|
Department of Electrical Engineering
- Columbia University
|
ELEN E4896 - Spring 2016MUSIC SIGNAL PROCESSING |
Practicals
Practicals
This page contains descriptions and instructions for weekly practical sessions.
- 2016-01-27: Plucked String
- 2016-02-03: Filtering
- 2016-02-10: Analog Synthesis
- 2016-02-17: Sinusoidal Synthesis
- 2016-02-24: LPC
- 2016-03-02: Reverb
- 2016-03-09: Pitch Tracking
- 2016-03-23: Autotune
- 2016-03-30: Beat Tracking
- 2016-04-06: Chord Recognition
- 2016-04-13: Cover Song Detection
- 2016-04-20: Fingerprinting
- 2016-04-27: Unmixing
Weds 2016-01-27: Plucked string
This week's practical looks at the Karplus-Strong plucked string simulation in Pure Data (Pd). The general pattern of these weekly practical sessions is to give you a piece of code to start with, then ask you to investigate some aspects, by using and changing the code. However, the areas to investigate are left somewhat open, in the hope that we'll each discover different things -- that we can then share.
We start with demo_karpluck.pd, my wrapper around Loomer's karpluck~.pd. In addition to the keybd.pd patch used to provide MIDI-like controls from the computer keyboard, this one also uses grapher~.pd to provide an oscilloscope-like time-domain waveform plot, and plotpowspec~.pd (based on the original by Ron Weiss) to provide a smoothed Fourier transform view. You can download all these patches in prac01.zip, then open the demo_karpluck.pd patch to run the demo.
This patch provides three main controls for the sound of the plucked string:
- the "Click width", which determines the duration of the noise burst fed into the digital waveguide to initiate the note;
- the "Decay constant", which scales the overall amplitude of the reflected pulse in each cycle; and
- the "Feedback lowpass", which is an additional attenuation applied to higher frequencies.
To get going, try playing with these three parameters to see what kinds of "real" sounds you can approximate. Can you put "physical" interpretations on these parameters?
Here are some things to try:- In addition to playing with the exposed controls, you can always modify the "innards" of the karpluck patch. For instance, the feedback lowpass is implemented with a lop~ object in the body~ subpatch of karpluck~. Can you change the order of this filter? Or its type (see lp2_butt~)? Can you explain these effects?
- Can you set a slower attack and delay for the envelope of the noise burst generated by excitation~ subpatch of karpluck~? How does that affect the sound?
- Adding a low-frequency modulation of around 4 Hz over a range +/- 500 Hz to the feedback lowpass can give a nice, subtle vibrato/tremolo effect. Can you do this? You can use [osc~ 4] to generate a 4 Hz low-frequency modulation waveform, but you'll then need [metro 20] and [snapshot~] to sample it every 20 ms and convert it into a "control" (hollow box) signal.
- One of the nice things about the waveguide physical models is that they can support different kinds of interaction. For instance, on a real string you can get harmonics by damping (touching) exactly half way along its length. You might be able to approximate something like this by having a variable, nonlinear attenuation at a fixed position in the the delay line (a linear attenuation would simply commute and not matter where you put it). Can you implement something like this?
- The string model is the simplest waveguide model. Instruments like clarinet and trumpet can also be simulated, but need a nonlinear energy input simulating the reed or lips (see for instance this paper on clarinet modeling by Gary Scavone). I haven't yet found a good implementation of this for Pd, but it would be an interesting thing to look for and/or try.
Credit: To be credited with completing this practical, you'll need to show one of the teaching staff a working instance of one of these suggestions.
Followup: During class, I modified karpluck~ to support a few extra parameters: a single low-pass filter applied to the excitation (to get low-pass noise initialization instead of white, like using a softer pick), and tremelo depth and modulation rate, to modulate the feedback low-pass to give a kind of tremelo/vibrato effect. See karpluckvib~.pd and demo_karpluckvib.pd .
Weds 2016-02-03: Filtering
Last week we looked at a fairly complex structure built in Pd. This week, we'll back up a bit and play with some simple filters within Pd.
Pd provides a range of built-in filtering objects: [lop~], [hip~], [bp~] (and its sample-rate-controllable twin [vcf~]), the more general [biquad~], and the elemental [rpole~], [cpole~] and [rzero~], [czero~] (see the filters section of the Floss Pd manual, and the Subtractive Synthesis chapter of Johannes Kreidler's Pd Tutorial).
