![]()
Detecting Image Near-Duplicate for Linking Multimedia Content
Image Near-Duplicate

We define Image Near-Duplcate (IND) as a pair of images in which one
is close to the exact duplicate of the other, but differs slightly due
to variations of capturing conditions (camera, camera parameter, view
angle, etc), acquisition times, rendering conditions, or editing operations.
Detecting IND can be used in a variety of applications, for example, linking
multimedia content, identifying copyright infringement, managing photo
albums, etc.
Example Application: Linking News Videos
Broadcast channels often report and track a news story for a few of days or months. News videos on the same event or topic often contain Near-Duplicate frames. Finding Image Near-Duplicates in News videos is therefore very useful for linking news videos from different channels and reported in different days. The following example shows four news videos reporting the same event. Although they contain shots with different visual appearances, the presence of the INDs provides a strong clue to indicate these four news videos are actually concerning about the same event. According to our study, about 10% News stories in TRECVID 2003 corpus contain Image Near-Duplicate.

| Four News video episodes reporting the same event (Click to see episodes with INDs images). The images shown here are key farmes of the episodes |
Statistical Part-based Image
Similarity
![]()
Most prior work on image similarity measure focus on global or block-based features, such as color histogram, edge descriptor, shape descriptor etc. Recent researches in computer vision have shown promising results of object recognition through part-based representations. These results indicate that the part-based representation is a promising methodology for image understanding. This project aims at developing a part-based image similarity measure for detecting Image Near-Duplicate. In our approach, each image is represented as an Attributed Relational Graph (ARG) (See figure below). IND detection is achieved by computing the similarity of two ARGs.
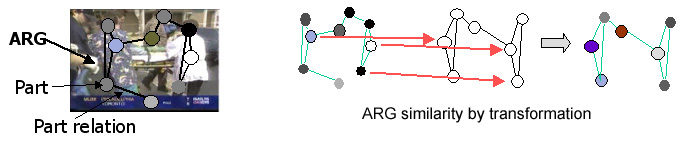
We developed a new statistical similarity measure for computing the similarity of two ARGs. The methodology is realized by first designing a transformation between two ARGs. The ARG similarity then is defined as the likelihood ratio of whether or not one ARG is trasformed from the other. This statistical similarity measure not only offers a principled definition of ARG similarity, but also provides a way for learning ARG similarity in an unsupervised manner (i.e. we don not need to annotate the vertex correspondence of two ARGs). Our experiments show that the part-based similarity measure is far more accurate than the previous global or block-based visual features for detecting IND.
Publication
![]()
Dong-Qing Zhang and Shih-Fu Chang, "Detecting Image Near-Duplicate by Stochastic Attributed Relational Graph Matching with Learning", ACM conference of Multimedia 2004, (ACM MM). (PDF)
Dong-Qing Zhang and Shih-Fu Chang, "Stochastic Attributed Relational Graph Matching for Image Near-Duplicate Detection", Columbia University ADVENT Technical Report #206-2004-6 Columbia University, October 2004. (PDF)
Data Set Download
We have build up a data set for evaluating the IND detection, from the TREC-VID 2003 corpus. The data set consists of 150 IND pairs (300 images) and 300 non-IND images. Due to copyright issues, we cannot directly provide the image files. However, if you have TREC VID 2003 corpus, you can extract these images from TREC-VID 2003 corpus using the following two files: IND data set file and non-IND data set file. The ID of the images in these two files has the naming convention as "videofile_frameno", where "videofile" is the name of the video, frameno is the frame number of the frame in the video (start from 0). You can also browse our data set using the following two links (images are of smaller size): Duplicate Set, Nonduplicate Set.
Software and Source Code Download
Our IND detection software and source code can be downloaded from here. The software contains three components: Parts and feature extraction, IND learning and IND detection, and was written in MATLAB and C++. Users can compile the software under Windows or Linux. The evaluation data sets along with the extracted ARG or Bag-of-Parts representations are also included in the download package..
Related Prior Work
Please see our previous work on Near-Duplicate detection in consumer photos.