Temporal Dynamics between Concepts in Complex Events
Abstract
While approaches based on bags of features excel at lowlevel
action classification, they are ill-suited for recognizing
complex events in video, where concept-based temporal
representations currently dominate. This paper proposes
a novel representation that captures the temporal dynamics
of windowed mid-level concept detectors in order to
improve complex event recognition. We first express each
video as an ordered vector time series, where each time
step consists of the vector formed from the concatenated
confidences of the pre-trained concept detectors. We hypothesize
that the dynamics of time series for different instances
from the same event class, as captured by simple
linear dynamical system (LDS) models, are likely to be similar
even if the instances differ in terms of low-level visual
features. We propose a two-part representation composed
of fusing: (1) a singular value decomposition of block Hankel
matrices (SSID-S) and (2) a harmonic signature (HS)
computed from the corresponding eigen-dynamics matrix.
The proposed method offers several benefits over alternate
approaches: our approach is straightforward to implement,
directly employs existing concept detectors and can
be plugged into linear classification frameworks. Results
on standard datasets such as NIST’s TRECVID Multimedia
Event Detection task demonstrate the improved accuracy of
the proposed method.
Method Summary and Results
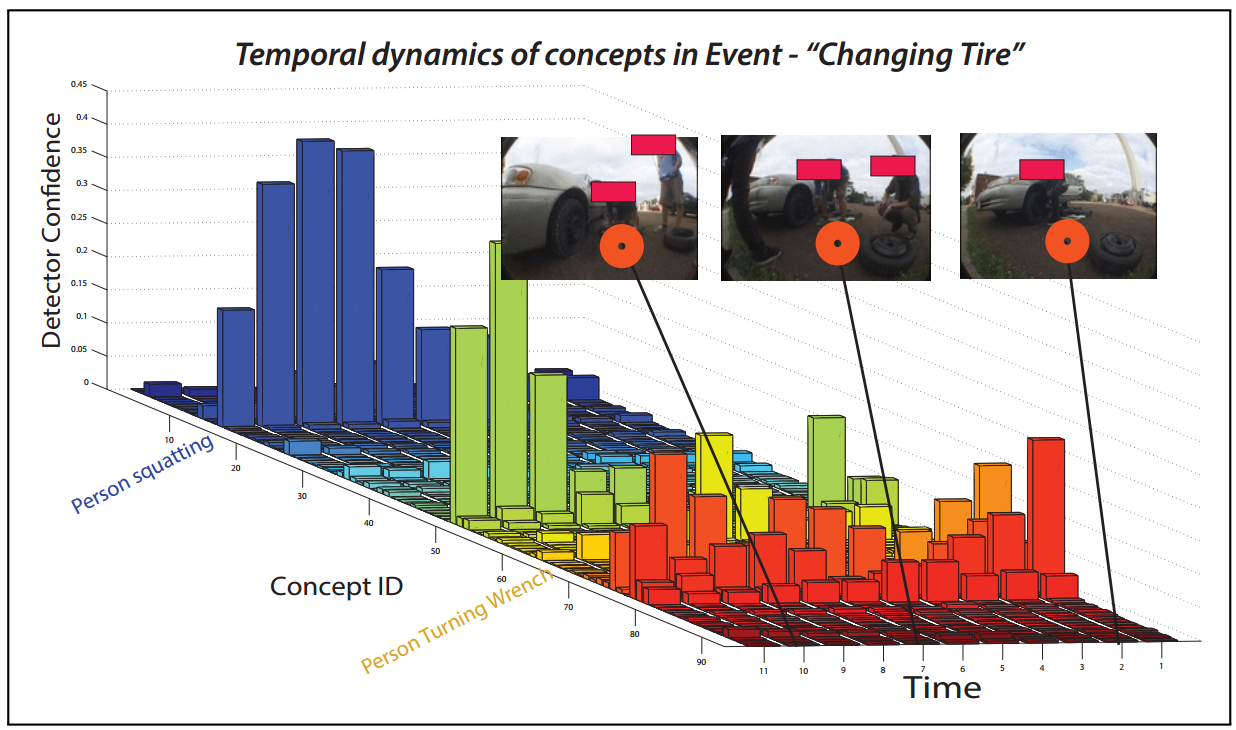
In our approach, a video is decomposed into a sequence of overlapping
fixed-length temporal clips, on which lowlevel feature detectors are applied.
