Projects
Model Based Source Separation
My PhD research involves the use of statistical models for the separation of complex audio signals (e.g. separating out a single voice in a cocktail party). I am mainly interested in situations where there are more sources of interest than there are observed channels (i.e. I'm no expert on ICA) and thus the problem is underdetermined.
Clearly this is a very difficult problem. Luckily, most audio signals are quite redundant so it is possible to use the parts of the mixed signal that are not obscured by the interference to infer what the target (e.g. a particular speaker) signal might have been. This is done using prior knowledge of the statistics of the target signals and the magic of machine learning.
You can find some audio examples here.
MEAPsoft
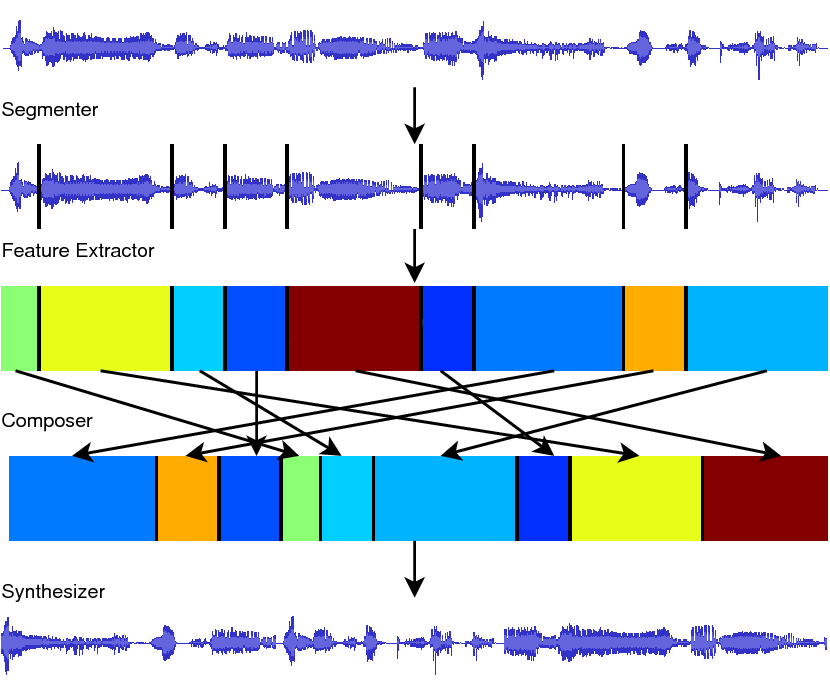
MEAPsoft is a collection of tools for cutting audio up into small chunks and rearranging them. It also contains a tool for visualizing common audio features. While we have yet to find a practical use for this, it does produce some fun sounds.
For a quick introduction to the whys and hows of MEAPsoft, see the slides from the talk I gave at the January 2007 dorkbot-nyc meeting (sound files are here). You can find more information and download the latest release at the MEAPsoft website.