The patch demo_filters.pd provides a framework to play with these filter types. It uses playsound~.pd to allow you to play (and loop) a WAV file, select4~.pd to select one of 4 audio streams via "radio buttons", and plotpowspec~.pd (slightly improved from last week) to plot the running FFT spectrum, as well as the [output~] built-in from Pd-extended. You can download all these patches in prac02.zip.
Try listening to the various sound inputs provided by the top [select4~] through the different filters provided by the bottom [select4~]. Try changing the cutoff frequency with the slider (as well as the Q of the bpf with the number box); listen to the results and look at the short-time spectrum. You can try loading the speech and guitar samples into the [playsound~] unit to see how filtering affects "real" sounds (click the button at the bottom right of [playsound~] to bring up the file selection dialog; click the button on the left to play the sound, and check the toggle to make it loop indefinitely).
Here are a few further experiments you could try:
- The standard [lop~] and [hip~] units are single-pole and thus give a fairly gentle roll-off. Try repeating them (i.e., applying several instances of the filter in series) to get a steeper filter. How does that sound?
- Notch (bandstop) filters are noticeably absent from this lineup. Of course, [biquad~] can be used to create an arbitrary pole/zero filter, and the extended unit [notch] can generate the appropriate parameters to make a notch filter. See if you can get one going, and see what it sounds like.
- Pd-extended includes a large number of more complex filter units, including [lpN_TYPE~], where N is the order, and TYPE is butt (Butterworth), cheb (Chebyshev), bess (Bessel), or crit (for critical damping). There are also a number of more exotic things like [resofilt~] and [comb~]. You can try these to see how they sound.
- Changing a filter's cutoff in real-time can have a dramatic sound, particularly for bandpass and notch. See if you can rig up a low-frequency modulator for the cutoff frequency control. (You can look at how I added modulated cutoff in the body of my modified karpluckvib~.pd from last week's practical).
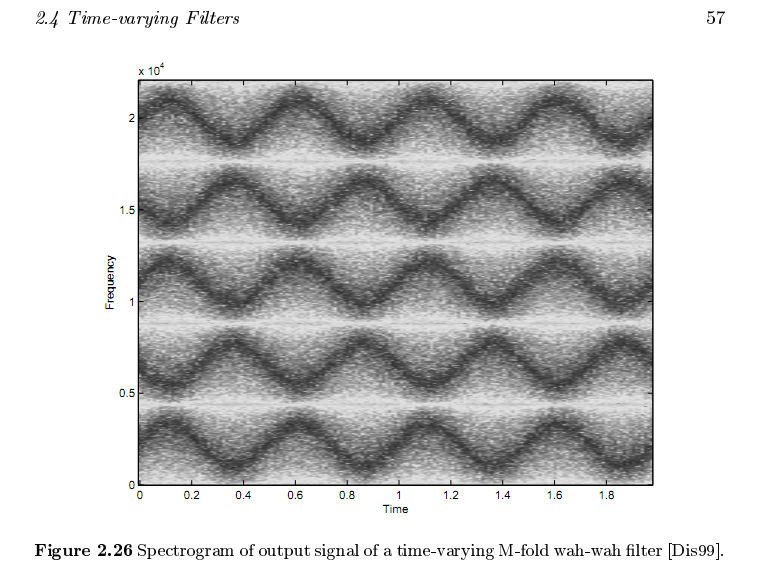
- Some well known instances of modulated filtering are guitar "pedal" effects like wah-wah and chorus. We'll be talking about these in more detail later in the semester, but according to this image from page 57 of Udo Zoelzer's DAFx book, a set of bandpass filters with complementary motion gives a good wah-wah. Can you build this?
- Multiple voices singing approximately the same notes lead to rapidly-moving notches in frequency due to phase cancellations. A "chorus" effect can make a single voice sound like a chorus by introducing a complex pattern of moving notches. Can you build something like that? What is the effect of making the motion of the different notches synchronized or incoherent (different frequencies)?
- The Karplus-Strong plucked string algorithm (slide 13 of last week's slides) is actually just an IIR comb filter -- a set of highly-resonant poles at the harmonics of the fundamental frequency -- whose input is the initial wave shape followed by zeros. How could you simulate such a filter with these primitives?
