To train a set of HMMs, every file of training data must have an associated phone level transcription. Since there is no hand labelled data to bootstrap a set of models, a flat-start scheme will be used instead. To do this, two sets of phone transcriptions will be needed. The set used initially will have no short-pause (sp) models between words. Then once reasonable phone models have been generated, an sp model will be inserted between words to take care of any pauses introduced by the speaker.
The starting point for both sets of phone transcription is an orthographic transcription in HTK label format. This can be created fairly easily using a text editor or a scripting language. An example of this is found in the RM Demo at point 0.4. Alternatively, the script prompts2mlf has been provided in the HTKTutorial directory. The effect should be to convert the prompt utterances exampled above into the following form:
#!MLF!#
"*/S0001.lab"
ONE
VALIDATED
ACTS
OF
SCHOOL
DISTRICTS
.
"*/S0002.lab"
TWO
OTHER
CASES
ALSO
WERE
UNDER
ADVISEMENT
.
"*/S0003.lab"
BOTH
FIGURES
(etc.)
As can be seen, the prompt labels need to be converted into path names, each
word should be written on a single line and each utterance should be terminated
by a single period on its own. The first line of the file just identifies the
file as a Master Label File (MLF). This is a single file containing a
complete set of transcriptions. HTK allows each individual transcription to
be stored in its own file but it is more efficient to use an MLF.
The form of the path name used in the MLF deserves some explanation since it is really a pattern and not a name. When HTK processes speech files, it expects to find a transcription (or label file) with the same name but a different extension. Thus, if the file /root/sjy/data/S0001.wav was being processed, HTK would look for a label file called /root/sjy/data/S0001.lab. When MLF files are used, HTK scans the file for a pattern which matches the required label file name. However, an asterix will match any character string and hence the pattern used in the example is in effect path independent. It therefore allows the same transcriptions to be used with different versions of the speech data to be stored in different locations.
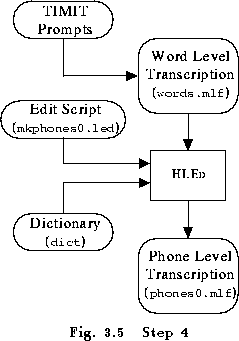
Once the word level MLF has been created, phone level MLFs can be generated using the label editor HLED . For example, assuming that the above word level MLF is stored in the file words.mlf, the command
HLEd -l '*' -d dict -i phones0.mlf mkphones0.led words.mlfwill generate a phone level transcription of the following form where the -l option is needed to generate the path '
*' in the
output pattens.
#!MLF!#
"*/S0001.lab"
sil
w
ah
n
v
ae
l
ih
d
.. etc
This process is illustrated in Fig. 3.5.
The HLED edit script mkphones0.led contains the following commands
EX IS sil sil DE spThe expand EX command replaces each word in words.mlf by the corresponding pronunciation in the dictionary file dict. The IS command inserts a silence model sil at the start and end of every utterance. Finally, the delete DE command deletes all short-pause sp labels, which are not wanted in the transcription labels at this point.
A set of phone level transcriptions which include short-pauses between words, needed later in the training process, can also be created in a file called phones1.mlf by using the same procedure except that the DE command would be omitted from the edit script in order to leave the sp models intact.