a new timebase for this file
tt = 0.020*[1:13263];
% .. and sample the labels
lsamp = labsamplabs(tt,[stt,dur],ll);
% See if we can get a spectrogram of the whole thing
subplot(311)
% (downsample audio before taking spectrogram, to save space)
specgram(resample(d,800,2205),256,8000)
% .. and plot the ground-truth labels next to it
subplot(312)
plot(tt,lsamp)
% How long is the song exactly?
length(d)/sr
ans =
265.2735
% Set the axes to match the spectrogram
axis([0 265.3 0 1.1])
% Finally, plot the log likelihood ratio too
subplot(313)
LRa = log(gmmprob(gmS,cc([1:2],:)')./gmmprob(gmM,cc([1:2],:)'));
plot(tt, LRa)
% We only care about values close to 0
axis([0 265.3 -5 5])
% How's the classification accuracy?
mean((LRa>0)==lsamp')
ans =
0.5221
% Pretty much guessing!
% Load the new test data waveform (warning: it's big - you'll need several 100M of memory)
[d,sr] = wavread('aimee.wav');
cc = mfcc(d,sr,1/0.020);
% load the labels
[stt,dur,lab] = textread(['aimee.lab'], '%f %f %s','commentstyle','shell');
ll = zeros(length(lab),1);
ll(strmatch('vox',lab)) = 1;
size(cc)
ans =
13 13263
% Define a new timebase for this file
tt = 0.020*[1:13263];
% .. and sample the labels
lsamp = labsamplabs(tt,[stt,dur],ll);
% See if we can get a spectrogram of the whole thing
subplot(311)
% (downsample audio before taking spectrogram, to save space)
specgram(resample(d,800,2205),256,8000)
% .. and plot the ground-truth labels next to it
subplot(312)
plot(tt,lsamp)
% How long is the song exactly?
length(d)/sr
ans =
265.2735
% Set the axes to match the spectrogram
axis([0 265.3 0 1.1])
% Finally, plot the log likelihood ratio too
subplot(313)
LRa = log(gmmprob(gmS,cc([1:2],:)')./gmmprob(gmM,cc([1:2],:)'));
plot(tt, LRa)
% We only care about values close to 0
axis([0 265.3 -5 5])
% How's the classification accuracy?
mean((LRa>0)==lsamp')
ans =
0.5221
% Pretty much guessing!
![[Image comparing ground-truth and estimated labels]](eval.jpg)
Assignment
For a given feature set, try changing the model complexity (number of mixtures or hidden layer size) to see how the accuracy varies on training and on test data. Can you show the classic 'overfitting' divergence between consistently improving training data performance, and improving then worsening test accuracy?
Last updated: $Date: 2003/07/02 15:39:37 $
Dan Ellis <[email protected]>