{kind=link}
Followup: I made a "low-frequency noise" generator patch, lfnoise.pd. You can use the logarithmically-scaled "scale" slider to generate random values over a wide range of scales, and you can use the "offset" slider to make the midpoint be different from zero. The "samplerate" slider controls how many new random values are produced each second, which also affects how fast they vary. In the modified patch demo_filters_mod.pd, I hook it up to control the break frequency of the filters - try listening to the noise signal going through the bpf.
Weds 2016-02-10: Analog synthesis
This week we'll experiment with simulating an analog synthesizer with Pd.
The Pd analog synth simulator consists of several patches:
- oscillator~.pd implements a band-limited square wave with pulse-width modulation, including a low-frequency oscillator (LFO) to modulate the pulse width.
- adsr0~.pd provides a simple ADSR envelope generator. We use two of these, one for the amplitude and one for the filter.
- voice~.pd includes an [oscillator~] and two [adsr0~]s along with [vcf~] to provide a complete synthesizer voice.
- demo_voice.pd is a simple main patch that routes events from the keyboard to the [voice~] and provides sliders to control the various parameters.
You can download all these patches along with some support functions in the zip file prac03.zip. Load demo_voice.pd into Pd, and the synth should run.
Things to investigate:
- Analog synth programming: You could choose one of the sounds from Juno-106 examples page, or you could download and run the stand-alone demo version of the Loomer Aspect analog synth emulator that I demo'd in class (you need a MIDI keyboard to drive it, but you can use the open-source Virtual MIDI Piano Keyboard). Although our basic synth simulation is simple (and only monophonic), it includes all the basic components you should need to make the full range of classic analog synth sounds. By starting from one of the Aspect presets (many of which sound amazing), you can actually see how the sound is put together as a basis for duplicating it (although you might need to consult the Aspect manual to full decipher how things are connected together: most controls have up to three inputs which are summed).
- Additional oscillators: One thing Aspect and the Juno have that's not in the basic synth is multiple oscillators, including a "sub-oscillator", for instance a square wave tuned an octave below the main oscillator. Can you modify the simple synth to include this? How does it sound? You might want to also deploy an LFO, perhaps using the lfo.pd patch.
- Modified filter: Another difference with the Juno is that its variable filter is a 24 dB/octave low-pass, much steeper than the single vcf (voltage controlled filter) unit in the patch. You could improve this by adding multiple filters in cascade; how does this affect the sound?
- Improved ADSR: The existing ADSR generates linear amplitude envelopes, but these don't sound as good as nonlinear envelopes, for instance in dB or quartic mappings. Miller's book discusses this in chapter 4; see if you can change the amplitude mapping from the ADSR to improve the sound.
- Drum sounds: You can also create drum sounds with analog synthesizers, but you usually need a noise source instead of, or in addition to, an oscillator. Try using the "noise~" unit to broaden the range of sounds from the synthesizer, and see if you can get some convincing drum sounds (or other interesting sounds). A good drum sound might also want some pitch variation, perhaps generated by an additional ADSR unit.
- Velocity sensitivity: One big musical musical limitation of our synthesizer is that it has no dynamic control - no variation of the sound based on how hard you strike the keys. With the computer keyboard as controller, we're pretty much stuck, but I have a couple of USB musical keyboards as well. If you want to try playing with one of these, they will give you a "velocity" value out of the keybd unit. You could then use this to modulate the amplitude, and maybe even the timbre, of the synth.
This week's practical is the basis of mini-project 1, for which you will be submitting a short report in two weeks' time.
Weds 2016-02-17: Sinusoidal Synthesis
This week we use Pd to perform additive synthesis by controlling the frequencies and magnitudes of a bank of sinewave oscillators based on parameters read from an analysis file written by the SPEAR program we saw in class.
The main additive patch instantiates a bank of 32 oscillators, and provides the controls to load an analysis file, to trigger playback, and to modify the time and frequency scale. The actual parsing of the SPEAR file is provided by loadspearfile, and the individual sinusoid partials are rendered by mypartial. Here are some analysis files for notes from a violin, trumpet, and guitar. You can download all these files in prac04.zip,
You can experiment with playing back each of these, turning individual partials on or off, and adjusting the time and frequency scales. When the analysis file contains more harmonics than the number of oscillators (32), some of the sinusoids are dropped from the synthesis. You can identify (roughly) which harmonic is which by the average frequency and summed-up magnitude of each harmonic, which gets displayed on each individual [mypartial] patch in additive.pd.