Each clip is then represented as a histogram (bag-of-visual-words) which is
used as a clip level feature and tested against a set of pre-trained action
concept detectors. Real-valued confidence scores, pertaining to the presence
of each concept are recorded for each clip, converting the video into a vector
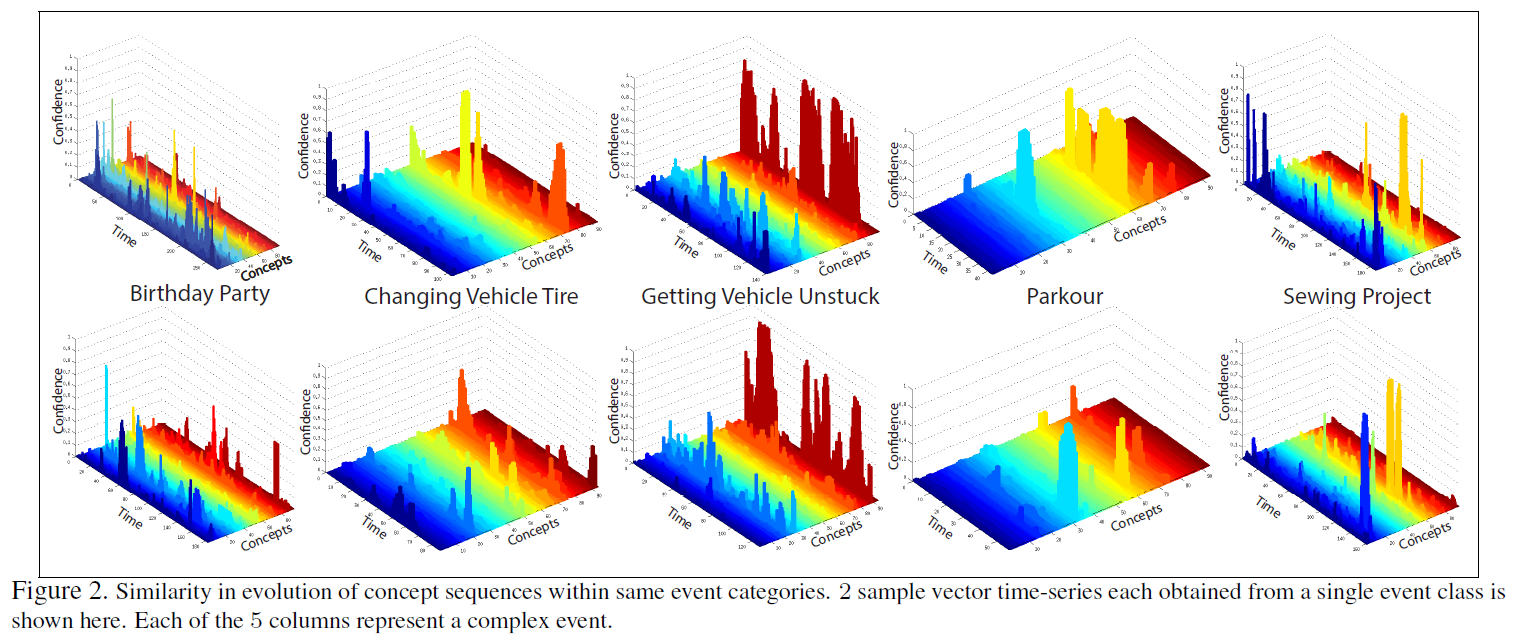
time series. Fig. 2 illustrates sample vector time-series from different
event classes through time. We model each such vector time series using a
single linear dynamical system, whose characteristic properties are estimated
using two different ways. The first technique (termed SSID-S) is indirect and
involves computing principal projections on the Eigen decomposition of block
Hankel Matrix constructed from the vector time series. The second one (termed
H-S) involves directly estimating harmonic signature parameters of the LDS
using a method inspired by PLiF. The representations generated by SSID-S and
H-S are individually compact, discriminative and complementary, enabling us to
perform late fusion in order to achieve better accuracies in complex event
recognition.
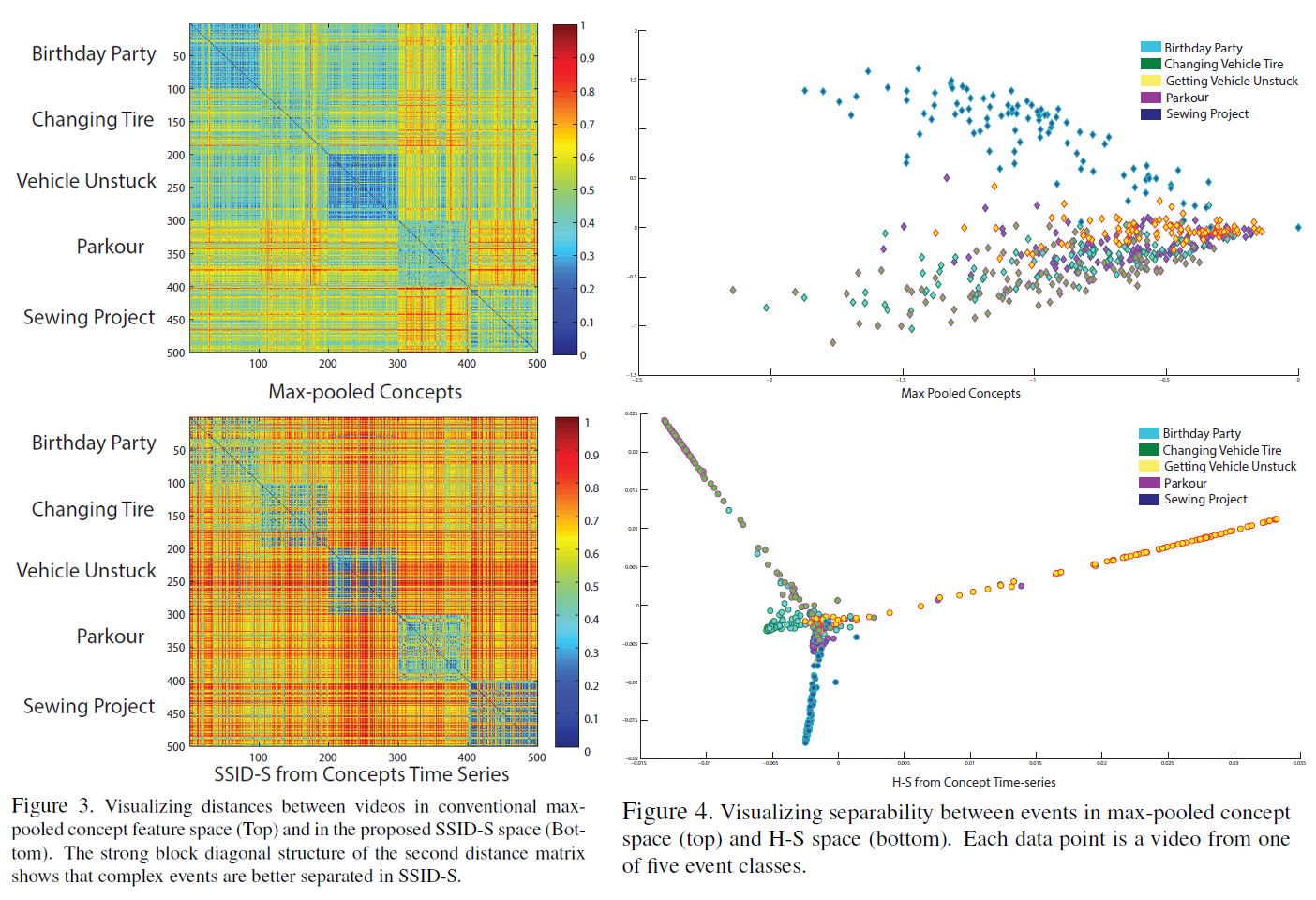
Fig. 3 shows an intuitive visualization of SSID-S’s benefits over the mid-level concept feature space, computed using 100 videos from each of 5 event classes. Fig. 3(left) shows inter-video Euclidean distance between max-pooled concept detection scores, with each concept score maxpooled temporally to generate a C-dimensional vector per video. While there is some block structure, we see significant confusion between classes (e.g., Birthday Party vs. Vehicle Unstuck). Fig. 3(right) shows the Euclidean distance matrix between videos represented using the proposed SSID signature. The latter is much cleaner, showing improved separability of event classes, even using a simple distance metric.
Fig. 4 shows an intuitive visualization of H-S’s benefits over the mid-level concept feature space, computed using the same 100 videos from each of five event classes as seen in Fig. 3. Dots (corresponding to videos) in the max-pooled concept feature space are C-dimensional, whereas those in H-S space are Cd dimensional. The scatter plot is generated by projecting each point in the feature spaces to two dimensions using PCA. We observe that the videos are much more separable in H-S space as compared to the max-pooled concept feature space: four of the five complex event classes are visually separable, even in the 2D visualization.
