Although HTK was designed primarily for building continuous density HMM systems, it also supports discrete density HMMs. Discrete HMMs are particularly useful for modelling data which is naturally symbolic. They can also be used with continuous signals such as speech by quantising each speech vector to give a unique VQ symbol for each input frame. The HTK module HVQ provides a basic facility for performing this vector quantisation . The VQ table (or codebook) can be constructed using the HTK tool HQUANT.
When used with speech, the principle justification for using discrete HMMs is the much reduced computation. However, the use of vector quantisation introduces errors and it can lead to rather fragile systems. For this reason, the use of continuous density systems is generally preferred. To facilitate the use of continuous density systems when there are computational constraints, HTK also allows VQ to be used as the basis for pre-selecting a subset of Gaussian components for evaluation at each time frame.
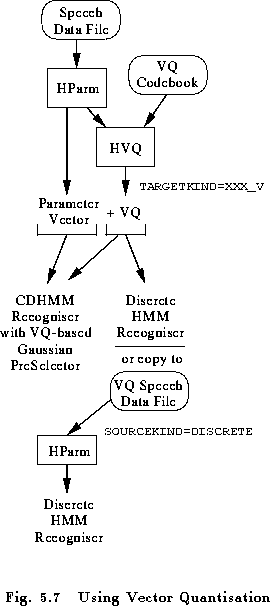
Fig. 5.7 illustrates the different ways that VQ can be used in HTK for a single data stream. For multiple streams, the same principles are applied to each stream individually. A converted speech waveform or file of parameter vectors can have VQ indices attached simply by specifying the name of a VQ table using the configuration parameter VQTABLE and by adding the _V qualifier to the target kind. The effect of this is that each observation passed to a recogniser can include both a conventional parameter vector and a VQ index. For continuous density HMM systems, a possible use of this might be to preselect Gaussians for evaluation (but note that HTK does not currently support this facility).
When used with a discrete HMM system, the continuous parameter vectors are ignored and only the VQ indices are used. For training and evaluating discrete HMMs, it is convenient to store speech data in vector quantised form. This is done using the tool HCOPY to read in and vector quantise each speech file. Normally, HCOPY copies the target form directly into the output file. However, if the configuration parameter SAVEASVQ is set, then it will store only the VQ indices and mark the kind of the newly created file as DISCRETE. Discrete files created in this way can be read directly by HPARM and the VQ symbols passed directly to a tool as indicated by the lower part of Fig. 5.7.
HVQ supports three types of distance metric and two organisations of VQ codebook. Each codebook consists of a collection of nodes where each node has a mean vector and optionally a covariance matrix or diagonal variance vector. The corresponding distance metric used for each of these is simple Euclidean, full covariance Mahalanobis or diagonal covariance Mahalanobis. The codebook nodes are arranged in the form of a simple linear table or as a binary tree. In the linear case, the input vector is compared with every node in turn and the nearest determines the VQ index. In the binary tree case, each non-terminal node has a left and a right daughter. Starting with the top-most root node, the input is compared with the left and right daughter node and the nearest is selected. This process is repeated until a terminal node is reached.
VQ Tables are stored externally in text files consisting of a header followed by a sequence of node entries. The header consists of the following information
magic - a magic number usually the original parameter kindEvery node has a unique integer identifier and consists of the followingtype - 0 = linear tree, 1 = binary tree
mode - 1 = diagonal covariance Mahalanobis
2 = full covariance Mahalanobis
5 = Euclidean
numNodes - total number of nodes in the codebook
numS - number of independent data streams
sw1,sw2,... - width of each data stream
stream - stream number for this nodeThe inclusion of the optional variance vector or covariance matrix depends on the mode in the header. If present they are stored in inverse form. In a binary tree, the root id is always 1. In linear codebooks, the left and right daughter node id's are ignored.vqidx - VQ index for this node (0 if non-terminal)
nodeId - integer id of this node
leftId - integer id of left daughter node
rightId - integer id of right daughter node
mean - mean vector
cov - diagonal variance or full covariance