The outcome of the previous stage is a set of triphone HMMs with all triphones in a phone set sharing the same transition matrix. When estimating these models, many of the variances in the output distributions will have been floored since there will be insufficient data associated with many of the states. The last step in the model building process is to tie states within triphone sets in order to share data and thus be able to make robust parameter estimates.
In the previous step, the TI command was used to explicitly tie all members of a set of transition matrices together. However, the choice of which states to tie requires a bit more subtlety since the performance of the recogniser depends crucially on how accurate the state output distributions capture the statistics of the speech data.
HHED provides two mechanisms which allow states to be clustered and then each cluster tied. The first is data-driven and uses a similarity measure between states. The second uses decision trees and is based on asking questions about the left and right contexts of each triphone. The decision tree attempts to find those contexts which make the largest difference to the acoustics and which should therefore distinguish clusters.
Decision tree state tying is performed by running HHED in the normal way, i.e.
HHEd -B -H hmm12/macros -H hmm12/hmmdefs -M hmm13 \
tree.hed triphones1 > log
Notice that the output is saved in a log file. This is important since
some tuning of thresholds is usually needed.
The edit script tree.hed, which contains the instructions regarding which contexts to examine for possible clustering, can be rather long and complex. A script for automatically generating this file, mkclscript, is found in the RM Demo. A version of the tree.hed script, which can be used with this tutorial, is included in the HTKTutorial directory. The entire script appropriate for clustering English phone models is too long to show here in the text, however, its main components are given by the following fragments:
RO 100.0 stats
TR 0
QS "L_Class-Stop" {p-*,b-*,t-*,d-*,k-*,g-*}
QS "R_Class-Stop" {*+p,*+b,*+t,*+d,*+k,*+g}
QS "L_Nasal" {m-*,n-*,ng-*}
QS "R_Nasal" {*+m,*+n,*+ng}
QS "L_Glide" {y-*,w-*}
QS "R_Glide" {*+y,*+w}
....
QS "L_w" {w-*}
QS "R_w" {*+w}
QS "L_y" {y-*}
QS "R_y" {*+y}
QS "L_z" {z-*}
QS "R_z" {*+z}
TR 2
TB 350.0 "aa_s2" {(aa, *-aa, *-aa+*, aa+*).state[2]}
TB 350.0 "ae_s2" {(ae, *-ae, *-ae+*, ae+*).state[2]}
TB 350.0 "ah_s2" {(ah, *-ah, *-ah+*, ah+*).state[2]}
TB 350.0 "uh_s2" {(uh, *-uh, *-uh+*, uh+*).state[2]}
....
TB 350.0 "y_s4" {(y, *-y, *-y+*, y+*).state[4]}
TB 350.0 "z_s4" {(z, *-z, *-z+*, z+*).state[4]}
TB 350.0 "zh_s4" {(zh, *-zh, *-zh+*, zh+*).state[4]}
TR 1
AU "fulllist"
CO "tiedlist"
ST "trees"
Firstly, the RO command is used to set
the outlier threshold to 100.0 and load the statistics
file generated at the end of the previous step. The
outlier threshold determines the minimum occupancy of
any cluster and prevents a single outlier state forming a singleton cluster
just because it is acoustically very different to all the other states. The
TR command sets the trace level to zero
in preparation for loading in the questions. Each
QS command loads a single question and
each question is defined by a set of contexts. For example, the first
QS command defines a question called L_Class-Stop which is
true if the left context is either of the stops p,
b, t, d, k or g.
Notice that for a triphone system, it is necessary to include questions referring to both the right and left contexts of a phone. The questions should progress from wide, general classifications (such as consonant, vowel, nasal, diphthong, etc.) to specific instances of each phone. Ideally, the full set of questions loaded using the QS command would include every possible context which can influence the acoustic realisation of a phone, and can include any linguistic or phonetic classification which may be relevant. There is no harm in creating extra unnecessary questions, because those which are determined to be irrelevant to the data will be ignored.
The second TR command enables intermediate level progress reporting so that each of the following TB commands can be monitored. Each of these TB commands clusters one specific set of states. For example, the first TB command applies to the first emitting state of all context-dependent models for the phone aa.
Each TB command works as follows. Firstly, each set of states defined by the final argument is pooled to form a single cluster. Each question in the question set loaded by the QS commands is used to split the pool into two sets. The use of two sets rather than one, allows the log likelihood of the training data to be increased and the question which maximises this increase is selected for the first branch of the tree. The process is then repeated until the increase in log likelihood achievable by any question at any node is less than the threshold specified by the first argument (350.0 in this case).
Note that the values given in the RO and TB commands affect the degree of tying and therefore the number of states output in the clustered system. The values should be varied according to the amount of training data available. As a final step to the clustering, any pair of clusters which can be merged such that the decrease in log likelihood is below the threshold is merged. On completion, the states in each cluster i are tied to form a single shared state with macro name xxx_i where xxx is the name given by the second argument of the TB command.
The set of triphones used so far only includes those needed to cover the training data. The AU command takes as its argument a new list of triphones expanded to include all those needed for recognition. This list can be generated, for example, by using HDMAN on the entire dictionary (not just the training dictionary), converting it to triphones using the command TC and outputting a list of the distinct triphones to a file using the option -n
HDMan -n fulllist -l flog beep
The effect of the AU command is to use the decision trees to synthesise all of the new previously unseen triphones in the new list.
Once all state-tying has been completed and new models synthesised,
some models may share exactly
the same 3 states and transition matrices and are thus identical.
The CO command is used
to compact the model set by finding all identical models and tying them
together , producing a new list of models
called tiedlist.
, producing a new list of models
called tiedlist.
One of the advantages of using decision tree clustering is that it allows previously unseen triphones to be synthesised. To do this, the trees must be saved and this is done by the ST command . Later if new previously unseen triphones are required, for example in the pronunciation of a new vocabulary item, the existing model set can be reloaded into HHED, the trees reloaded using the LT command and then a new extended list of triphones created using the AU command.
After HHED has completed, the effect of tying can be studied and the thresholds adjusted if necessary. The log file will include summary statistics which give the total number of physical states remaining and the number of models after compacting.
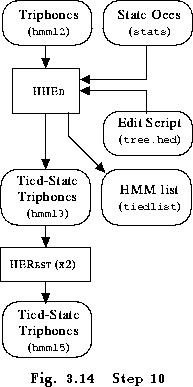
Finally, and for the last time, the models are reestimated twice using HEREST. Fig. 3.14 illustrates this last step in the HMM build process. The trained models are then contained in the file hmm15/hmmdefs.