CDC: Convolutional-De-Convolutional Networks for Precise Temporal Action Localization in Untrimmed Videos
Zheng Shou, Jonathan Chan, Alireza Zareian, Kazuyuki Miyazawa, and Shih-Fu Chang.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. (oral presentation)
Abstract
Temporal action localization is an important yet challenging problem. Given a long, untrimmed video consisting of multiple action instances and complex background contents, we need not only to recognize their action categories, but also to localize the start time and end time of each instance. Many state-of-the-art systems use segment-level classifiers to select and rank proposal segments of pre-determined boundaries. However, a desirable model should move beyond segment-level and make dense predictions at a fine granularity in time to determine precise temporal boundaries. To this end, we design a novel Convolutional-De-Convolutional (CDC) network that places CDC filters on top of 3D ConvNets, which have been shown to be effective for abstracting action semantics but reduce the temporal length of the input data. The proposed CDC filter performs the required temporal upsampling and spatial downsampling operations simultaneously to predict actions at the frame-level granularity. It is unique in jointly modeling action semantics in space-time and fine-grained temporal dynamics. We train the CDC network in an end-to-end manner efficiently. Our model not only achieves superior performance in detecting actions in every frame, but also significantly boosts the precision of localizing temporal boundaries. Finally, the CDC network demonstrates a very high efficiency with the ability to process 500 frames per second on a single GPU server. Source code and trained models are available online at https://bitbucket.org/columbiadvmm/cdc.
Citing
@inproceedings{cdc_shou_cvpr17,
