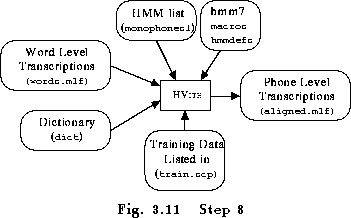
As noted earlier, the dictionary contains multiple pronunciations for some words, particularly function words. The phone models created so far can be used to realign the training data and create new transcriptions. This can be done with a single invocation of the HTK recognition tool HVITE , viz
HVite -l '*' -o SWT -b silence -C config -a -H hmm7/macros \
-H hmm7/hmmdefs -i aligned.mlf -m -t 250.0 -I words.mlf \
-S train.scp dict monophones1
This command uses the HMMs stored in hmm7 to tranform the input
word level transcription words.mlf to the new phone level transcription
aligned.mlf using the pronunciations stored in the dictionary
dict (see Fig 3.11). The key difference between this
operation and the original word-to-phone mapping performed by HLED
in step 4 is that the recogniser considers all pronunciations for each
word and outputs the pronunciation that best matches the acoustic data.
In the above, the -b option is used to insert a silence model at the start and end of each utterance. The name silence is used on the assumption that the dictionary contains an entry
silence silThe -t option sets a pruning level of 250.0 and the -o option is used to suppress the printing of scores, word names and time boundaries in the output MLF.
Once the new phone alignments have been created, another 2 passes of HEREST can be applied to reestimate the HMM set parameters again. Assuming that this is done, the final monophone HMM set will be stored in directory hmm9.