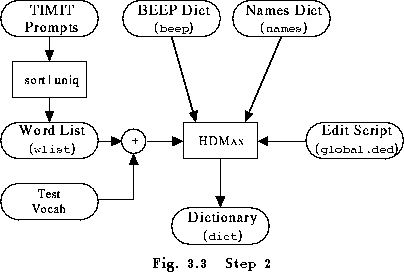
The first step in building a dictionary is to create a sorted list of the required words. In the telephone dialling task pursued here, it is quite easy to create a list of required words by hand. However, if the task were more complex, it would be necessary to build a word list from the sample sentences present in the training data. Furthermore, to build robust acoustic models, it is necessary to train them on a large set of sentences containing many words and preferably phonetically balanced. For these reasons, the training data will consist of English sentences unrelated to the phone recognition task. Below, a short example of creating a word list from sentence prompts will be given. As noted above the training sentences given here are extracted from some prompts used with the TIMIT database and for convenience reasons they have been renumbered. For example, the first few items might be as follows
S0001 ONE VALIDATED ACTS OF SCHOOL DISTRICTS
S0002 TWO OTHER CASES ALSO WERE UNDER ADVISEMENT
S0003 BOTH FIGURES WOULD GO HIGHER IN LATER YEARS
S0004 THIS IS NOT A PROGRAM OF SOCIALIZED MEDICINE
etc
The desired training word list (wlist) could then be
extracted automatically from these. Before using HTK, one would need to edit
the text into a suitable format. For example, it would be necessary to change
all white space to newlines and then to use the UNIX utilities sort
and uniq to sort the words into a unique alphabetically ordered set,
with one word per line. The script prompts2wlist from the
HTKTutorial directory can be used for this purpose.
The dictionary
itself can be built from a standard source
using HDMAN .
For this example, the British English BEEP pronouncing dictionary will be
used .
Its phone set will be adopted without modification except that
the stress marks will be removed and a short-pause (sp) will
be added to the end of every pronunciation. These changes
can be applied using HDMAN and an
edit script (stored in global.ded)
containing the two commands
.
Its phone set will be adopted without modification except that
the stress marks will be removed and a short-pause (sp) will
be added to the end of every pronunciation. These changes
can be applied using HDMAN and an
edit script (stored in global.ded)
containing the two commands
AS sp RS cmuwhere cmu refers to a style of stress marking in which the lexical stress level is marked by a single digit appended to the phone name (e.g. eh2 means the phone eh with level 2 stress).
The command
HDMan -m -w wlist -n monophones1 -l dlog dict beep nameswill create a new dictionary called dict by searching the source dictionaries beep and names to find pronunciations for each word in wlist (see Fig 3.3). Here, the wlist in question needs only to be a sorted list of the words appearing in the task grammar given above.
Note that names is a manually constructed file containing pronunciations for the proper names used in the task grammar. The option -l instructs HDMAN to output a log file dlog which contains various statistics about the constructed dictionary. In particular, it indicates if there are words missing. HDMAN can also output a list of the phones used, here called monophones1. Once training and test data has been recorded, an HMM will be estimated for each of these phones.
The general format of each dictionary entry is
WORD [outsym] p1 p2 p3 ....which means that the word WORD is pronounced as the sequence of phones p1 p2 p3 .... The string in square brackets specifies the string to output when that word is recognised. If it is omitted then the word itself is output. If it is included but empty, then nothing is output.
To see what the dictionary is like, here are a few entries.
A ah sp
A ax sp
A ey sp
CALL k ao l sp
DIAL d ay ax l sp
EIGHT ey t sp
PHONE f ow n sp
SENT-END [] sil
SENT-START [] sil
SEVEN s eh v n sp
TO t ax sp
TO t uw sp
ZERO z ia r ow sp
Notice that function words such as A and TO
have multiple pronunciations.
The entries for SENT-START and SENT-END have a silence
model sil as their pronunciations and null output symbols.