Comparison of spectrogram and waveform
Lexing Xie <[email protected]>
03/06/2001 20:10
reading practical problem xlx audio EE6820 Home
Antti Eronen, Anssi Klapuri, "Musical instrument recognition using cepstral coefficients and temporal features", IEEE ICASSP, June 2000
Using a wide set of features to classify musical instruments in a hierarchy.
Based on prior research on timber, they chose 2 sets more than 20 different features,
each set corresponds to the spectral and temporal dimension of the timber. This
is a progress compared to prior works by Martin, Kaminsky et al, where only 1
set is used. Then Gaussian or K-NN classifiers are used in a hierarchical
decision tree, where the performance of Guassian is better at higher levels and that of K-NN is better at lower levels. Quite accurate results are achieved.
Questions and random thoughts:
1. What is the training set? Parallel to the validation set?
2. Where does the "knowledge of the best feature in a given node" come from? Empirical, heuristic or something?
3. If the dataset is expanded, does this kind of classifier need to have some major modification?
4. Harp and percussion instruments are missing in the hierarchy. The former can be in the pizzicato family with piano; and the latter may be trickier, because they're not in a consistent domain with regard to audio features, e.g. they can have both tonal and non-tonal sounds, and the non-tonal sounds do have some other kind of structure we may use, as mentioned in the book.
5. Another thing may be interesting to classify is human voice. As
shown in the practical for this week, vocal music also exhibits tonal structures, and we may be able to use vocal models and features to assist our decision.
6. This is only the western musical instrument tree. Can we try to do this: have an unknown instrument (e.g. a random flute from Latin America), and the classifier would know which node (sustained-->reed) it belongs to, and give the most close kin in a knowledge base.
7. The validation set used here is only solo tones, what if we want to use melodies or identify the solo instrument from a sonata? Separating instrument from a symphony may seem too ambitious, but for example, is classifying string trios from quartet a worthy thing to do? (or say, count the number of instruments in that piece)
Also at reading page week7
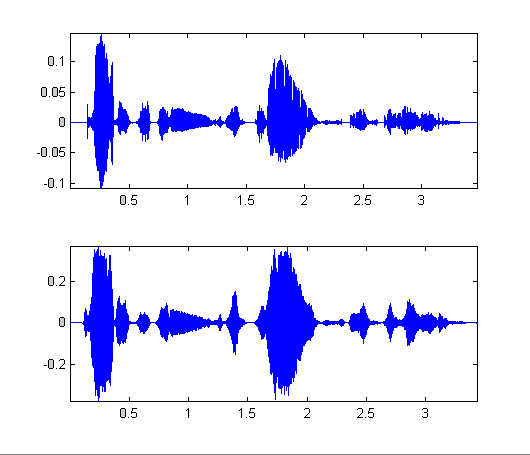
Original speech![]() ,
synthesis
,
synthesis ![]()
Comparison of spectrogram and waveform
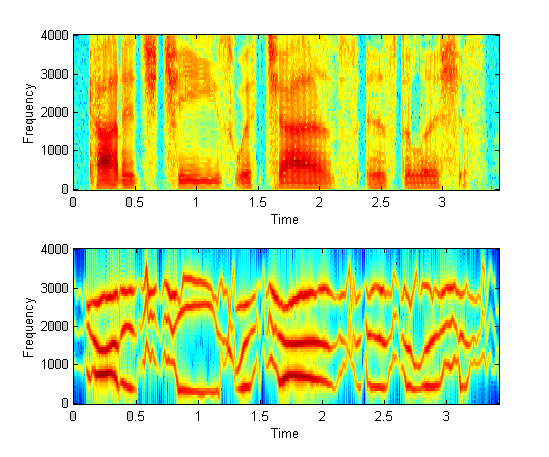 |
 |
Modified source code: hw7.m , Usage: hw7('wavefilename',
play_original (optional, default FALSE), #of_sinusoids_to_keep (optional,
default 3))
Thanks for debugging!
One reason why sinusoid synthesis doesn't work well is it seems not quite good at the un-voiced part as well as the noise-like portion of the signal.
| (a) It doesn't make
much difference to include the 4th LPC frequency, as we can see from the
graph that the 4th frequency is usually not continuous. But it does
deteriorate when we only use even fewer sinusoids. The 3 formants
correspond to 3 physical pole settings in the vocal tract?