Fig. 3 shows an intuitive visualization of SSID-S’s benefits over the mid-level concept feature space, computed using 100 videos from each of 5 event classes. Fig. 3(left) shows inter-video Euclidean distance between max-pooled concept detection scores, with each concept score maxpooled temporally to generate a C-dimensional vector per video. While there is some block structure, we see significant confusion between classes (e.g., Birthday Party vs. Vehicle Unstuck). Fig. 3(right) shows the Euclidean distance matrix between videos represented using the proposed SSID signature. The latter is much cleaner, showing improved separability of event classes, even using a simple distance metric.
Fig. 4 shows an intuitive visualization of H-S’s benefits over the mid-level concept feature space, computed using the same 100 videos from each of five event classes as seen in Fig. 3. Dots (corresponding to videos) in the max-pooled concept feature space are C-dimensional, whereas those in H-S space are Cd dimensional. The scatter plot is generated by projecting each point in the feature spaces to two dimensions using PCA. We observe that the videos are much more separable in H-S space as compared to the max-pooled concept feature space: four of the five complex event classes are visually separable, even in the 2D visualization.
Code/Data
Software for descriptor computation from vector-time series of spatio-temporal
concepts is available here. The list of
detected concepts, their annotation in respective videos and relevant concept
detection scores are available here.
Presentation slides are available for download. The entire talk is also shared freely, courtesy Techtalks.tv.
Presentation slides are available for download. The entire talk is also shared freely, courtesy Techtalks.tv.
Relevant Publications
- Subhabrata Bhattacharya, Mahdi Kalayeh, Rahul Sukthankar, Mubarak Shah, "Recognition of Complex Events: Exploiting Temporal Dynamics between Underlying Concepts", In Proc. of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, USA, pp. pp-pp, 2014. [Oral, Acceptance Rate: 5.75%]