Computational Model for Aesthetic Assessment of Videos
Abstract
In this paper we propose a novel aesthetic model emphasizing psychovisual
statistics extracted from multiple levels in contrast to earlier
approaches that rely only on descriptors suited for image recognition
or based on photographic principles. At the lowest level,
we determine dark-channel, sharpness and eye-sensitivity statistics
over rectangular cells within a frame. At the next level, we extract
Sentibank features (1,200 pre-trained visual classifiers) on a given
frame, that invoke specific sentiments such as “colorful clouds”,
“smiling face” etc. and collect the classifier responses as framelevel
statistics. At the topmost level, we extract trajectories from
video shots. Using viewer’s fixation priors, the trajectories are labeled
as foreground, and background/camera on which statistics are
computed. Additionally, spatio-temporal local binary patterns are
computed that capture texture variations in a given shot. Classifiers
are trained on individual feature representations independently. On
thorough evaluation of 9 different types of features, we select the
best features from each level – dark channel, affect and camera motion
statistics. Next, corresponding classifier scores are integrated
in a sophisticated low-rank fusion framework to improve the final
prediction scores. Our approach demonstrates strong correlation
with human prediction on 1,000 broadcast quality videos released
by NHK as an aesthetic evaluation dataset.
Method Summary and Results
Automatic aesthetic ranking of images or videos is an extremely challenging
problem as it is very difficult to quantify beauty. That said, computational