Compare: |
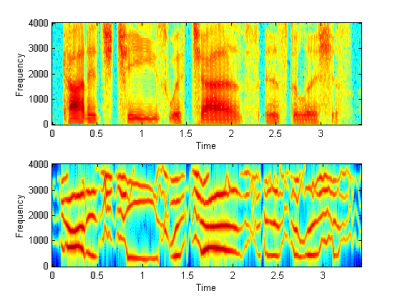 |
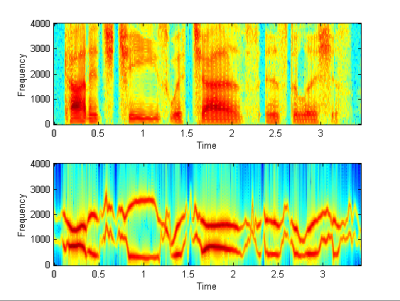 |
(b) If we don't know the content of the speech beforehand, it is hard to
make out what most of the sinwaves are "saying", actually it is the
human comprehension that makes up the gap and let the sinusoids "sounds
like" speech.
First, listen to the sinusoids: ![]() .
.
And here is what she is
actually saying: ![]() (which is the output of AT&T TTS online demo, quite good!)
(which is the output of AT&T TTS online demo, quite good!)
(c) What if we apply this to tonal sound coming from the
vocal tract (human singing)?
Here are two examples.
The subjective quality is worse
than speech synthesis, LPC appears bad at estimating relatively static tonal
sounds?
This may because the harmonics are
too close to each other that they are actually mixed up in LPC frequency (see
the 1st graph), or other reasons?
The second is far worse than
the first one, because it has stronger background non-speech audio (piano).
| Synthesis 1: |
Synthesis 2: |
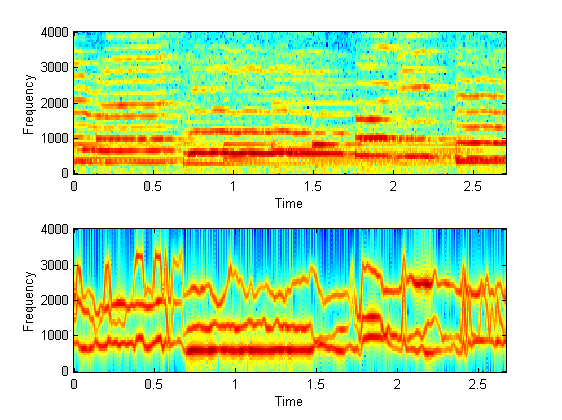 |
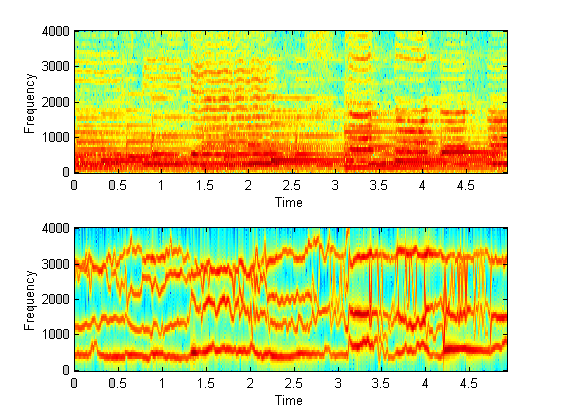 |
The test is trying to tract the probability that a "machine
listener" can properly identify phonemes and syllables, an assumption
of which is that machine cannot understand speech, hence the judgments it makes
only depends on the low level computable features. For these results to be
comparable of those labeled by human listeners, we must rule out the complex
factors that human listener can use acoustic context, semantic or syntactic information
to infer the syllabus. That is to say, make the CVC structure "equally
meaningless" to both machine and human listeners.
I think this is an important assumption we must make in many other works related
to recognition and classification using low-level information. For example, to
use a dataset in a language we do not understand to evaluate prosodic cues or to
do things like audio scene segmentation.
The cepstrum of a pair of conjugate poles inside unit circle would be a peak somewhere, and so the cascade of multiple poles would be multiple poles at different locations (summed up) the cepstrum domain. They can be seperated if they're not too close to each other.
LPC is an all-pole model (cascade of band-pass filters), but notch filter actually contains 2 or more zeros. So the LPC residues will end up with larger magnitude, and the efficiency will suffer. If we reconstruct the signal without using the residue signal (use noise excitation etc), then the quality of reconstruction will deteriorate.
This may depend on the source-filter model used in synthesis, and depend on
the type of error (mass error in time, or just sporadic ones).
In LPC case:
Mass vocal tract filter error will make the phoneme sounds different, thus affect the
intelligibility.
Source error will change the properties of phoneme, yet usually the phonemes are
still intelligible. For example, using pure-noise excitation instead of
residue-excitation, we can still make out the speech content in the deteriorated
speech, because the spectrum is limited approximately to the right shape. But if
the wrong excitation we applied is just in the stop-band, result would be even
worse.
What if we use cepstrum model. or models with both zeros and poles ... it
doesn't seem to make much difference?