5. Part 4: Evaluate various n-gram models on the task of N-best list rescoring
In this section, we use the code you wrote in the earlier parts of this lab to build various language models on the full original Switchboard training set (about 3 million words). We will investigate how n-gram order (i.e., the value of n) and smoothing affect WER's using the paradigm of N-best list rescoring.
In ASR, it is sometimes convenient to do recognition in a two-pass process. In the first pass, we may use a relatively small LM (to simplify the decoding process) and for each utterance output the N best-scoring hypotheses, where N is typically around 100 or larger. Then, we can use a more complex LM to replace the LM scores for these hypotheses (retaining the acoustic scores) to compute a new best-scoring hypothesis for each utterance. To see an example N-best list, see the file ~stanchen/e6884/lab3/nbest.txt. The correct transcript for this utterance is DARN; each line contains a hypothesis word sequence and an acoustic logprob at the end (i.e., log P(x | w)).
To give a little more detail, recall the fundamental equation of speech recognition
where x is the acoustic feature vector, w is a word sequence, and alpha is the language model weight. In N-best list rescoring, for each hypotheses w in an N-best list, we compute log P(w) for our new language model and combine it with the acoustic model score log P(x | w) computed earlier. Then, we compute the above argmax over the hypotheses in the N-best list to produce a new best-scoring hypothesis.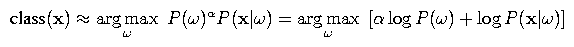
For this part of the lab, we have created 100-best lists for each of 100 utterances of a Switchboard test set, and we will calculate the WER over these utterances when rescoring using various language models. Because the LM used in creating the 100-best lists prevents really bad hypotheses (from an LM perspective) from making it onto the lists, WER differences between good and bad LM's will be muted when doing N-best list rescoring as compared to when using the LM's directly in one-pass decoding. However, N-best list rescoring is very easy and cheap to do so we use it here.
First, let us see how WER compares between unigram, bigram, and trigram models. Run the following scripts:
lab3p4.1.sh lab3p4.2.sh lab3p4.3.sh |
Now, let us see how smoothing affects WER. Run the following scripts:
lab3p4.mle.sh lab3p4.delta.sh lab3p4.wb.sh |
Finally, let us see how training data size affects WER (with Witten-Bell trigram models). Instead of using the full Switchboard corpus as the LM training set, we use subsets of different sizes. Run the following scripts:
lab3p4.2000.sh lab3p4.20000.sh lab3p4.200000.sh |