video aesthetics has received significant attention in recent years. With the
deluge of multimedia sharing websites, research in this direction is expected
to gain more impetus in future, apart from the obvious intellectual challenge
in scientific formulation of a concept as abstract as beauty.
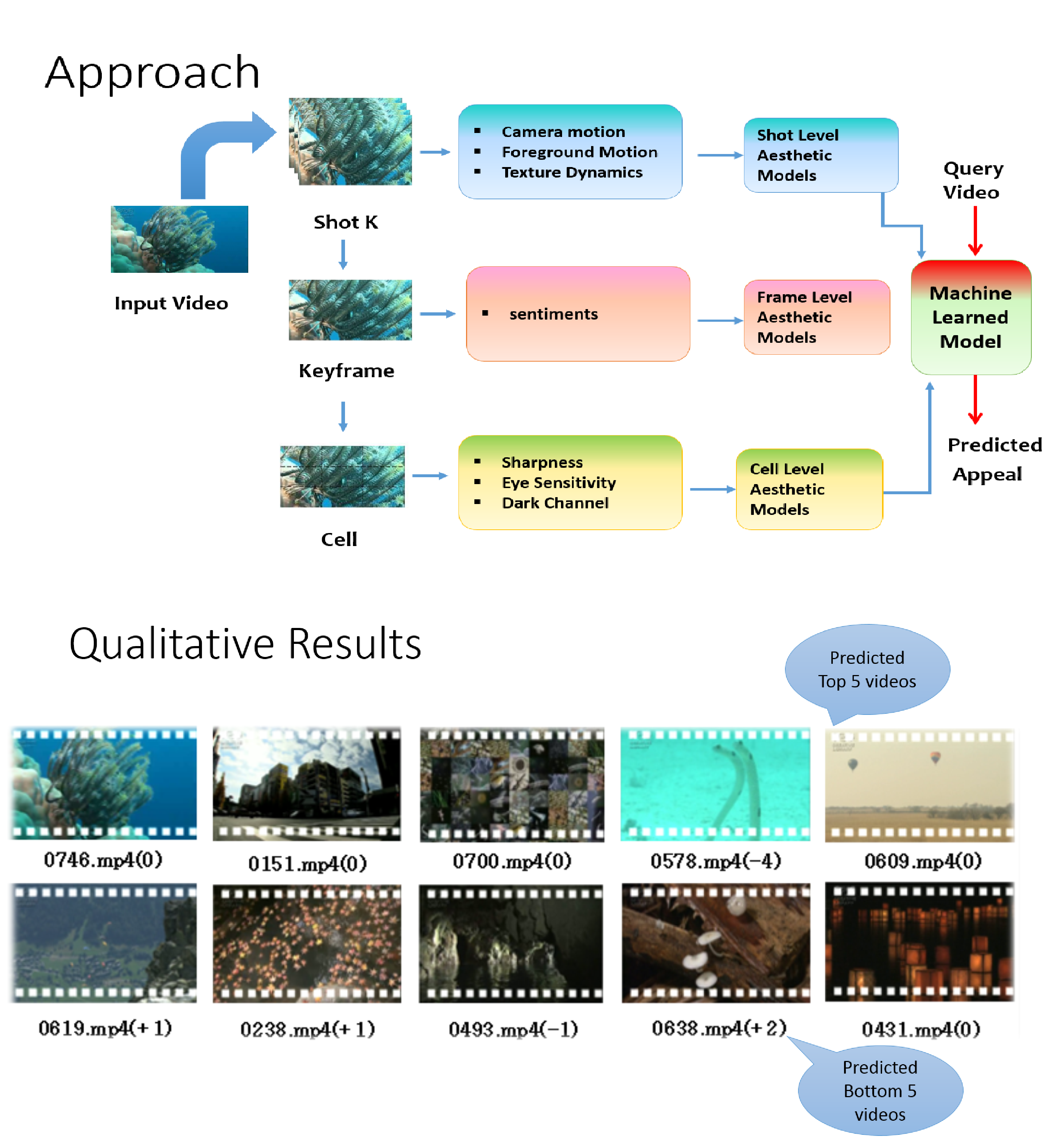
We propose a hierarchical framework encapsulating aesthetics at multiple levels which can be used independently or jointly to model beauty in videos. Our contributions are: (1) We extract motion statistics that latently encode cinematographic principles, specific to foreground and background or camera, superior to approaches previously proposed, (2) We introduce application of human sentiment classifiers on image frames that capture vital affective cues which are directly correlated with visual aesthetics and are semantically interpretable, (3) We employ a relatively small set of low-level psychovisual features in contrast to earlier approaches and encode them efficiently into descriptors that capture spatial variations within video frames, and finally, (4) We exploit a more sophisticated fusion scheme that shows consistent improvement in overall ranking when compared to earlier methods.
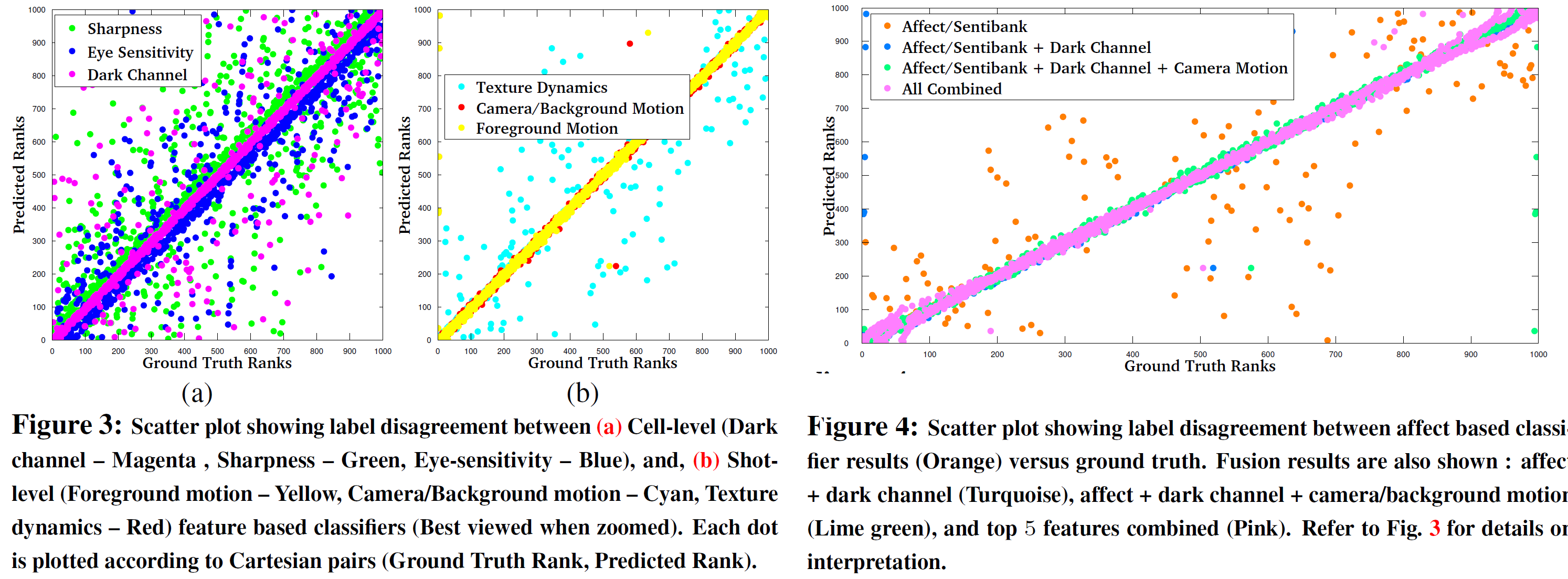
Selecting an optimal algorithm for fusing knowledge from individual models, boosts overall performance. More detailed analysis of fusion is provided in Fig. 4. It is evident that models built on shot-level features: camera/background motion perform well with smaller vocabulary sizes, in comparison to the ones that are trained using texture descriptors and sentibank features - which perform better with larger vocabularies.