Here are the things to try:
- Using the keybd patch, make the sound resynthesize under keyboard control, modifying its pitch to reflect the key pressed.
- Try adding inharmonicity to the sound i.e. stretching the frequencies not by a constant factor, but according to some other rule. For instance, what happens if you add a constant offset to each frequency? What happens if you scale only the frequencies above a certain minimum?
- Add vibrato (slow frequency modulation) to the resynthesized note.
- Implement looping sustain, where the parameters cycle within some subportion of the analysis data while a key is held down (to provide sustain), then proceed through to the end of the sample once the key is released.
- Try making a sinusoidal analysis of a sound of your own (using SPEAR) and see how well it works for other sounds, perhaps a spoken word. Remember that the system will only resynthesize the first 32 sinusoids it reads from file, so be careful to prune out the less important tracks before you "export" from SPEAR. (You can also modify the SPEAR analysis files in Matlab using spearread.m and spearwrite.m).
Note: if you modify the mypartial patch, it's probably a good idea to close and reopen the parent additive patch. I'm not sure how good Pd is at keeping multiple instantiations in sync when one instance is edited. Re-opening the parent patch will re-instantiate all the mypartials, so they should all get updated.
Wed 2016-02-24: LPC
This week we will experiment with LPC analysis/synthesis in Pd using the lpc~ and lpcreson~ units by Edward Kelly and Nicolas Chetry, which are included with the Pd-extended package.
The patch lpc.pd uses these units to perform LPC analysis and synthesis, including taking the LPC filters based on one sound and applying them to a different sound (cross-synthesis). The main patch handles loading, playing, and selecting the soundfiles, and uses the additional patches loadsoundfile.pd to read in sound files, playloop.pd to play or loop a sound file, and audiosel~.pd to allow selecting one of several audio streams. The LPC part is done by the lpcanalysis subpatch of the main patch, shown to the right. It "pre-emphasizes" both voice and excitation to boost high frequencies, then applies lpc~ to the voice signal to generate a set of LPC filter coefficients and a residual. The [myenv] subpatch then calculates the energy (envelope) of the residual, and the excitation is scaled to reflect this envelope. This excitation, along with the original filter coefficients (delayed by one block to match the delay introduced by [myenv]), is passed to lpreson~, which simply implements the all-pole filter to impose the voice's formant structure on the excitation. A final de-emphasis re-balances low and high freqencies. You can download these patches in prac05.zip.
The entire lpcanalysis subpatch is applied to overlapping windows of 1024 samples at half the sampling rate of the parent patch (i.e. 1024/22050 = 46.4 ms) thanks to the block~ unit, a special feature of Pd which allows subpatches to have different blocking etc. from their parents. On coming out of the subpatch, Pd will overlap-add as necessary, so we apply a final tapered window (from the $0-hanning array) to the outputs. tabreceive~ repeatedly reads the hanning window on every frame.
Here is a list of options for things to investigate:
- Run the basic cross-synthesis function by loading sm1-44k.wav as the voice input, and Juno106_Strings.wav as the excitation input. (You'll probably need to enable the dsp on the output~ unit and turn up the volume.) Notice how the strings sound can still be understood as speech.
- Try selecting the noise input as excitation (using the audiosel~ panel) instead. This lets you hear the information being carried by the LPC filters in its most neutral form.
- Try using some other sounds as source and/or excitation (they should be short, mono WAV files sampled at 44 kHz). What happens if you swap the original two sound files?
- Try varying the LPC Filter Order (also called the model order) with the number box (click and drag up and down to change the number). How does it affect the synthesis sound?
- Change the patching to the output~ unit to listen to the "residual" output from the lpcanalysis subpatch. How does the residual sound change with the model order?
- The subpatch uses the residual's envelope (extracted by [myenv]) to scale the excitation. If you disable this (e.g. by patching the excitation directly into the input of lpreson~), how does this affect the sound?
- The LPC analysis relies on Pd's block~ unit to manage the block size, overlap-add, and sample rate scaling. You can try varying this to see e.g. how the sound varies if you use a longer block size and/or different sampling rate. (Remember to regenerate the hanning window array if you change the block size). Be warned, however: I have been able to crash both Pd and the audio drivers with these settings.
