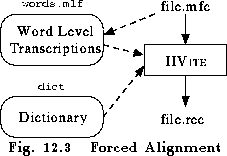
HVITE can be made to compute forced alignments by not specifying a network with the -w option but by specifying the -a option instead. In this mode, HVITE computes a new network for each input utterance using the word level transcriptions and a dictionary. By default, the output transcription will just contain the words and their boundaries. One of the main uses of forced alignement , however, is to determine the actual pronunciations used in the utterances used to train the HMM system in this case, the -m option can be used to generate model level output transcriptions.
This type of forced alignment is usually part of a bootstrap
process, initially models are trained on the basis of one fixed
pronunciation per
word .
Then HVITE is used in forced alignment mode
to select the best matching pronuciations. The new phone level
transcriptions can then be used to retrain the HMMs. Since training
data may have leading and trailing silence, it is usually
necessary to insert a silence model at the start and end of the
recognition network. The -b option can be used to do this.
.
Then HVITE is used in forced alignment mode
to select the best matching pronuciations. The new phone level
transcriptions can then be used to retrain the HMMs. Since training
data may have leading and trailing silence, it is usually
necessary to insert a silence model at the start and end of the
recognition network. The -b option can be used to do this.
As an illustration, executing
HVite -a -b sil -m -o SWT -I words.mlf -H hmmset dict hmmlist file.mfcwould result in the following sequence of events (see Fig. 12.3). The input file name file.mfc would have its extension replaced by lab and then a label file of this name would be searched for. In this case, the MLF file words.mlf has been loaded. Assuming that this file contains a word level transcription called file.lab, this transcription along with the dictionary dict will be used to construct a network equivalent to file.lab but with alternative pronunciations included in parallel. Since -b option has been set, the specified sil model will be inserted at the start and end of the network. The decoder then finds the best matching path through the network and constructs a lattice which includes model alignment information. Finally, the lattice is converted to a transcription and output to the label file file.rec. As for testing on a database, alignments will normally be computed on a large number of input files so in practice the input files would be listed in a .scp file and the output transcriptions would be written to an MLF using the -i option.
When the -m option is used, the transcriptions output by HVITE would by default contain both the model level and word level transcriptions . For example, a typical fragment of the output might be
7500000 8700000 f -1081.604736 FOUR 30.000000
8700000 9800000 ao -903.821350
9800000 10400000 r -665.931641
10400000 10400000 sp -0.103585
10400000 11700000 s -1266.470093 SEVEN 22.860001
11700000 12500000 eh -765.568237
12500000 13000000 v -476.323334
13000000 14400000 n -1285.369629
14400000 14400000 sp -0.103585
Here the score alongside each model name is the acoustic score for that segment.
The score alongside the word is just the language model score.
Although the above information can be useful for some purposes, for example in bootstrap training, only the model names are required. The formatting option -o SWT in the above suppresses all output except the model names.