We also observe that, shot level features : camera/background and foreground motion statistics outperform all other features in most cases. It is also interesting to note that frame-level sentibank features also perform equally well. Among cell-level features, dark channel based statistics demonstrate best performance. This is further supported by the scatter plot in Fig. 3(a). Ideally, the dots in the figures are expected to be along the line that connects (1; 1) to (1000; 1000), indicating no discordance between ground truth rank and predicted rank. We notice that magenta dots, corresponding to dark channel features are more aligned to the line, than those belonging to sharpness or eye-sensitivity.
However, in case of shot level features, we observe a larger degree of agreement between the ground truth and the prediction, in comparison to the cell-level features. This is reflected in Fig. 3(b). Finally, in Fig. 4, we provide some results using classifiers trained on frame-level affect based features (Orange). Except for a few ( less than 5%), we see strong label agreement between ground truth and prediction - similar to the shot-level features. This encourages us to fuse the individual classifier outcomes in 3 different settings. These results are also shown in Fig. 4. Fusion of classifiers trained on affect and dark channel based features are indicated in Turquoise. These results are further improved after adding classifiers trained on camera/background motion (Lime green). Ultimately fusion results from classifiers trained on top 5 features is shown in Pink. We notice strong level of concordance in this setting.
Code/Data
Relevant Publications
We propose a hierarchical framework encapsulating aesthetics at multiple levels which can be used independently or jointly to model beauty in videos. Our contributions are: (1) We extract motion statistics that latently encode cinematographic principles, specific to foreground and background or camera, superior to approaches previously proposed, (2) We introduce application of human sentiment classifiers on image frames that capture vital affective cues which are directly correlated with visual aesthetics and are semantically interpretable, (3) We employ a relatively small set of low-level psychovisual features in contrast to earlier approaches and encode them efficiently into descriptors that capture spatial variations within video frames, and finally, (4) We exploit a more sophisticated fusion scheme that shows consistent improvement in overall ranking when compared to earlier methods.
Selecting an optimal algorithm for fusing knowledge from individual models, boosts overall performance. More detailed analysis of fusion is provided in Fig. 4. It is evident that models built on shot-level features: camera/background motion perform well with smaller vocabulary sizes, in comparison to the ones that are trained using texture descriptors and sentibank features - which perform better with larger vocabularies.
We also observe that, shot level features : camera/background and foreground motion statistics outperform all other features in most cases. It is also interesting to note that frame-level sentibank features also perform equally well. Among cell-level features, dark channel based statistics demonstrate best performance. This is further supported by the scatter plot in Fig. 3(a). Ideally, the dots in the figures are expected to be along the line that connects (1; 1) to (1000; 1000), indicating no discordance between ground truth rank and predicted rank. We notice that magenta dots, corresponding to dark channel features are more aligned to the line, than those belonging to sharpness or eye-sensitivity.
However, in case of shot level features, we observe a larger degree of agreement between the ground truth and the prediction, in comparison to the cell-level features. This is reflected in Fig. 3(b). Finally, in Fig. 4, we provide some results using classifiers trained on frame-level affect based features (Orange). Except for a few ( less than 5%), we see strong label agreement between ground truth and prediction - similar to the shot-level features. This encourages us to fuse the individual classifier outcomes in 3 different settings. These results are also shown in Fig. 4. Fusion of classifiers trained on affect and dark channel based features are indicated in Turquoise. These results are further improved after adding classifiers trained on camera/background motion (Lime green). Ultimately fusion results from classifiers trained on top 5 features is shown in Pink. We notice strong level of concordance in this setting.
Code/Data
MATLAB code for computing aesthetic representation of a frame is available here. Dataset is available from NHK
upon request.
Relevant Publications
- Subhabrata Bhattacharya, Behnaz Nojavanasgheri, Tao Chen, Dong Liu, Shih-Fu Chang, Mubarak Shah, "Towards a Comprehensive Computational Model for Aesthetic Assessment of Videos", In Proc. of ACM International Conference on Multimedia (MM), Barcelona, ES, pp. 361-364, 2013.[ACM MM 2013 Grand Challenge 2nd Prize]