- The second output from the [pd lpcanalysis] block is the residual (the whitened excitation). You can't feed this directly back in as excitation, because that introduces a delay-free loop. But you can delay it by one analysis block, using the [pack~] - [unpack~] trick as is used inside the patch. You could then, for instance, turn this into a buzz-hiss-style excitation with [expr~ $v1>0], then use it as excitation. How does that sound?
- One weakness with this setup is that the excitation may not have a "flat" spectrum to provide sufficient high-frequency energy for the LPC filters to "shape". One approach to this is to use a second lpc~ unit to extract a (whitened) residual for the excitation too (the actual LPC coefficients from the excitation are discarded). Try this out and see how it affects the sound.
- In principle, LPC cross-synthesis can be used for time scaling, simply by slowing down the frame rate between analysis and synthesis (or possibly by interpolating the LPC parameters). The framework in lpcanalysis won't support this, however, as it uses LPC parameters extracted in real time from the speech waveform. To do timescaling, you'd need to implement something more like the way we did sinusoidal synthesis last week, where the parameters are written to table, then read back as needed on synthesis. You should, however, be able to implement both analysis and synthesis stages within Pd, without needing to read or write the parameters to an external file.
Weds 2016-03-02: Reverb
For this week's practical you will examine a reverberation algorithm, trying to understand the link between the algorithm controls and pieces, and the subjective experience of the reverberation. We will be working with the algorithm in the rev2~ reverberator patch that comes with Pd, although we'll be modifying our own version of it. It's based on the design described in the 1982 Stautner and Puckette paper.
You will use the following Pd patches:
- test_reverb_rev2.pd - main test patch
- loadsoundfile.pd - to load a sound file
- playloop.pd - to play a sound file
You can download them all in prac06.zip.
The main test harness allows you to adjust the control parameters of the reverb patch, and to feed in impulses, short tone bursts of different durations, or sound files. You can also sample the impulse response and write it out to a wave file, to be analyzed by an external program.
- Try varying the main reverb controls: Liveness, Crossover Frequency, HF Damping, as well as the balance between "wet" and "dry" sound. What are the effects on the sounds of these different effects? How does the effect on the sound you hear depend on the kind of sound you use as test input?
- Try writing out the impulse response of a setting to a sound file (using the "write -wave ..." message at the bottom right) and load it into Matlab (or another sound editor) to look in more detail at its waveform and spectrogram. Does it look like you expect? How do the controls affect these objective properties of the signal?
- Open the my_rev2 subpatch (shown to the right). The main work is done by four delay lines, implemented with the four delwrite~/delread~ pairs. You can vary the actual delays of these four lines. How does this affect sound? Are the default values critical to the sound?
- The other main part of the reverberator is the early echos, implemented in the early-reflect subpatch. If you open that subpatch, you'll find a fader to choose between including those early echos, or just feeding the direct path into the delay lines. How does this affect the sound?
- This reverberator implements a mixing matrix implemented with the 4x4 block of *~ 1 and *~ -1 elements in the lower left. Try flipping some of these; what happens?
Here are some sound files you can use to try out the reverberator: voice.wav, guitar.wav, drums.wav, drums2.wav.
Weds 2016-03-09: Pitch tracking
Miller Puckette (author of Pd) created a complex pitch tracking object called sigmund~. This week we'll investigate its use and function.
You will use the following Pd patches:
- test_sigmund.pd - main test harness
- playsound~.pd - latest abstraction to load and play back a sound file
- voice~.pd, oscillator~.pd, adsr0~.pd - the analog synthesizer components
- grapher.pd - utility to plot the value of a control line as a function of time
- sineoscf~.pd - sinusoidal oscillator with fade-out, based on mypartial~
You can download these in prac07.zip.
sigmund~ operates in various different modes - as a raw pitch tracker, as a note detector/segmenter, and also as a sinusoid tracker. We'll try each mode.
- In the test_sigmund patch, the left-most path runs sigmund~ in raw pitch tracking mode, echoing the pitch and energy it detects with a sawtooth oscillator. Try running this with the mic input (adc~). How well can it track your voice? What kind of errors does it make?
- If instead you hook up the playsound~ unit, you can feed an existing soundfile into the tracker. Try voice.wav, speech.wav, and piano.wav. How does it do?
- The second path runs sigmund~ in note-detecting mode i.e. it first detects the raw pitch, then tries to convert that into a series of note events. We have fed these to our analog synthesizer patch so we can hear them as distinct notes. Try this for the voice and piano.
