


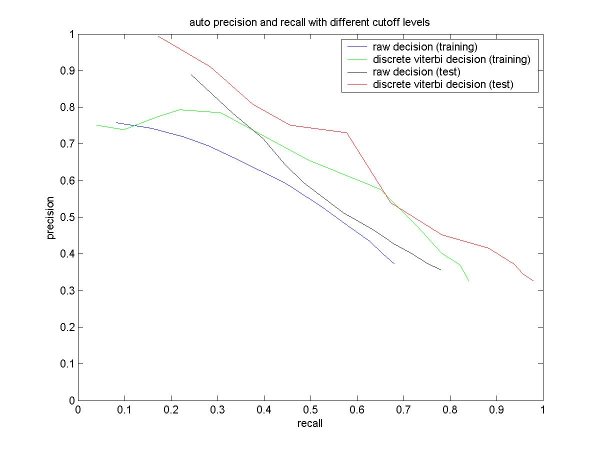
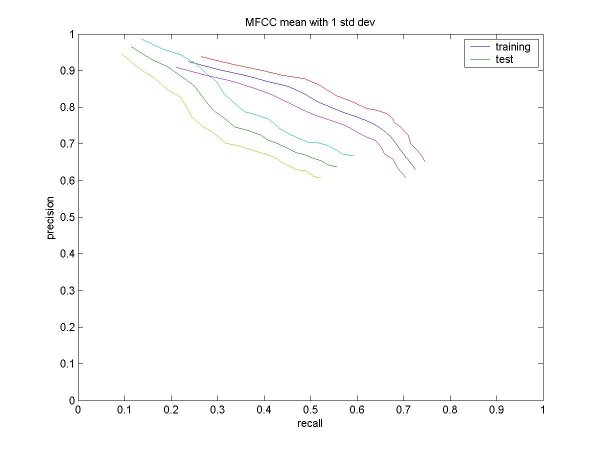
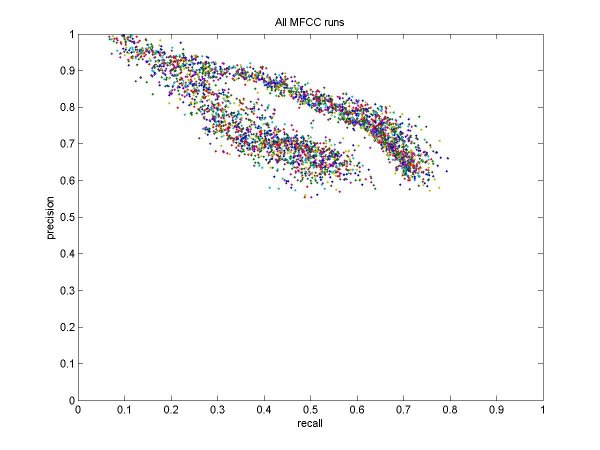
| % solo frames classified as solo: | 55 |
| % non-solo frames classified as non-solo: | 83 |
| % solo frames classified as solo: | 66 |
| % non-solo frames classified as non-solo: | 84 |
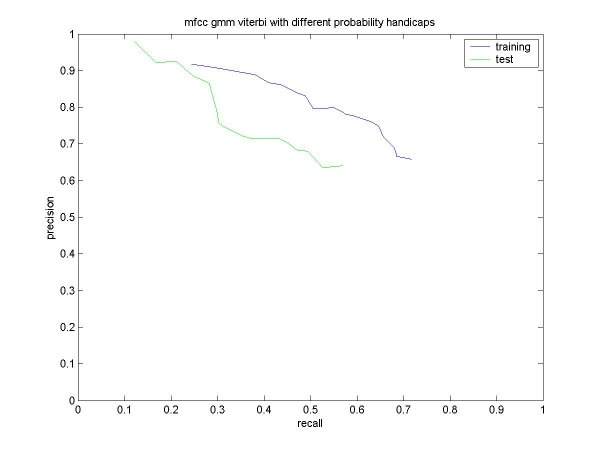
| % solo frames classified as solo: | 63 |
| % non-solo frames classified as non-solo: | 69 |
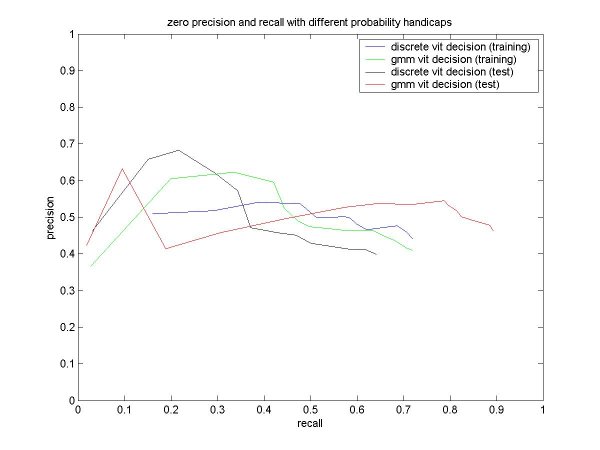
| % solo frames classified as solo: | 72 |
| % non-solo frames classified as non-solo: | 63 |

Christine Smit