author = {Zheng Shou and Jonathan Chan and Alireza Zareian and Kazuyuki Miyazawa and Shih-Fu Chang},
title = {CDC: Convolutional-De-Convolutional Networks for Precise Temporal Action Localization in Untrimmed Videos},
year = {2017},
booktitle = {CVPR}
}
Downloads
The Framework and Network Architecture
CDC Framework. Given an input raw video, it is fed into our CDC localization network, which consists of 3D ConvNets for semantic abstraction and a novel CDC network for dense score prediction at the frame-level. Such fine-granular score sequences are combined with segment proposals to detect action instances with precise boundaries.
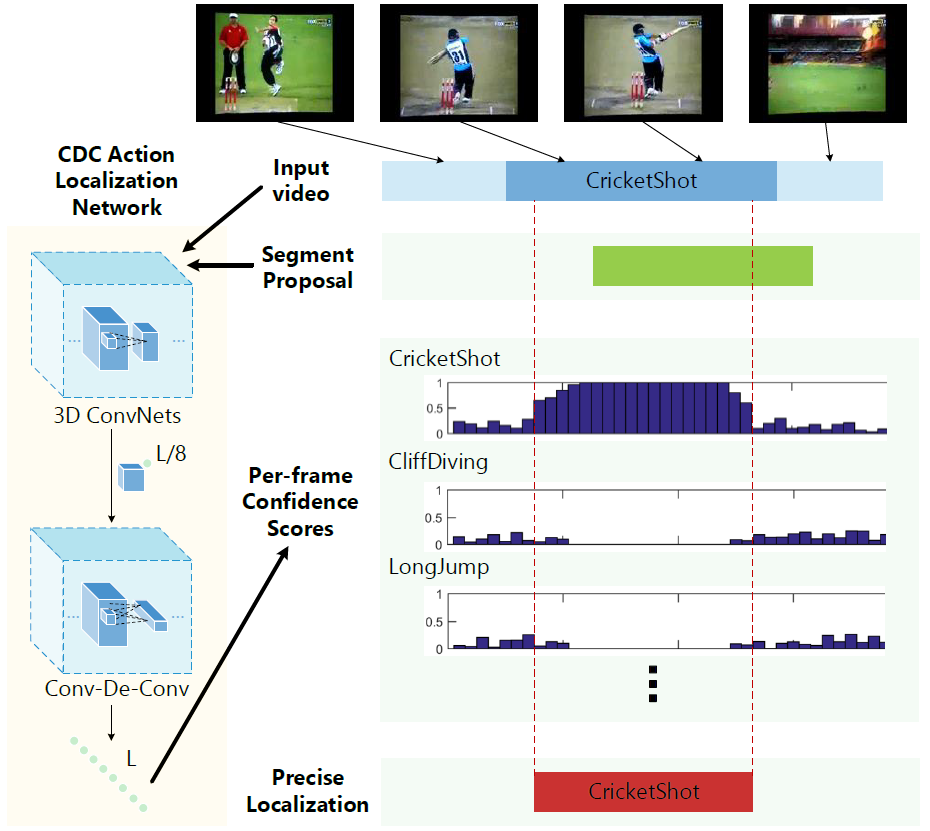
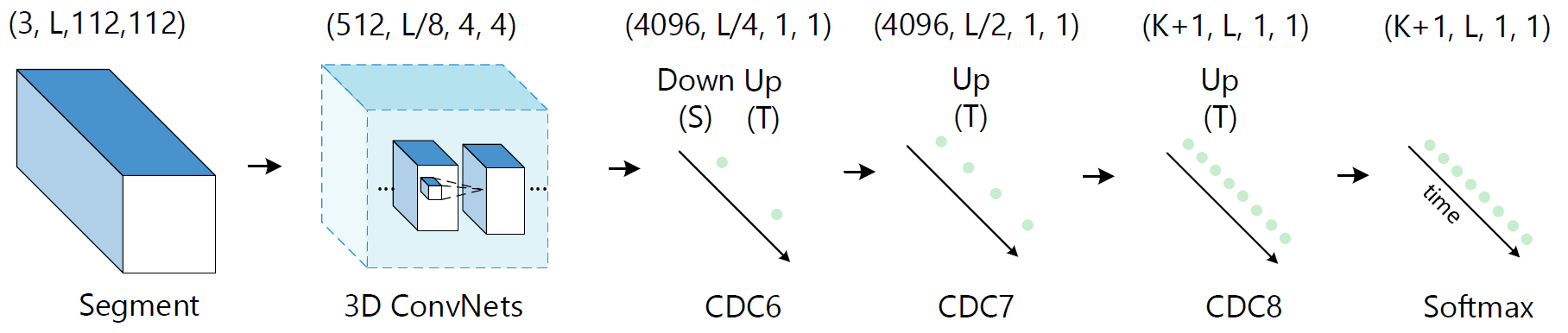
Network architecture.
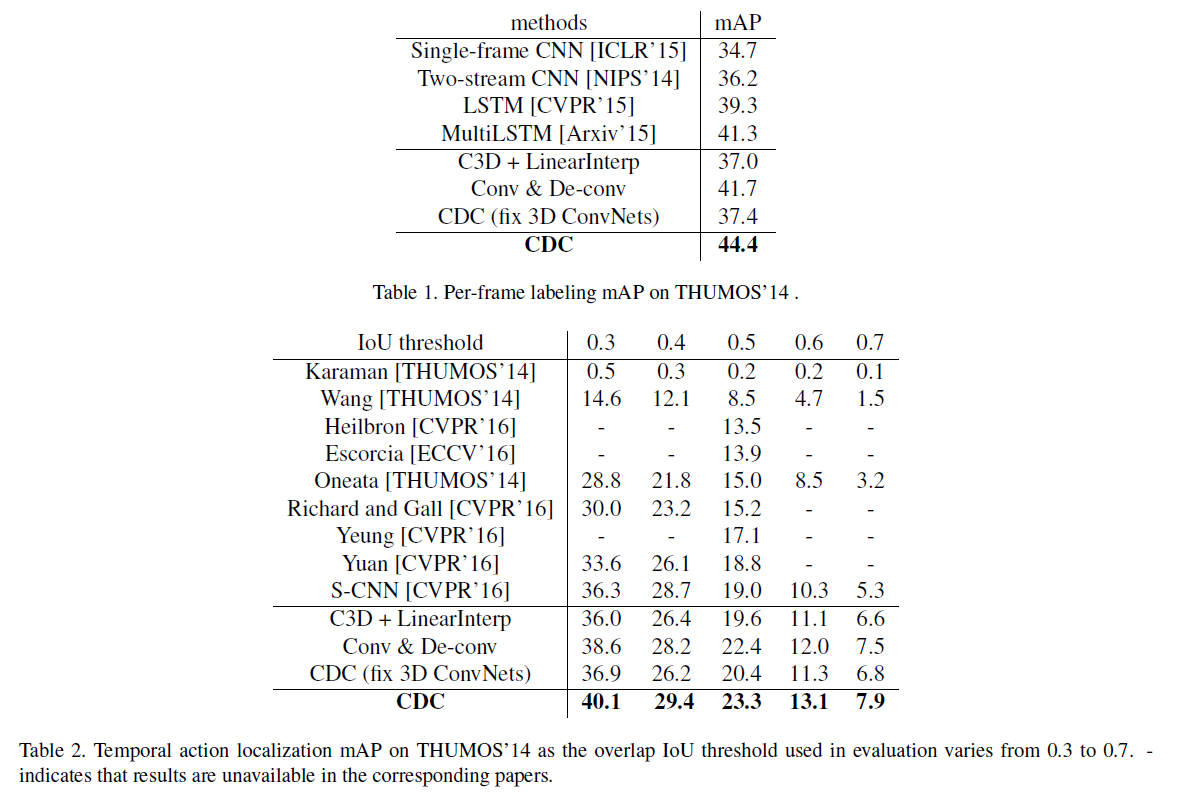
Results on THUMOS'14
Please refer to the paper for more details.
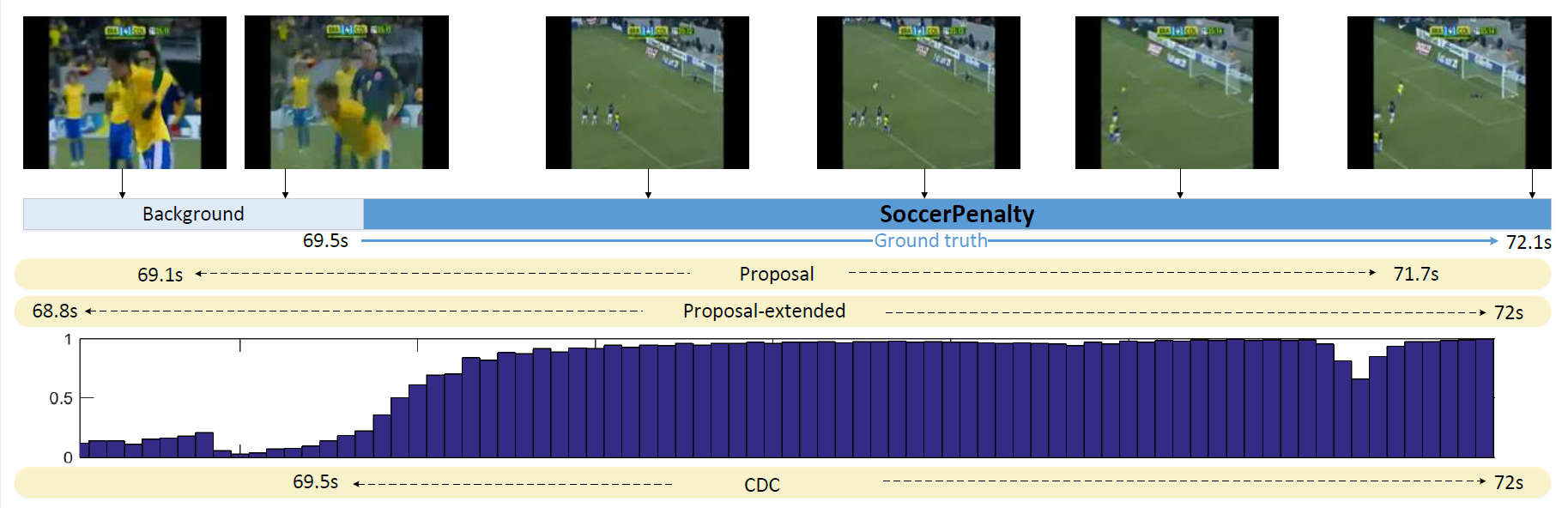
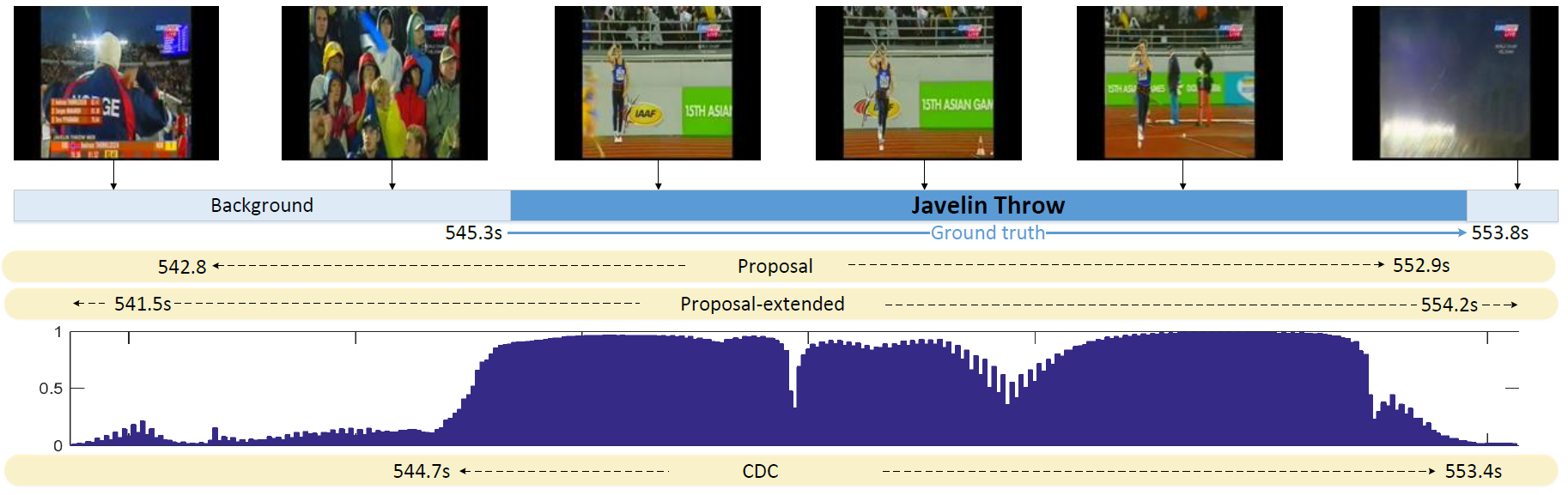
Visualization Examples
Horizontal axis stands for time. From the top to the bottom: (1) frame-level ground truths for a SoccerPenalty action instance in a test video with some representative frames; (2) a corresponding proposal segment; (3) the proposal segment after extension; (4) the per-frame score of being SoccerPenalty predicted by the CDC network; (5) the precisely predicted action instance after the refinement step using CDC.

Acknowledgments
The project was supported by Mitsubishi Electric, and also by Award No. 2015-R2-CX-K025, awarded by the National Institute of Justice, Office of Justice Programs, U.S. Department of Justice. The opinions, findings, and conclusions or recommendations expressed in this publication are those of the author(s) and do not necessarily reflect those of the Department of Justice. The Tesla K40 used for this research was donated by the NVIDIA Corporation. We thank Wei Family Private Foundation for their support for Zheng Shou, and anonymous reviewers for their valuable comments.