- Note tracking depends on a lot of thresholds, which can be set via messages to sigmund~. Try varying the "growth" (minimum level increase, in dB, before a new note is reported) and "vibrato" (maximum pitch deviation, in semitones, before a new note is reported) using the provided sliders. Can you improve the note extraction? How do the best settings depend on the material?
- The third branch uses sigmund~ as a sinusoid tracker (analogous to SPEAR), then connects the output to a set of sinusoidal oscillators to reconstruct a version of the sound. Try feeding different sounds into this: how does it do? You can vary the cross-fade time of the oscillators with the "fadetime" slider - what does this do?
Note that Mini project 2 is based on this practical and the following one (on autotuning).
Weds 2016-03-23: Autotune
Given pitch tracking and pitch modification, we can now put them both together to modify the pitch towards a target derived from the current input pitch, i.e., autotune, in which a singer's pitch is moved to the nearest exact note to compensate for problems in their intonation.
We can use sigmund both to track the singing pitch, and to analyze the voice into sinusoids which we can then resynthesize after possibly changing the pitch. We'll use the following Pd patches:
- autotune.pd - the main patch, shown above
- sigmundosc~.pd - a patch to take sigmund's "tracks" message stream and resynthesize into audio
- sineosc~.pd - the individual sinusoid oscillator, modified from last time to accept frequency scaling messages
- my_lop.pd - a simple one-pole low-pass filter for control (not audio) values
- playsound~.pd and grapher.pd from last time.
You can download all these patches in prac08.zip.
Loading a sound file then playing it into the patch should generate a close copy of the original voice, but quantized to semitone pitches. The "pitch smoothing" slider controls how abruptly the pitch moves between notes. Try it on some voice files, such as the Marvin Gaye voice.wav, the query-by-singing example 00014.wav, or my pitch sweep ahh.wav. You can also try it on live input by hooking up the adc~ instead of the soundfile playback, but you will probably need to use headphones to avoid feedback.
Here are some things to investigate:
- What is the purpose of the moses 0 block in the middle of the patch? If you remove it, and hook the raw pitch input directly into the quantizer, what changes?
- What is the left-hand output of the moses block achieving? Can you hear the difference if it disconnected?
- Occasionally you may hear glitches in the output pitch. What is causing these? How might they be avoided?
- The "center" tones are defined by the A440 reference of the default MIDI scale. However, the query-by-humming example seems to be misaligned. Can you add a tuning offset to allow the input pitch to be systematically offset prior to quantization? Does this help? Could it be automated?
- Currently, the quantization just takes the nearest semitone. How could you make it select only the "white notes" of a major scale, i.e. skipping every 2nd semitone except between E/F and B/C?
- The current system generates singing with a mostly steady pitch, but singers often add vibrato (pitch modulation at around 6 Hz). How could we add vibrato with the autotune?
- Can you impose an entirely unrelated pitch (e.g. a monotone, or a steady slow vibrato) on an input signal?
Weds 2016-03-30: Beat tracking
As promised, we now move on from the real-time processing of Pd to do some offline analysis using Python. (In fact, beat tracking in real time is an interesting and worthwhile problem, but doing it offline is much simpler.)
If you're new to Python, there are some good introductory materials provided by Software Carpentry, an organization that promotes good software practice in research and academia. You can start with their Programming with Python tutorial.
librosa is a Python library of music-audio processing routines created by Brian McFee when he was a post-doc in my lab (and now including the work of many other contributors). It includes an implementation of the dynamic-programming beat tracker described in the lecture.
You can see it in action in the beat tracking IPython notebook. You'll need to install IPython notebook (now called Jupyter), for instance via the Anaconda installation, as well as installing librosa and mir_eval, which I did via:
/Applications/anaconda/bin/pip install librosa /Applications/anaconda/bin/pip install mir_eval
.. where /Applications/anaconda was where Anaconda was installed.
If you download the ipynb file of the beat-tracking notebook, you'll be able to open it with Anaconda's notebook, then re-execute all the cells. You'll need to download the McKinney/Moelants data in mirex06examples.zip.
Here are some things to try:
- Go through the steps in the notebook to understand the basic pieces.
- Investigate one of the examples where the beat tracker doesn't do so well. What went wrong? How consistent are the human results?
