Most researchers would agree that the most important factor in the success of current speech recognition systems is their ability to learn statistical models from very large corpora of speech data. By basing speech models on literally hundreds of hours of recordings, those models can be made to accommodate a large proportion of the variability in voice, pronunciation and conditions that is encountered in real life. This kind of learning relies on three things: Having a good underlying model with parameters to be set, having an algorithm to update those parameters based on training data, and having the large collection of training data, including any required tags or labels. In the case of speech recognition systems, that generally means having the hundreds of hours manually transcribed to obtain the corresponding words.
Thinking beyond the realm of transcription systems, we are interested in developing systems that can listen to 'general audio' (i.e. the mix of real world sounds which surround us every day) and making some kind of analysis in terms of objects and sources that resemble those perceived by listeners. In comparison to work in speech recognition, work in computational auditory scene analysis (CASA) the effort to build automatic sound understanding systems is rather small-scale, and based on heuristic insights of researchers, rather than optimization of general-purpose models. If only we could think of a way to exploit large amounts of training data, that would surely lead to more successful systems.
Assuming we are interested in a relatively unconstrained acoustic domain, access to large datasets might be rather easy. For instance, we could just have a computer connected to a microphone, collecting the sound of its immediate environment. For more variety and activity, we could connect a conventional receiver of radio or TV broadcasts to a computer, to obtain a never-ceasing stream of 'real' audio. The problem with this data is that it has no associated hints of what it contains no labels so many pattern recognition algorithms cannot be used.
There are, however, a set of algorithms that attempt to learn statistical patterns in data without any example labels so-called 'unsupervised' learning such as K-means clustering, Gaussian mixture modeling, or Kohonen neural networks. These algorithms can be used to find distinct clusters within data, if any exist, and even for more continuously-distributed data, they will tend to break it down into several regions with different properties.
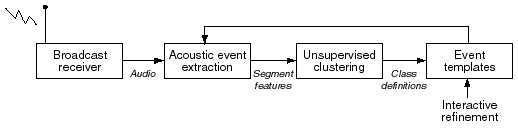
The idea behind this project is to use this kind of unsupervised learning algorithm to generate models of some broadcast acoustic signal or signals. Because the audio stream is always available, we don't have to worry about storing it when we want some more data, we simply start recording again. The goal in this project is to leverage the availability of effectively unlimited example data, and the untiring efforts of a computer that is monitoring it 24 hours a day, by devising algorithms that can continually refine and improve models by looking at very large amounts of data.
Based on the block diagram above, this project could proceed as follows:
This approach of unsupervised acquisition of sound templates is inspired by the similar work on 'acoustic context awareness' by Brian Clarkson and others at the MIT Media Lab.