Dan Ellis :
Music Content Analysis :
Practical :
A Practical Investigation of Singing Detection:
1. Data and Features
The first stage is to familiarize ourselves with the data we will be
using, and the routines to view it and convert it into features. The
training data consists of sixty 15-second pop music excerpts, recorded
at random from the radio by Scheirer and Slaney. Each one was hand-labeled
by Berenzweig to indicate where the singing (if any) begins and ends.
The WAV files containing the music are in the "music" subdirectory, named
1.wav through 60.wav. We can load a couple and listen to them in Matlab:
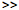 [d,sr] = wavread(fullfile('music','1.wav'));
% d is the waveform data and sr is its sampling rate (22050 samples/sec)
soundsc(d,sr);
% The first two examples have no singing
[d,sr] = wavread(fullfile('music','3.wav'));
soundsc(d,sr);
% That one has some voice
[d,sr] = wavread(fullfile('music','1.wav'));
% d is the waveform data and sr is its sampling rate (22050 samples/sec)
soundsc(d,sr);
% The first two examples have no singing
[d,sr] = wavread(fullfile('music','3.wav'));
soundsc(d,sr);
% That one has some voice
The hand-marked labels are in the "labels" subdirectory, in corresponding
files called 1.lab through 60.lab. Each line in the file has a start time
in seconds, a duration in seconds, and a label for that segment - "vox" for singing, and "mus" for just instruments. We can read the label files using
Matlab's textread:
[stt,dur,lab] = textread(fullfile('labels','3.lab'), '%f %f %s','commentstyle','shell');
% "commentstyle shell" means to ignore lines starting with a "#"
% peek at the data:
[stt(1:4),dur(1:4)]
ans =
0 3.3470
3.3470 1.0540
4.4010 2.6190
7.0200 1.2860
lab(1:4)
ans =
'vox'
'mus'
'vox'
'mus'
% so this excerpt starts with 3.35 sec of singing, then 1.05 sec without singing,
% then another 2.62 sec of singing etc. - sounds about right:
This data isn't in the most useful form for us - rather than knowing the
times that singing starts and stops, we'd like to have one big vector with
the label corresponding to, say, every 50th of a second. We can create
this with labsamplabs.m,
a function we wrote to 'sample' time
stretches defined in a label file at specific instants:
% First, convert our labels into numerical values - 0 for music, 1 for singing:
ll = zeros(length(lab),1);
ll(strmatch('vox',lab)) = 1;
% Now generate our timebase - samples every 20 ms out to 15 s
tt = 0.020:0.020:14.980;
% Sample the label definitions at those times
lsamp = labsamplabs(tt,[stt,dur],ll);
% Plot them against the timebase
subplot(311)
plot(tt,lsamp)
% Adjust the axes so we can see the plot
axis([0 15 0 1.1])
% We can compare this with the spectrogram of the music:
subplot(312)
specgram(d,512,sr)
% (it's hard to see the singing in the spectrogram in this one)
% Listen again, while looking at the plots
soundsc(d,sr)
% Labels look about right
% Play back the first segment of singing i.e from 0 to 3.347 sec:
soundsc(d((1+0*sr):(3.347*sr)),sr)
For classification, however, we're not going to use the waveform or the spectrogram, but Mel-Frequency cepstral coefficients. We can calculate them with the mfcc.m function, borrowed from Malcolm Slaney's Auditory Toolbox.
% MFCCs on a 20ms timebase:
cc = mfcc(d,sr,1/0.020);
% How big is it?
size(cc)
ans =
13 749
% First 13 cepstra (0..12) is standard;
% We expect 750 frames (15/.020), but get a bit less due to window overlap
% Take a look at the cepstra:
subplot(313)
imagesc(cc)
axis xy
% It's hard to see much in the cepstra.
% C0 is scaled differently because it's the average.
![[image of Matlab plots]](data.jpg)
Finally, we need to calculate the basic features and per-frame labels for
the entire training set. We do this with a simple for-next loop, and put the
results in two big arrays, one for features, one for labels. While we're at
it, we also calculate the deltas (slopes) and double-deltas (curvature)
of all the feature channels.
frmpersong = 749;
nsong = 60;
nftrs = 3 * 13;
ftrs = zeros(nsong*frmpersong, nftrs);
% One *row* per timeslice, Netlab expects it that way
for i = 1:60;
[d,sr]=wavread(fullfile('music',[num2str(i),'.wav']));
cc = mfcc(d,sr,1/.020);
ftrs((i-1)*frmpersong+[1:frmpersong],:) = [cc', deltas(cc)', deltas(deltas(cc,5),5)'];
end
% And the labels
labs = zeros(nsong*frmpersong, 1);
for i = 1:60;
[stt,dur,lab] = textread(fullfile('labels',[num2str(i),'.lab']), '%f %f %s','commentstyle','shell');
ll = zeros(length(lab),1);
ll(strmatch('vox',lab)) = 1;
lsamp = labsamplabs(tt,[stt,dur],ll);
labs((i-1)*frmpersong+[1:frmpersong])=lsamp;
end
% Check the sizes
size(labs)
ans =
44940 1
size(ftrs)
ans =
44940 39
% Same number of frames overall
% Validation: see if your means match mine:
mean(ftrs)
ans =
Columns 1 through 8
-14.4471 0.3160 -0.1459 -0.0065 -0.1342 -0.0503 -0.0562 -0.0376
Columns 9 through 16
-0.0295 -0.0271 -0.0001 -0.0596 -0.0061 -0.0114 -0.0151 0.0057
Columns 17 through 24
0.0040 0.0019 -0.0086 0.0056 0.0122 0.0020 0.0013 0.0013
Columns 25 through 32
-0.0006 0.0043 0.0066 0.0025 0.0044 0.0013 0.0004 0.0004
Columns 33 through 39
0.0013 0.0017 -0.0024 -0.0001 0.0015 0.0018 -0.0025
mean(labs)
ans =
0.4740
% (so 47% of frames are sung)
Assignment
Can you write a function to take an arbitrary training example and play back just the vocal portions of the waveform? For instance, you might type playsinging('5') and it would play back all the sung portions of training example 5.
Last updated: $Date: 2003/07/02 15:40:22 $
Dan Ellis <[email protected]>