Columbia Consumer Video (CCV) Database
--- A Benchmark for Consumer Video Analysis
Summary
Recognizing visual content in unconstrained videos has become a very important problem
for many applications. Existing corpora for video analysis lack scale and/or content
diversity, and thus limited the needed progress in this critical area. To stimulate innovative research
on this challenging issue,
we constructed a new database called CCV, containing 9,317 YouTube videos over 20
semantic categories. The database was collected with extra care
to ensure relevance to consumer's interest and originality of video content without
post-editing. Such videos typically have very little textual annotation and thus can
benefit from the development of automatic content analysis techniques.
We used Amazon MTurk platform to perform manual annotation,
and implemented automatic classifiers using state-of-the-art
multi-modal approach that achieved top performance in 2010 TRECVID multimedia event detection task.
These automatic classifiers produce a decent baseline performance. We release unique
YouTube IDs of CCV videos, ground-truth annotations, a standard training and testing partition, and
three audio/visual feature representations to the community for research usage.
CCV Snapshot
CCV Citation
Yu-Gang Jiang, Guangnan Ye, Shih-Fu Chang, Daniel Ellis, Alexander C. Loui, Consumer Video Understanding: A Benchmark Database and An Evaluation of Human and Machine Performance, ACM International Conference on Multimedia Retrieval (ICMR), Trento, Italy, April 2011.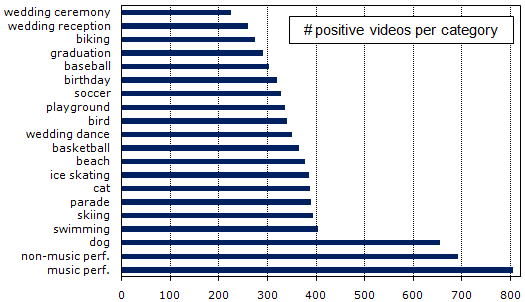
Download
To download the CCV database, please fill out the following form. We will send you download instructions via email immediately. People who request and use this database must agree that 1) the use of the data is restricted to research purpose only, and that 2) the authors of the above ICMR paper and their affiliated organizations make no warranties regarding this database, such as (not limited to) non-infringement.
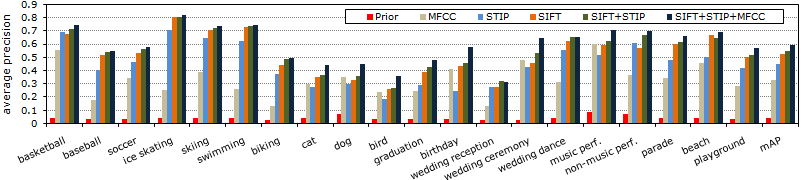
Baseline Evaluation
We implemented a baseline system using three popular audio/visual features, namely SIFT, STIP, and MFCC. For all the three features, videos are represented by bag-of-word framework. Classification results are given in the following figure, where the performance is measured by average precision. The combination of multiple features is done by averaging separate SVM prediction scores. For more details of our baseline classifier design, please refer to the CCV paper. All the three features are included in the released package.
More results: Per-category precision-recall curves and example frames.