![]()
Visual Apprentice

Summary

We develop a novel interactive system for learning visual object detectors, in which models are defined by a user according to his interests via a multiple-level object definition hierarchy. The system facilitates cooperation between user and system, in which the computer performs automatic image region segmentation while the user manually labels and maps segmented regions to various nodes in the object definition hierarchy. As the user provides examples from images or video, Visual Object Detectors are constructed automatically using a variety of machine learning techniques. Optimal classifiers and features are learned for each node in the hierarchy.
Given a new test image/video, automatic region segmentation is applied and the regions are filtered by the classifiers at the terminal nodes and the final scene-level decision is made by fusing the decisions bottom up following the relationships defined in the hierarchy.
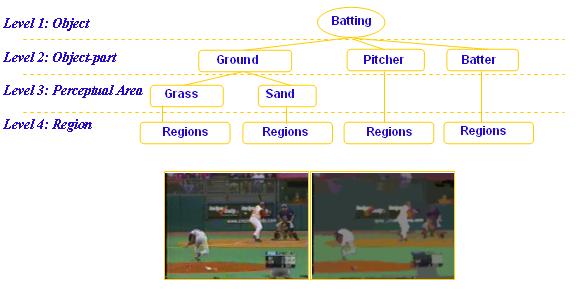
The above v visual detectors have been tested in detecting handshake images from news sources, and shots of pitching views in baseball videos. The diagram below shows the multi-level hierarchy used to define the pitching scene in baseball. The lower right image shows the automatically segmented regions, each of which can be tagged by the user to connect to a node in the scene definition hierarchy.
People
Alex
Jaimes and Prof. Shih-Fu
Chang
Publication
A. Jaimes and S.-F. Chang,
Learning
Structured Visual Detectors From User Input at Multiple Levels, Invited
Paper, International Journal of Image and Graphics (IJIG), Special Issue
on Image and Video Databases, August 2001.
(PS.GZ/PDF)
A. Jaimes and S.-F. Chang, Concepts
and Techniques for Indexing Visual Semantics, Book Chapter in "Image
Databases, Search and Retrieval of Digital Imagery", edited by V. Castelli
and L. Bergman.
(PS.GZ/PDF)
A. Jaimes and S.-F. Chang,
Model-Based
Classification of Visual Information for Content-Based Retrieval,
Storage and Retrieval for Image and Video Databases VII, 1999, IS&T/SPIE,
San Jose, CA, January 1999.
(PS.GZ/PDF)
A. Jaimes and S.-F. Chang, Automatic
Selection of Visual Features and Classifiers, Storage and Retrieval
for Media Databases 2000, IS&T/SPIE, San Jose, CA, January 2000.
(PS.GZ/PDF)
A. Jaimes and S.-F. Chang, Integrating
Multiple Classifiers in Visual Object Detectors Learned from User Input,
invited Paper, Session on Image and Video Databases, 4th Asian Conference
on Computer Vision (ACCV 2000), Taipei, Taiwan, January 8-11, 2000.
(PS.GZ/PDF)
A. Jaimes, Conceptual
Structures and Computational Methods for Indexing and Organization of
Visual Information, Doctoral Dissertation, Graduate School of Arts
and Sciences, Columbia University, 2003 (Advisor: Prof. Chang).
(PS.GZ/PDF)
Download
For problems
or questions regarding this web site contact The
Web Master.
Last updated:
June 12, 2002.