- The one parameter of the DP beat tracker the balance between local onset strength and inter-onset-time consistency, called tightness in the __beat_tracker core routine. Larger tightness results in a more rigid tempo track, better able to bridge over rhythmically ambiguous regions, but less able to cope with small variations in tempo. Can you improve the baseline performance by changing the value of tightness (e.g., setting the optional tightness parameter to librosa.beat.beat_track)?
- The tempo estimation is essentially independent of the beat tracking. Sometimes you can improve the agreement with human tappers simply by "biasing" the tempo picking differently. See if you can improve performance by modifying the start_bpm parameter passed to librosa.beat.estimate_tempo.
- librosa.onset.onset_strength function generates the onset envelope that is at the core of beat tracking. It has several options that we're not using. For instance, what happens if you replace the default cross-band aggregation function (taking the mean) with a median, e.g. specifying aggregate=np.median as an additional argument?
- Sometimes the beat tracker has a systematic bias (time shift) relative to human performance. Can you improve performance by adding a fixed time offset to all beat returns? Can you calculate a histogram of system beat times relative to the nearest ground truth time?
- What happens if the tempo varies within a single performance? Maybe you can find an example like that on your computer - try it out!
Weds 2016-04-06: Chord Recognition
This week we will train and use a simple Hidden Markov Model to do chord recognition. We will be using precomputed chroma features along with the ground-truth chord labels for the Beatles opus that were created by Chris Harte of Queen Mary, University of London. The original label files are available at isophonics.org.
This practical is again run from IPython, with the chord recognition notebook. You can download all the precomputed feature and label data for the Beatles as: beatchromlabs.zip (8MB). These were generated from the 32 kbps audio (141MB) using the beat-synchronous chroma features notebook. (You can download the entire ELEN E4896 source repository from GitHub as elene4896-master.zip.)
Things to try:
- Try training on different numbers of training tracks (e.g. train_ids[:50]). How does this affect performance?
- Look at the variation in accuracy on the different items in the test set. How much does it vary? Can you explain this variation from your knowledge of the different tracks?
- If you listen to the resynthesis of the recognized chords (i.e., labels_to_chroma(recognize_chords(...))), can you hear why the recognizer made mistakes, i.e., do the mistaken chords make sense?
- read_beat_chroma_labels includes simple feature normalization, to make the maximum value of each chroma vector equal to 1. You can probably improve performance by modifying this e.g. by applying a compressive nonlinearity such as chroma_features = chroma_features**0.25. See how this affects performance.
- The Hidden Markov Model smoothing relies on the large self-loop probabilities of the transition matrix. See what happens if you replace transition with a flat matrix e.g. np.ones((25,25)) (which is equivalent to not using an HMM and just taking the most-likely model for each frame), or some mixture between that and a large self-loop probability e.g. np.eye(25)+0.1*np.ones((25,25)).
This week's practical is the basis of Mini Project 3.
Weds 2016-04-13: Cover Song Detection
This week's practical compares three cover song detection algorithms on a small database of cover song pairs, covers80. The IPython notebook e4896_coversongs.ipynb leads you through their implementation. You can download the precalculated beat-chroma features for the cover song set as coversongs-beatchromftrs.zip.
Your mission is to improve the performance of any of the algorithms over their original form. Things to try:
- With this small data set (we're only using the first 20 of the 80 cover pairs), you can actually go in and look at the errors. Try visualizing the match between the a reference item and a "mistaken" cover (for any algorithm) to see if you get insight into what went wrong.
- We noticed in class that the first track has beat tracking at different metrical levels for the two versions, which is a disaster for cross-correlation comparison, which lacks any mechanism to correct timing differences. You might be able to get around this by performing multiple comparisons between each pair of tracks - first cross-correlating the full array, then between one full array and the other one downsampled to discard every other time frame (e.g., ftrs[::2]). Just taking the largest cross-correlation peak of any of these comparisons ought to find the truest comparison. Can you improve the average performance?
- Downsampling both feature arrays can significantly speed up processing. Does it reduce accuracy?
- It was noted in class that the plain DTW alignment cannot handle cases where the cover version is in a different key (how often does this happen?). Can you improve its performance by either trying all possible relative transpositions (hint: use chroma_rotate) and reporting the best match, or even guessing the single best transposition by comparing, say, the average chroma for both tracks?
