Dan Ellis: Research
Projects:
Meeting Segmenter
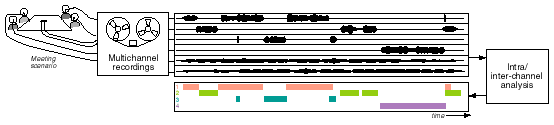
The Meeting Recorder
project is an ongoing effort at my previous lab, ICSI, to record conventional
meetings and use speech and audio processing to extract useful information
from the recordings. There are lots of aspects to this project, but right
now we are collecting a fairly substation amount of information and we need
tools to help us process and organize this data.
The basic recordings (as described in the data collection
pages at ICSI) have up to 16 channels, including head-mounted mics for
each participant and several ambient mics located, e.g., on the tabletop.
We will eventually have a number of these meetings manually transcribed,
but this is a slow process. It would be helpful to have some kind of pre-processing
to identify all the spoken phrases according to the speaker; manual transcription
would then involve just 'filling in the blanks' rather than having to mark
all the boundaries.
An automatic tool that takes the recordings in one side and builds a
set of speaker-turn labels (and perhaps labels for other broad-class acoustic
events such as nonspeech noises) would be useful far beyond the transcription
stage too: It would be the first level of a tool for the automatic organization
of newly-recorded meeting data.
Here are the some initial stages for this project:
- Energy-based baseline segmenter: Write a simple, energy-threshold-based
system that converts the individual close-mic channel recordings into a
rough set of speaker turns. Although the algorithm for deciding which speaker
is active will be as simple as possible, all the ancilliary processing
(finding and reading the soundfiles, and formatting the output data) will
be a useful foundation for any subsequent programs, and thus are worth
some thought and care.
The output file format should be compatible with the transcription program
we are using, Transcriber,
and with the conventions being established for the ICSI project, as described
here by Adam Janin. Adam has already written some tools to translate
between different formats of this data.
Ideally, this stage would result in a stand-alone program (or script) which
could be run on a new recording to generate a relatively error-free set
of turn markers, which could then simply be loaded into Transcriber for
the human transcriber to fill in with the actual words and events.
- Coupling-function estimation: Based on some preliminary investigations
(reported
here), I expect problems from the energy-based turn detector arising
from microphone noise (e.g. mechanical contact with a microphone that generates
a high-energy 'blip' even though that participant may not have spoken)
and crosstalk (one participant's mic picking up a second participant's
voice at a high enough level to trick the threshold. Certainly, for the
cases of speaker overlap, simple thresholding is unlikely to be adequate.
Thus there are a range of enhancements that could be developed, based around
the idea of actually estimating the coupling between each voice and each
microphone. The set of levels across all the microphones should very robustly
indicate which single speaker is the source, or if several speakers are
talking, or if a sound is coming from a source other than one of the speakers
(mic noise or external environmental noise).
- Segmenting based on 2-channel desktop recordings: The eventual
goal of the meeting recorder project is to build a device that can usefully
segment the data even in the absence of the close-talk mic channels
e.g. based on the 2-channel recordings of the tabletop PDA mock-up. Given
the high-quality turn labels developed in the earlier stages of the project,
the next stage would be to begin investigating the use of acoustic-change-detection
(ACD) algorithms (along the lines described in [Ferreiros
& Ellis 2000] and elsewhere) to find the speaker boundaries based
on much less acoustic evidence. If we assume that the automatic processing
of the individual meetings is giving reliable ground-truth data, we will
have a sizeable quantity of training and evaluation data to work with.
- Additional cues for 2-channel segmenting: Conventional ACD works
by detecting changes in the statistical properties of broad spectral parameters
such as Mel-Frequency Cepstral Coefficients. We have the possibility of
including lots of other data sources, including pitch tracks, speech-class
related features (e.g. separately modeling the sounds that a speech recognizer
indicates are vowels, consonants, sibilants etc. to permit more accurate
models of each speaker), and also the 'spatial' information available by
considering the differences between the two channels of the recorder PDA
mockup.
- Speaker tracking and characterization: The first stage of ACD
is to find boundaries where the speaker or other acoustic conditions change.
The second stage is to cluster each of the segments so defined to indicate
which ones seem to come from the same source. A possible third stage is
then to perform some informative classification of that source, either
by directly recognizing the identity of the speaker, if models are available,
or, if there is no match for a known speaker, making generic classifications
of the unknown speaker by gender, perhaps accent, age, or some other dimensions
of voice quality.
Some other projects, potential or actual, that connect with this work
are:
- Speech recognition of the meeting data: Evaluating the success
of our standard large-vocabulary recognizer on the headmounted mic channels,
then adapting the system to work as well as possible with the desktop mic
signals.
- Multi-periodicity detection: One of the key ways to detect overlaps
between speakers could be the detection of multiple pitch tracks in the
signal. This could be based on the weft
representation I developed for computational auditory scene analysis,
but that analysis needs a much more efficient implementation if we are
to be able to apply it to large databases.
- Sound browsing and visualization: The large database of meeting
recordings is very awkward to navigate and explore at present. The transcriber
tool can at least handle files of this length, but until the transcriptions
are done, all you can look at is the waveform. We must develop better tools
for looking at the signals and associated analyses in multiple formats.
- Nonlexical/prosodic analysis: Although speaker turns are one
important high-level aspect of this data, there is plenty more information
in the speech apart from what we might hope for from a speech recognizer.
Since sociological aspects of the meeting dialog is one of the other intended
uses of the data collection, it would be valuable to look at extracting
'prosodic' features such as the significant patterns in pitch, timing and
energy that indicate a phrase boundary.
Last updated: $Date: 2000/12/11 17:17:21 $
Dan Ellis <[email protected]>