- The DTW alignments often have trouble at the ends, but find good alignments in the middle. Can you improve average accuracy for either DTW approach by calculating the match quality based on, say, only the middle 50% of the path_cost?
- The default penalty value of 0.2 used in DTW is somewhat tuned for the chroma feature vectors, and is likely not well-matched to the binary chroma-rotation features. Try investigating other values.
- In the summary distance matrices, there are several cases of 'popular decoys' with smaller-than-average distances to many tracks (horizontal/vertical "stripes" in the distance matrix). Can you figure out what's different about these tracks? Is there some way to correct this?
Weds 2016-04-20: Fingerprinting
Our practical investigation of fingerprinting will use audfprint, a re-implementation of the Shazam fingerprint system in Python that I put together. (You can download the files via the zip file which you'll need to rename to audfprint/ after unzipping, or you can git clone https://github.com/dpwe/audfprint.git if you have git). You can look at the explanation and examples on that web page to see how it works as a stand-alone program, but we will use it as a library.
The Fingerprint matching notebook takes you through building up the hash representation for query audio, and matching it against the example reference database of 8752 tracks in uspop-n10-b20.fpdb (55 MB). (There's also a more detailed version with twice the landmark density and five times as many total records per hash in uspop-n20-b100.fpdb, but it's 188 MB).
Things to do:
- The basic variables affecting matching success are (a) query duration, (b) query audio quality (e.g., signal-to-noise ratio), and (c) hash density (in database and/or query). Make some plots illustrating match quality (e.g., average number of matching landmarks) as you vary one or more of these dimensions.
- It turns out that trimming the query by a fraction of the spectogram hop size used in the analyzer (256 points, or 16 ms at 16 kHz) can greatly affect match quality. Make a plot of the number of matched hashes versus query start time varying the start time over a 32 ms range (you can use excerpt_waveform(), or simply "slice" the query waveform with [start:end] notation).
- What happens when you mix two queries together, e.g. result, _= match_waveform(queries[0] + queries[1], sr, database, analyzer, matcher)? Can you control which query dominates?
- What's going on with the second match for "Taxman" (the one at time offset -4528 frames). Can you see it on the landmark scatter? Can you explain it?
- As we saw, there are some duplicates in the uspop corpus (we didn't have this fingerprinter when we made it). You can try to find them by retrieving the hashes for each track in the dataset via hashes = database.retrieve(database.names[index]), then running those hashes as a query. Of course, you expect the top hit to be the track itself. But any other hits may be duplicate tracks. How many can you find? Are they exact duplicates? Are there any genuine "false alarms" - different tracks that are incorrectly reported as matching? Can you compare the audio under the matching hashes?
Weds 2016-04-27: Unmixing
This week we will experiment with separating musical sources by using Nonnegative Matrix Factorization (NMF) to decompose a short-time Fourier transform magnitude (i.e., a spectrogram) into a time-frequency mask that can be used to isolate sources. We will be following the NMF decomposition notebook. The piano sound example (the opening of Glenn Gould's recording of Bach's Well Temepered Clavier) is here: gould-wtc1.wav. You can read about the underlying algorithm in: T. Virtanen, Monaural Sound Source Separation by Nonnegative Matrix Factorization With Temporal Continuity and Sparseness Criteria , IEEE Tr. Audio, Speech & Lang. Proc., 15(3):1066-1074, March 2007.
Things to investigate:
- The nature of the decomposition naturally depends on the rank of the modeling (i.e., n_components, the number of rows and columns in H and W respectively). What happens when you use significantly higher, or significantly lower, ranks?
- The alpha parameter controls the degree of regularization (controlling the values of the factors, rather than simply optimizing the approximation), and l1_ratio controls how much this regularization pushes for sparsity (which tends to drive small elements in H to zero). What happens as you vary these values?
- Piano is a good match to the "separable" spectrogram model assumed by NMF. What happens if you try some different music, perhaps including less stable sounds such as voice?
- Our scheme for selecting components is pretty crude. Can you improve results by manually selecting components, or by coming up with a different scheme to select them? How does a single component sound, and how many do you need to make a plausible separated sound? Can you remove artifacts such as the click of the piano keys?

This work is licensed under a Creative Commons Attribution-NonCommercial 3.0 Unported License.
Dan Ellis <[email protected]>
Last updated: Sun Apr 24 16:30:21 EDT 2016